data()8 Sources de données
Toute analyse statistique commence généralement par l’acquisition des données, étape cruciale qui peut s’effectuer selon diverses modalités et à partir de formats variés. Cette section propose un aperçu concis des principales méthodes d’obtention de données dans R.
8.1 Jeux de données intégrés aux packages R
De nombreux packages R incluent des jeux de données accessibles dès leur chargement. C’est notamment le cas du package de base datasets, installé et chargé automatiquement avec R.
De façon général, pour obtenir la liste complète des jeux de données disponibles dans les packages actuellement chargés, on peut taper :
Chaque ligne de la sortie contient : (i) le nom du jeu de données (par exemple AirPassengers), et (ii) une brève description (par exemple “Monthly Airline Passenger Numbers 1949–1960”). Si plusieurs packages sont chargés, la sortie est regroupée par package, avec une sous-section pour chacun.
La plupart des packages R fournissent non seulement des fonctions, mais aussi des jeux de données. Prenons l’exemple du package MASS, qui est installé automatiquement avec R (mais non chargé par défaut). Ce package contient plusieurs jeux de données, dont la liste complète peut être obtenue à l’aide de la commande suivante :
data(package = "MASS")Parmi ces jeux de données figure, par exemple, Animals. Pour y accéder, deux approches sont possibles. La première consiste à appeler require(MASS) pour charger l’ensemble du package, ce qui rend immédiatement accessibles tous les jeux de données qu’il contient, y compris Animals. La seconde approche, plus ciblée, consiste à importer uniquement le jeu de données souhaité sans charger explicitement le package, via data(Animals, package = "MASS") ou via Animals <- MASS::Animals. Cette méthode est généralement recommandée, car elle limite l’usage de la mémoire et réduit les risques de conflits de noms dans l’environnement de travail.
Une fois le jeu de données chargé, vous pouvez en consulter le contenu en tapant simplement : Animals ou en l’affichant dans l’éditeur de données de RStudio avec : View(Animals). Pour obtenir une description détaillée du jeu de données, y compris sa structure et son origine, utilisez la commande d’aide : ?MASS::Animals, ou simplement ?Animals si le package MASS a été chargé.
8.2 Fichiers externes
En pratique, la majorité des données utilisées en analyse statistique proviennent de sources externes. R offre une grande souplesse pour importer des fichiers stockés localement sur votre machine ou accessibles en ligne. Ces fichiers peuvent adopter divers formats — textes délimités (comme .txt ou .csv), JSON, Excel, etc. — chacun nécessitant des fonctions ou des packages spécifiques.
Fichiers texte
Les fichiers texte contiennent des données tabulaires (lignes x colonnes) où, dans chaque ligne, les valeurs individuelles (champs) sont séparés par un caractère spécifique (virgule, point-virgule, tabulation, etc.)
Pour illustrer l’importation de données externes dans R, nous allons utiliser le fichier Med.txt, que vous êtes invité à télécharger et enregistrer localement sur votre machine.
Voici un aperçu du contenu de ce fichier.
Subject Sex Condition Before After Change
1 F placebo 10.1 6.9 -3.2
2 F placebo 6.3 4.2 -2.1
3 M aspirin 12.4 6.3 -6.1
4 F placebo 8.1 6.1 -2
5 M aspirin 15.2 9.9 -5.3
6 F aspirin 10.9 7 -3.9
... Pour importer un tableau de données à partir d’un fichier texte, la fonction la plus polyvalente dans le R de base est read.csv(), issue du package utils (chargé automatiquement avec R). Le seul argument obligatoire de la fonction read.csv() est file, qui correspond au chemin d’accès du fichier à importer. Comme déjà mentionné, il n’est pas nécessaire de spécifier le chemin complet si le fichier se trouve dans votre répertoire de travail (working directory). Si c’est le cas, il suffit de fournir le nom. Exemple :
Med <- read.csv("Med.txt", sep = "")Les autres arguments de la fonction read.csv() doivent être adaptés selon le formatage du fichier à lire (voir ?read.csv). Dans l’exemple ci-dessus, sep = "" sert à préciser que les champs sont séparés par des espaces (par défaut sep = ",").
