x <- 12
# ou
x = 122 Concepts de base
Dans ce chapitre, nous vous présentons quelques notions fondamentales et indispensables pour vous familiariser avec le langage de programmation R, et pour pouvoir, par la suite, travailler de manière pertinente.
2.1 Stocker une valeur dans un objet
Pour réutiliser un objet en R, il est nécessaire de le stocker au préalable. Cette opération s’effectue à l’aide de l’opérateur d’assignation = ou <-. Les deux opérateurs remplissent la même fonction et peuvent être employés de manière interchangeable dans la plupart des situations courantes. Cependant, par convention, l’opérateur <- est généralement préféré dans la communauté R, notamment dans les scripts et documents officiels.
Cette ligne de code déclare un objet nommé x et lui assigne la valeur 12. L’exécution de ce code n’entraîne aucun résultat visible : rien n’est affiché à la console, mais l’objet x est bien créé dans l’environnement de travail.
Pour afficher le contenu d’un objet en R, il suffit de taper son nom dans la console, puis d’appuyer sur Enter. Il est intéressant de noter que, lorsque l’on saisit simplement le nom d’un objet à la ligne de commande pour en afficher le contenu, c’est en réalité la fonction print() qui est automatiquement appelée en arrière-plan :
print(x)[1] 12Une fonction similaire à print() est cat(). Elle concatène ses arguments et les affiche sous forme de chaîne de caractères, sans guillemets :
cat("La valeur de x est", x)La valeur de x est 12Une fois l’objet x sauvegardé, il est possible de le manipuler à l’aide de toutes sortes de fonctions ou d’opérations, sans pour autant modifier sa valeur. Par exemple, on peut calculer sa racine carrée ou l’utiliser dans une opération arithmétique :
x^2
sqrt(x)
x[1] 144
[1] 3.464102
[1] 12Pour modifier l’objet x, il suffit de lui attribuer une nouvelle valeur
x <- 1
x <- x + 1
x[1] 2Vous pouvez également affecter le contenu d’une variable à une autre, càd copier la valeur de la première dans la seconde :
y <- x
y[1] 2Après cette opération, l’objet y contient la même valeur que x, mais il s’agit de deux objets distincts : modifier l’un n’affectera pas l’autre.
x <- 102
y[1] 2Voici d’autres exemple de manipulation d’objets en R (code suivi de sa sortie, côte à côte) :
x - y
x * y
x / y
z <- x^y
z
[1] 100
[1] 204
[1] 51
[1] 104042.2 Les fonctions prédéfinies
Les fonctions représentent une composante fondamentale du langage R. Plusieurs d’entre elles, telles que sqrt(), log() ou encore print(), ont déjà été utilisées dans les sections précédentes. La présente section examine de manière systématique les règles d’appel, la gestion des arguments et l’accès à l’aide des fonctions en R.
Une fonction se définit par les éléments suivants : (i) un nom, (ii) une liste d’arguments, éventuellement assortis de valeurs par défaut, (iii) un corps, càd l’ensemble des instructions qui en déterminent le comportement.
Voici, à titre d’exemple, à quoi ressemble la définition d’une fonction (simple) en R :
maFunc <- function(x, const = 1) {
s <- x + const
return(s)
}Cela code définit la fonction nommée maFunc qui prend deux arguments : x un argument obligatoire, et const un argument optionnel avec une valeur par défaut de 1. Le corps d’une fonction correspond au bloc de code situé entre les accolades {}. C’est dans cette partie que sont définies les instructions que la fonction doit effectuer pour accomplir sa tâche. Dans le cas présent, la fonction maFunc() calcule la somme de x et const, puis stocke le résultat dans la variable s, laquelle est ensuite retournée comme valeur de sortie.
La conception de fonctions personnalisées ne sera pas approfondie dans cette partie. Pour l’heure, nous nous concentrerons exclusivement sur les fonctions prédéfinies disponibles dans R. En effet, ce dernier est livré avec des milliers de fonctions prêtes à l’emploi, couvrant un large éventail de tâches : manipulation de données, calculs statistiques complexes, visualisation graphique, et bien plus encore. Apprendre à utiliser ces fonctions est l’objectif recherché ici.