La fonction read.csv() peut également être utilisée pour importer un tableau de données directement depuis une source en ligne, à condition que le fichier soit accessible via une URL. Exemple :
read.csv() peut aussi être utilisée pour construire un jeu de données directement dans un script, sans passer par un fichier externe. Cela se fait grâce à l’argument text (à la place de file). Exemple :
dt <- read.csv(text = "
X Y N
Placebo Oui 239
Placebo Non 10795
Traite Oui 139
Traite Non 10898
", sep = " ")RStudio fournit une interface graphique simple pour faciliter l’import d’un fichier. Pour cela, il suffit d’aller dans le menu File > Import Dataset > From Text (base), ou via l’onglet Environment > Import Dataset > From Text (base), et indiquer l’emplacement du fichier et ces caractéristiques.
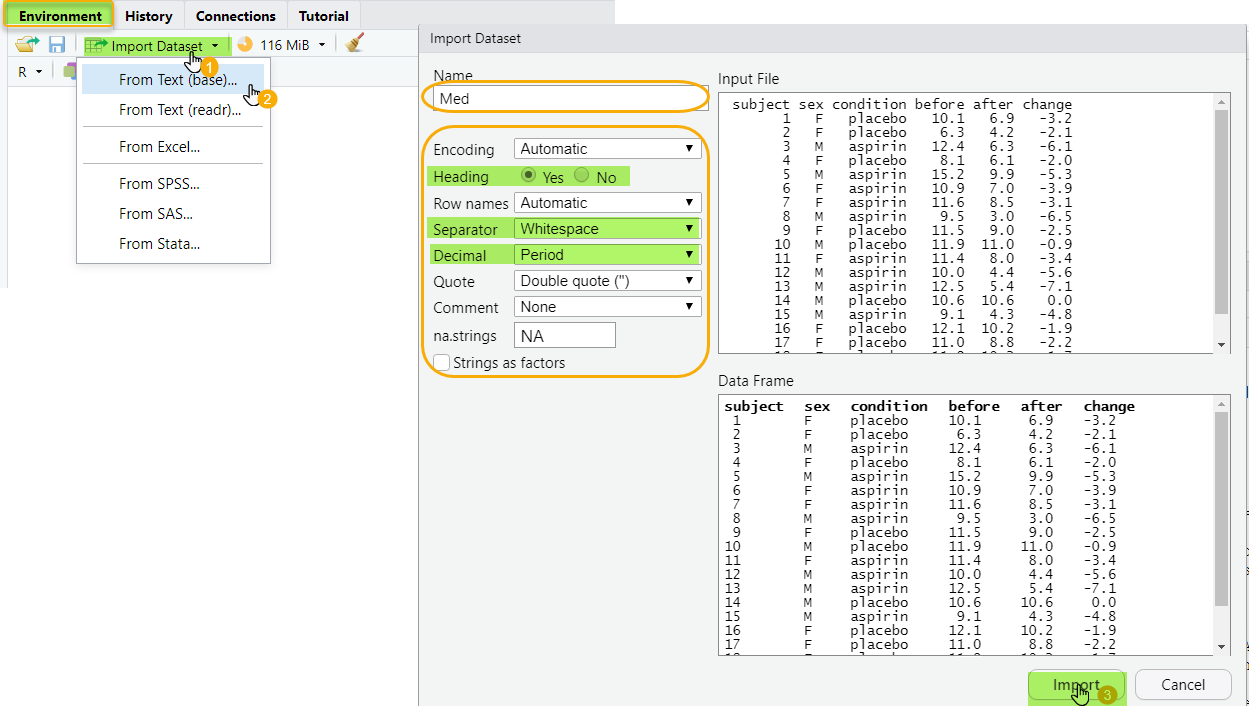
Une fois le fichier sélectionné, RStudio affiche un aperçu des données et génère automatiquement le code R correspondant à l’importation. Ce code constitue un excellent point de départ si vous souhaitez explorer les paramètres manuellement ou automatiser l’importation par la suite.