De manière générale, l’appel à une fonction s’effectue comme suit :
nom_fonc(arg.1 = val.1, arg.2 = val.2)où val.1, val.2, etc., désignent les valeurs attribuées aux arguments arg.1, arg.2, etc. Lorsqu’un argument est transmis sous la forme “nom_arg = valeur”, on parle d’argument nommé. Il s’agit de la méthode recommandée, bien qu’elle ne soit pas la seule, pour spécifier les arguments d’une fonction; ce point sera approfondi ultérieurement. Exemple :
maFunc(x = 2) # Calculer sans sauvegarder le résultat (const = 1)
y <- maFunc(x = 2, const = 3) # Calculer et sauvegarder le résultat dans y
y # Afficher le contenu de y[1] 3
[1] 5L’exécution d’une fonction en R revient à exécuter le code contenu dans son corps, en remplaçant les arguments formels par les valeurs fournies par l’utilisateur (ici, on calcule x + const en remplaçant x par 2 et const par 1 dans le premier cas, et par 3 dans le second.).
Obtenir de l’aide
Pour connaître l’ensemble des arguments d’une fonction prédéfinie et obtenir de l’aide sur son utilisation ainsi que sur le type de résultat retourné, il convient d’utiliser l’une des commandes suivantes dans la console, en remplaçant nom_fonc par le nom de la fonction concernée :
help(nom_fonc)
# ou
?nom_foncIllustrons ce point avec la fonction seq(), qui permet de construire des séquences de nombres. Saisissez ?seq puis Enter, une page d’aide (en anglais) s’affichera dans l’onglet Help de RStudio. Cette page fournit notamment :
- Titre : suivi d’une brève description de la fonction.
- Usage : présente la syntaxe de la fonction, la liste des arguments, leur ordre et leurs valeurs par défaut. Les arguments suivis du symbole
=possèdent une valeur par défaut ; il n’est donc pas nécessaire de les spécifier lors de l’appel, auquel cas la valeur par défaut sera utilisée. Tous les autres arguments doivent obligatoirement être renseignés. Certaines fonctions peuvent être utilisées de plusieurs manières. Dans ce cas, la section Usage de la documentation présente les différentes syntaxes possibles. - Arguments : fournit une description détaillée de chaque argument.
- Details : apporte des précisions complémentaires sur l’utilisation de la fonction.
- Value : décrit la nature du résultat retourné par la fonction.
- Examples : propose des exemples d’utilisation courante, souvent particulièrement utiles.
Toute fonction R, destinée à la communauté, doit être accompagnée d’une documentation d’aide. Aujourd’hui, cette exigence est généralement complétée par une documentation en ligne détaillée. Il est vivement recommandé de consulter systématiquement la fiche d’aide de chaque nouvelle fonction rencontrée avant de l’utiliser.
Les arguments et leurs valeurs
Comme indiqué ci-dessus, exécuter une fonction consiste à exécuter son corps en remplaçant ces arguments par par les valeurs fournies. La manière dont les arguments sont associés aux valeurs est un élément fondamental du langage R.
Pour mieux comprendre ce mécanisme, examinons de plus près l’aide de la fonction seq(). Dans la section Usage, au paragraphe “## Default S3 method:”, on trouve :
seq(from = 1, to = 1, by = ((to - from) / (length.out - 1)), length.out = NULL, along.with = NULL, ...)Cela indique que la fonction seq() accepte les arguments suivants : from, to, by, length.out, along.with, ainsi qu’un argument spécial noté ... qui permet de transmettre des arguments supplémentaires. L’usage de ce dernier sera détaillé ultérieurement.
On constate que tous ces arguments possèdent déjà une valeur par défaut : from = 1, to = 1, etc. Ainsi, il est possible d’appeler la fonction seq() sans fournir aucun argument — même si, dans ce cas, cela n’a aucune utilité pratique :
seq() # est équivalent à : seq(from = 1, to = 1)[1] 1Voici des exemples d’appel plus élaborés.
seq(from = 5, to = 10)[1] 5 6 7 8 9 10seq(from = 5, to = 10, by = 0.5) [1] 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0Lors de l’appel d’une fonction, il n’est pas nécessaire de nommer tous les arguments. Exemple :
seq(from = 5, 10) # Le premier argument est nommé, le second ne l’est pas.[1] 5 6 7 8 9 10Les arguments nommés ont priorité et sont associés en premier lieu. Les arguments non nommés sont associés par position, càd selon l’ordre prédéfini indiqué dans la définition de la fonction entre les parenthèses (). Pour la fonction seq(), par exemple, l’ordre prédéfini des arguments est le suivant : (1) from, (2) to, (3) by, etc.. Ainsi, un appel comme : seq(1, 10, 2) sera interprété comme : seq(from = 1, to = 10, by = 2).
En pratique, on peut distinguer trois situations selon la manière dont les arguments sont fournis :
- Tous les arguments sont nommés : Dans ce cas, l’ordre d’appel n’a aucune importance. Chaque valeur est associée explicitement à son argument. Ainsi, les commandes
seq(from = 1, to = 10, by = 2)etseq(by = 2, to = 10, from = 1)sont équivalentes. - Aucun argument n’est nommé : Les arguments sont alors associés par position, selon l’ordre prédéfini dans la définition de la fonction.
- Cas mixte : arguments nommés et non nommés : Lorsque des arguments nommés et non nommés sont mélangés, les arguments nommés sont associés en priorité. Les arguments non nommés sont ensuite associés par position, en tenant compte des arguments déjà affectés.
Voici un exemple pour ce dernier cas :
- 1
-
R associe d’abord les arguments nommés (
by,to), puis affecte la valeur 1 àfrom. - 2
-
R associe d’abord les arguments nommés (
by,from), puis affecte la valeur 10 àto.
[1] 1 3 5 7 9
[1] 1 3 5 7 9Pour éviter toute confusion, il est fortement conseillé de nommer tous les arguments, sauf peut-être le premier, surtout lorsque la fonction accepte de nombreux paramètres ou que leur ordre n’est pas évident.
Notez que les noms formels des arguments peuvent être abrégés tant que l’abréviation n’est pas ambiguë. Cela signifie que vous pouvez utiliser une partie du nom d’un argument, à condition qu’elle corresponde de façon unique à un seul argument de la fonction. Exemple :
seq(f = 1, t = 10, b = 2)[1] 1 3 5 7 9Dans cet appel, f est traduit en from puisque c’est le seul et unique argument de seq() qui commence avec la lettre “f”. De même pour t et b.
Notez aussi que l’on peut passer directement des objets en arguments, simplement en écrivant leur nom. Lors de l’exécution de la fonction, R remplacera automatiquement ces noms par la valeur des objets correspondants. Exemple :
a <- 1
b <- 20
seq(from = a, to = b, by = 2) [1] 1 3 5 7 9 11 13 15 17 19Dans cet exemple, les objets a et b sont utilisés comme arguments pour la fonction seq(). Lors de l’exécution, R remplace a par 1 et b par 20, ce qui revient à exécuter : seq(from = 1, to = 20, by = 2).
Quelques remqrues
Argument vs objet global
Attention à ne pas confondre un argument d’une fonction avec un objet de l’environnement global. Un argument est simplement une variable (ou symbole) interne à la fonction, utilisée uniquement pendant l’exécution de celle-ci. En revanche, un objet de l’environnement global est une structure accessible partout dans la session R, indépendante de toute fonction. Certaines situations peuvent prêter à confusion, voire induire en erreur, notamment lorsque le nom d’un objet global est identique à celui d’un argument. Voici un exemple :
- 1
-
Dans “
by = by”, lebyà gauche de “=” fait réference à l’argument de la fonctionseq()alors que le secondby, à droite de “=”, fait référence à l’objet global dont la valeur est 5. Anisi ce code est équivalent àseq(from = 1, to = 20, by = 5). - 2
-
Lorsque vous écrivez simplement
bysans le signe “=”, il s’agit d’un objet global dont la valeur est ici transmise au premier argument non nommé de la fonction, icifrom; ainsi, ce code est équivalent àseq(from = 5, to = 20, by = 1).
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[1] 1 6 11 16
[1] 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20Fonctions génériques
De nombreuses fonctions en R agissent comme des interfaces qui délèguent l’exécution à d’autres fonctions. On appelle cela des fonctions génériques. C’est le cas, par exemple, de la fonction seq().