Autres moynnes d’importation de données
Plusieurs packages offrent aujourd’hui des méthodes plus rapides, plus intuitives ou mieux adaptées à des formats spécifiques comme Excel, JSON ou SPSS. Cette section présente les principales alternatives disponibles.
Le package readr du tidyverse propose les fonctions readr::read_csv() et readr::read_delim() pour importer respectivement des fichiers séparés par des virgules et des fichiers utilisant n’importe quel autre séparateur. La différence principale est que read_csv() est une version spécialisée de read_delim() avec un séparateur fixé à la virgule, tandis que read_delim() permet de spécifier librement le séparateur (par exemple ";" ou "\t" — ce dernier correspondant au caractère de tabulation). Pour les fichiers Excel, on peut utiliser la fonction readxl::read_excel() du package readxl, également associé à l’écosystème tidyverse. Ces fonctions sont généralement beaucoup plus rapides (jusqu’à dix fois) que leurs équivalents de base. RStudio offre également une interface graphique pour ces opérations via Environment > Import Dataset > .... Exemple :
Si tu veux, je peux aussi revoir l’exemple qui suit pour qu’il soit parfaitement aligné avec ce style limpide. Exemple :
readr::read_csv("https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv")Le package data.table propose une fonction appelée data.table::fread(), conçue pour lire des fichiers de données volumineux de manière très rapide, efficace et fluide. Cette fonction est capable de détecter automatiquement les types de délimiteurs, les types de colonnes, le séparateur décimal, ainsi que la présence ou non d’un en-tête. fread() permet également de contrôler précisément les données à importer grâce à des arguments comme select, drop et nrows. Exemple :
data.table::fread("https://raw.githubusercontent.com/nytimes/covid-19-data/master/us-counties.csv")Lorsque le fichier à importer ne correspond pas à un format classique (comme CSV ou Excel), il peut être utile de recourir au package rio, qui propose une fonction extrêmement polyvalente appelée rio::import(). Cette fonction est capable de détecter automatiquement le format du fichier et d’appliquer en arrière-plan la méthode d’importation la plus adaptée. Le package rio prend en charge un très grand nombre de formats de fichiers, allant des plus classiques comme .csv aux plus modernes comme .feather.
8.3 Exportation de données en R
R permet également d’exporter des données vers des fichiers texte à l’aide de fonctions dédiées, analogues à celles utilisées pour l’importation. Ces fonctions, telles que write.csv(), permettent d’enregistrer des dataframes ou objets similaires dans des formats adaptés à une réutilisation externe. Elles offrent un contrôle précis sur les séparateurs, les décimales et la présence des noms de colonnes, etc. Exemple :
write.csv(dt, file = "dt.csv", row.names = FALSE, quote = FALSE)Ce code exporte la dataframe dt dans un fichier .csv nommé “dt.csv”, enregistré dans le répertoire de travail. Les arguments row.names = FALSE et quote = FALSE indiquent que les noms de lignes ne sont pas inclus et que les chaînes de caractères ne sont pas entourées de guillemets, contrairement au comportement par défaut.
Dans tidyverse, des fonctions comme readr::write_csv() propose des alternatives plus rapides et plus lisibles aux fonctions de base. De même, le package data.table dispose de data.table::fwrite(), une fonction optimisée pour l’écriture de fichiers volumineux.
Enfin, le package rio propose une approche unifiée avec la fonction rio::export(), qui détecte automatiquement le format souhaité à partir de l’extension fourni comme argument.