Lorsqu’une fonction générique est appelée, elle fait elle-même appel à d’autres fonctions spécialisées (appelées méthodes). Le choix de la fonction appropriée à exécuter dépend de la classe ou de la nature des arguments spécifiés. L’inventaire des méthodes associées à une fonction générique peut être consulté à l’aide de la fonction methods() :
methods(seq)[1] seq.Date seq.default seq.POSIXt
see '?methods' for accessing help and source codeCette sortie présente les différentes méthodes sous la nomenclature seq.<Classe>, où <Classe> représente le type d’objet supporté. Ainsi lorsque seq() est appelée avec un objet de classe Date, par exemple, c’est automatiquement seq.Date() qui est exécutée.
seq(as.Date("2000/1/1"), as.Date("2003/1/1"), by = "quarter") [1] "2000-01-01" "2000-04-01" "2000-07-01" "2000-10-01" "2001-01-01"
[6] "2001-04-01" "2001-07-01" "2001-10-01" "2002-01-01" "2002-04-01"
[11] "2002-07-01" "2002-10-01" "2003-01-01"La méthode seq.default() constitue le fallback (solution de secours) : elle est invoquée lorsqu’aucune méthode spécifique n’est définie pour la classe de l’objet fourni en argument
Inspecter une fonction vs. l’exécuter
Lorsque l’on tape le nom d’une fonction en R avec des parenthèses, comme seq(), on demande à R d’exécuter cette fonction. Si celle‑ci requiert des arguments obligatoires, leur absence entraîne une erreur. Exemple :
maFunc()Error in maFunc(): argument "x" is missing, with no defaultLorsque l’on tape simplement le nom d’une fonction en R, sans parenthèses, deux situations peuvent se présenter :
R affiche la définition de la fonction, càd son code :
maFuncfunction (x, const = 1) { s <- x + const return(s) } <bytecode: 0x0000026c68d8fc10>Au lieu du code complet, R renvoie une description courte
seqfunction (...) UseMethod("seq") <bytecode: 0x0000026c6bc9c1c8> <environment: namespace:base>indiquant, entre autres, que le nom correspond bien à une fonction
(function (...)). Lorsqu’il s’agit d’une fonction générique, on voit apparaître la ligneUseMethod("nom_fonc"). Dans ce cas, on peut afficher le code source en tapant le nom de la méthode souhaité (voir la section précédente); Exemple:seq.default.
Toutes les fonctions n’affichent pas leur code source lorsqu’on tape simplement leur nom. Pour certaines, notamment les fonctions primitives (comme sum), on ne voit pas le code R mais une référence du type .Primitive("nom_fonc"). Cela signifie que leur implémentation est écrite directement en langage C et intégrée à R. De même, d’autres fonctions utilisent des appels internes (.Internal, .Call) qui renvoient vers du code C. Dans ces cas, le code source n’est pas directement visible mais il est possible de le consulter dans des fichiers sources sur CRAN; voir Section 2.4.
Formule en R
De nombreuses fonctions R acceptent deux types de syntaxe :
- la syntaxe positionnelle classique :
fonction(arg1 = varX, arg1 = varY)
- la syntaxe avec formule :
fonction(formule = varY ~ varX),
où varX et varY sont les noms de variables (objets) à mettre en relation. ~ est l’opérateur de formule.
La fonction plot(), que nous verrons plus en détail plus loin, en est un bon exemple :
varX <- 1
varY <- 2
plot(varY ~ varX)
## # Ou, de manière équivalente :
## plot(x = varX, y = varY)
Une formule est une expression symbolique, qui utilise ~, pour séparer la variable réponse (à gauche de ~) de la ou les variables explicatives (à droite de ~). varY ~ varX peut se lire comme : décrire varY en fonction de varX.
Notez que certaines fonctions en R n’acceptent qu’une formule comme argument principal. Un bon exemple est la fonction xtabs(), que nous verrons plus loin.
L’argument spécial ...
Certaines fonctions R acceptent un argument spécial noté ... (appelé ellipsis ou dot-dot-dot). Cet argument offre une grande flexibilité et peut servir à deux usages principaux :
Accepter un nombre variable d’arguments : Cela permet de passer autant d’éléments que souhaité à une fonction. C’est le cas, par exemple, de la fonction
cat():cat("Salut", "tout", "le monde", "!")Salut tout le monde !Transmettre des arguments à des fonctions internes :
...permet de colecter et de transmetre des arguments directement à une ou plusieurs fonctions internes appelées au sein du corps de la fonction principale. Voici un exemple :maFunc <- function(x, const = 1, ...) { s <- x + const cat(..., s) }maFunc(x = 1, const = 1, "Le", "résultat", "est")Le résultat est 2Ici,
x = 1etconst = 1, doncs = 2. Les chaînes “Le”, “résultat” et “est” sont passées via l’argument...à la fonctioncat(..., s), ce qui revient àcat("Le", "résultat", "est", 2), d’où la sortie.
2.3 Enchaîner les commandes avec |>
Depuis sa version 4.1.0, sortie en mai 2021, R a introduit l’opérateur |>, appelé “pipe”, qui permet de structurer le code de manière séquentielle et plus lisible.
Le principe de cet opérateur est de passer l’élément situé à sa gauche comme premier argument de la fonction située à sa droite. Ainsi, pour une fonction fun et un objet a quelconques, l’écriture classique fun(a) peut être remplacée par a |> fun(). Ceci peut se lire comme “prend l’objet a et y appliquer la fonction fun”. Exemple:
12 |> sqrt() # càd sqrt(12)[1] 3.464102Cette façon d’écrire du code R est surtout utile lorsqu’il s’agit d’enchaîner plusieurs opérations. Ainsi, au lieu d’écrire exp(sqrt(log(12, base = 10))), nous pouvons écrire
112 |> log(base = 10) |> sqrt() |> exp()- 1
- Prendre 12, puis calculer son logarithme à base 10, puis calculer la racine carrée, puis calculer l’exponentielle.
Pour faciliter davantage la lecture du code, il est recommandé de faire un retour à la ligne après chaque |>. Comme ceci
12 |>
log(base = 10) |>
sqrt() |>
exp()Pour utiliser correctement cet opérateur, gardez en tête les deux règles suivantes :
- Les parenthèses
()à côté du nom de chaque fonction sont obligatoires, et |>fait toujours référence au premier argument de la fonction située à sa droite. Autrement dit, pour une fonctionfun(arg1, arg2, arg3)de trois argumentsarg1,arg2etarg3, par exemple, l’écriture1 |> fun(2, 3)se traduit parfun(arg1 = 1, arg2 = 2, arg3 = 3).
Si vous voulez faire référence à un argument autre que le premier, vous devez alors (i) le nommer, et (ii) le spécifier à l’aide l’opérateur _, appelé “placeholder”. Par exemple, l’écriture
10 |> log(22, base = _)se traduit par log(22, base = 10). Si vous oubliez de nommer l’argument concerné et écrivez par exemple 10 |> log(22, _), R renvoie une erreur de type
Error in ...
pipe placeholder can only be used as a named argumentAttention aussi à ne pas oublier l’opérateur _, R peut alors interpréter votre code de manière inattendue. Exemple :
10 |> log(22, base = )[1] 0.7449219Dans ce cas, l’argument base = est incomplet, et R l’ignore. Il interprète alors l’expression comme : log(10, 22) càd log(x = 10, base = 22).
Il faut également faire attention lorsque |> est utilisé avec d’autres opérateurs, comme par exemple avec des opérateurs arithmétiques. Voici un exemple :
10 + 2 / 2 |> sum(3)[1] 10.4Cette sortie s’explique par le fait que l’opérateur |> a une priorité plus élevée que les opérateurs arithmétiques +, - *, et /, ce qui signifie que le pipe est évalué avant ces opérations. Ainsi, le code ci-dessus se traduit en réalité par 10 + 2/sum(2, 3). L’usage de parenthèses ou d’accolades permet de contrôler explicitement l’ordre d’exécution. Exemple :
{ 10 + 2 / 2 } |> sum(3)[1] 14En RStudio, pour insérer |> facilement, vous pouvez utiliser le raccourci clavier Ctrl + Maj + M. Pour que ce raccourci fonctionne, assurez-vous d’avoir coché l’option “Use native pipe operator” dans le menu Tools -> Global Options -> Code -> Editing.
Par la suite nous aurons recours à cet opérateur uniquement lorsque cela sera jugé utile pour la lisibilité du code.
2.4 Extensions ou packages en R
L’installation par défaut du logiciel R comprend le cœur du programme ainsi qu’un ensemble de fonctions de base. Ce noyau peut être aisément enrichi par l’ajout d’extensions, appelées packages en anglais. Ces packages constitue l’un des principaux atouts de R.
En effet, tout utilisateur peut participer au développement du langage en créant son propre package, apportant ainsi de nouvelles fonctionnalités. Ces extensions sont hébergées sur des serveurs en ligne, ce qui permet à la communauté R de les installer, les utiliser et les partager de manière libre et gratuite.
Le principal dépôt officiel des packages R, pour l’installation et la mise à jour, est CRAN. Cependant, d’autres dépôts existent, tels que : Bioconductor et GitHub. Ce dernier permet aux développeurs de partager librement leurs packages, souvent en cours de développement.
Lors du démarrage d’une session R, certains packages sont automatiquement chargés. Pour consulter cette liste, on peut utiliser la commande suivante :
options()$defaultPackages[1] "datasets" "utils" "grDevices" "graphics" "stats" "methods" Si un package que vous souhaitez utiliser ne figure pas dans cette liste, il est nécessaire de l’installer au préalable sur votre machine. Pour installer un package depuis le dépôt officiel CRAN, deux méthodes sont possibles :
- Utiliser la commande
install.packages("nom_pack")dans la console R, oùnom_packreprésente le nom du package que vous souhaitez charger; - Utiliser le menu de RStudio : dans le quadrant en bas à droite, cliquez sur l’onglet
Packages, puis surInstall, et renseignez le nom du package dans le champ prévu à cet effet.
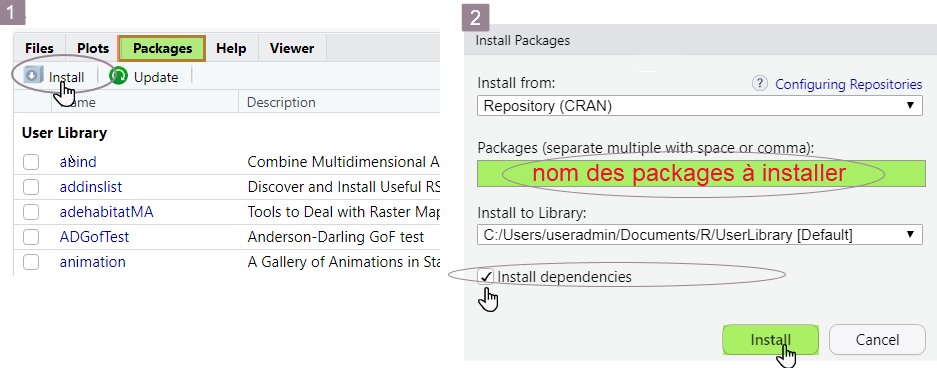
R procède alors au téléchargement des fichiers nécessaires sur le disque dur de votre ordinateur. Ces fichiers sont enregistrés dans le répertoire spécifié par le champ Install to Library (voir illustration ci-dessus).
À titre d’exemple, il est proposé d’installer le package sudokuAlt en suivant la procédure décrite précédemment. Ce package permet de jouer au Sudoku directement dans R ! Une fois l’installation terminée, un message de confirmation s’affiche dans la Console, indiquant que le package a bien été installé.
La liste complète des packages installés sur votre machine est accessible via l’onglet Packages.
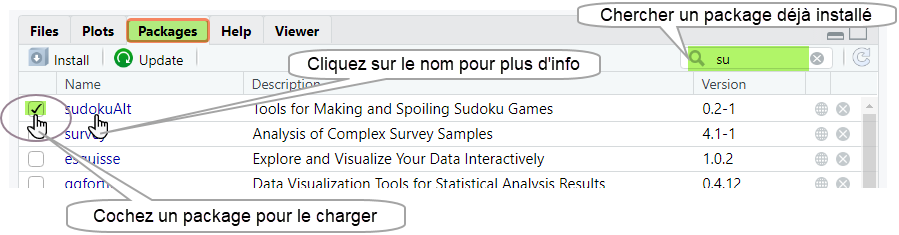
Pour obtenir des informations détaillées sur un package déjà installé, il suffit de cliquer sur son nom dans cette liste.
Pour pouvoir utiliser un package dans R, il est nécessaire de le charger, càd de l’appeler explicitement dans la session en cours. Cela peut être réalisé à l’aide de l’une des deux fonctions suivantes :
library(nom_pack)
# ou
require(nom_pack)Par exemple, pour charger le package sudokuAlt, il suffit de taper : library(sudokuAlt) ou library("sudokuAlt"). Il est également possible de charger un package en cochant son nom dans la liste des packages disponibles, accessible via l’onglet Packages de RStudio comme illustré dans la capture d’écran ci-dessus.
Une fois le package sudokuAlt installé et chargé, il devient possible de commencer à l’utiliser. À titre d’exemple, vous pouvez lancer une partie de Sudoku en tapant la commande suivante dans la console :
g <- makeGame() |> plot() # lancer un jeux
g |> solve() |> plot() # visualiser sa solutionPour consulter la documentation d’une fonction spécifique d’un package, vous pouvez utiliser le symbole ? suivi du nom de la fonction. Par exemple : ?makeGame. Cela affiche la fiche d’aide de la fonction makeGame. Dans le titre de cette fiche, vous remarquerez que le nom de la fonction est suivi du nom du package entre accolades, ce qui indique son appartenance au package sudokuAlt.
Pour décharger un package, càd le retirer de la session active, vous pouvez utiliser la commande detach("package:nom_pack"). Exemple: detach("package:sudokuAlt"). Alternativement, il est possible d’effectuer cette opération via RStudio : il suffit de décocher le nom du package dans la liste affichée dans l’onglet Packages. Une fois cette action accomplie, toutes les fonctionnalités du package deviennent inaccessibles. Il est alors nécessaire de le recharger si l’on souhaite à nouveau utiliser ses fonctions.
Cela dit, il est possible d’utiliser une fonction issue d’un package sans avoir à le charger entièrement. Pour cela, on utilise l’opérateur ::, selon la syntaxe suivante nom_pack::nom_fonc(). Par exemple, pour accéder directement à la fonction makeGame() du package sudokuAlt, on peut écrire :
sudokuAlt::makeGame()Cette méthode est particulièrement utile lorsque le package en question est volumineux et que l’on souhaite accéder uniquement à certaines de ses fonctionnalités spécifiques, sans le charger entièrement dans la session. Cela permet de limiter l’utilisation des ressources mémoire et d’optimiser les performances.
Un autre avantages de la syntaxe nom_pack::nom_fonc() est qu’elle permet d’éviter les conflits potentiels entre fonctions portant le même nom dans différents packages. En effet, dans R, il est possible que plusieurs packages contiennent des fonctions ayant le même nom, ce qui peut entraîner des conflits. Lorsque plusieurs packages sont chargés simultanément, R utilise par défaut la fonction provenant du dernier package chargé, ce qui peut entraîner des résultats inattendus. Cela peut être éviter avec la syntaxe nom_pack::nom_fonc() qui, contrairement à la syntaxe simple : nom_fonc(), ne laisse aucun ambiguïté quant à la provenance de la fonction à utiliser.
Il est important de bien distinguer les deux étapes fondamentales liées à l’utilisation d’un package dans R :
- Installation : cette opération consiste à télécharger le package depuis Internet et à l’enregistrer localement dans un dossier du disque dur. Cette opération ne doit être effectuée qu’une seule fois.
- Chargement : cette étape consiste à lire le dossier du package installé et à le mettre à disposition de R pour la session en cours. Cette opération doit être répétée à chaque début de session si l’on souhaite utiliser le package.
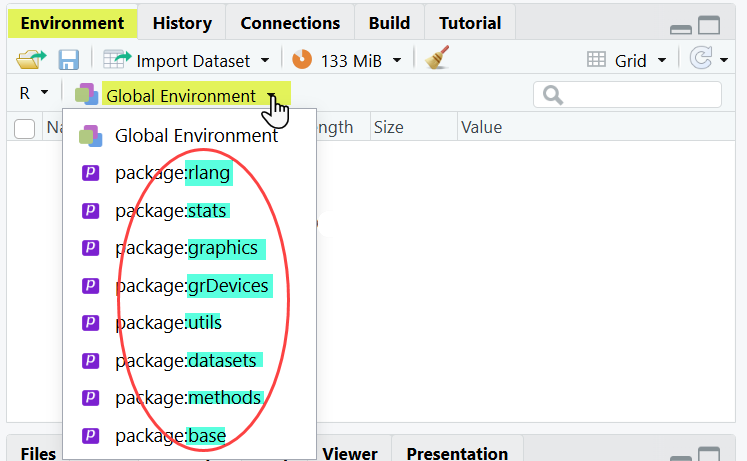
Pour savoir quels packages sont actuellement chargés dans votre session R, vous pouvez utiliser la commande print(.packages()). Alternativement, vous pouvez accéder à cette information via RStudio dans l’onglet Environnement en cliquant sur la flèche à côté de Global Environment.
2.5 Espace utilisateur et environnements
Tout objet en R est conservé dans une structure particulière appelée environnement (environment). Un environnement peut être défini comme un espace de stockage virtuel qui associe des noms (symboles) à des valeurs. On peut comparer un environnement à un dossier sur un ordinateur : le dossier représente l’environnement, les fichiers qu’il contient correspondent aux objets stockés, et le nom de chaque fichier joue le rôle d’identifiant unique permettant d’accéder à son contenu.
Chaque fois qu’une nouvelle session R est lancée, un environnement vierge appelé Global Environment (ou .GlobalEnv) est automatiquement créé. Cet environnement constitue le point de départ de toute session : par défaut, c’est en lui que seront stockés tous les objets (variables, fonctions, données, etc.) créés par l’utilisateur, on peut donc dire que c’est l’espace utilisateur par défaut.
La fonction ls() permet d’afficher la liste de tous les objets actuellement disponibles dans .GlobalEnv. Voici, à titre d’exemple, la liste des objets disponibles pour ma session en cours :
ls()[1] "a" "b" "by" "maFunc" "varX" "varY" "x" "y"
[9] "z" Vous pouvez également consulter cette liste dans l’onglet Environment, situé dans le quadrant supérieur droit de RStudio. Cet onglet offre une vue interactive de l’espace de travail : il affiche les objets actuellement disponibles, leur type (vecteur, fonction, data frame, etc.) ainsi qu’un aperçu de leur contenu. Vous pouvez modifier la façon dont les objets sont affichés en cliquant sur l’icône en haut à droite. Il est conseillé d’utiliser le mode Grid, bien plus pratique que le mode List.
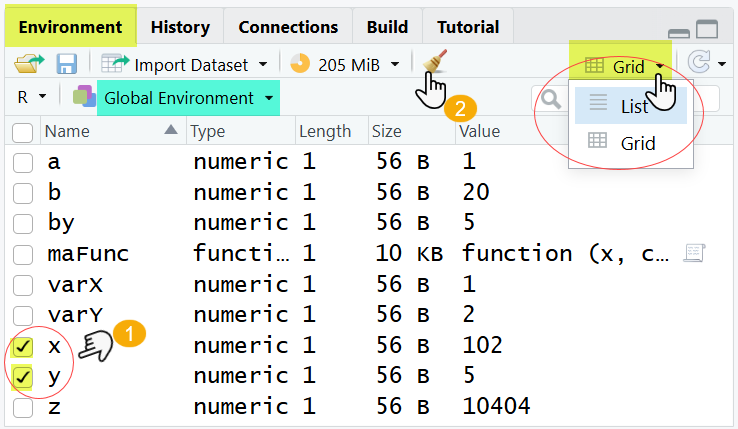
Pour supprimer un ou plusieurs objets, on utilise la fonction rm().
rm(x, y)Vous pouvez également utiliser l’onglet Environment pour sélectionner un ou plusieurs objets en cochant simplement la petite case située devant chacun d’eux. Ensuite, vous pourrez le(s) supprimer en appuyant sur l’icône en forme de balai, comme indiqué dans la capture ci-dessus.
Si vous tapez x, après l’avoir supprimé, vous obtenez un message d’erreur, puisque l’objet x n’existe plus.
xError: object 'x' not foundLe contenu de .GlobalEnv peut être supprimé en exécutant la commande rm(list = ls()). Aussi, par défaut, la fermeture d’une session entraîne la suppression de tous les objets. Il demeure toutefois possible de mettre en place une sauvegarde de l’environnement global, qu’elle soit automatique ou manuelle. Nous reviendrons sur ce point plus tard.
.GlobalEnv n’est pas le seul environnement en R. C’est, par défaut, l’endroit où vous créez et stockez vos propres objets, mais R doit également savoir gérer d’autres objets (variables, fonctions, données, etc.) préexistantes ou chargés avec les packages. En effet, dès qu’un package est chargé, un nouveau environnement est crée. Ce dernier agit comme un répertoire contenant toutes les objets que ce package met à disposition. La fonction find() permet de savoir dans quel(s) environnement(s) un objet est défini. Exemple :
find("x")
find("z")
find("pi")character(0)
[1] ".GlobalEnv"
[1] "package:base"Dans la sortie ci-dessus, package:base signifie que l’objet pi est stocké dans l’environnement du package base. Ce dernier est automatiquement chargé en premeir au lancement de R et regroupe les fonctions fondamentales du langage. L’objet z se trouve, pour sa part, stocké dans l’environnement .GlobalEnv. character(0) veut dire que que R n’a trouvé aucun objet nommé x dans les environnements actuellement accessibles (ni dans .GlobalEnv, ni dans les packages chargés).
Lorsqu’on appelle un objet par son nom, R suit un ordre précis pour le localiser et l’afficher : Il commence par chercher dans l’environnement .GlobalEnv. Si l’objet n’y est pas trouvé, la recherche se poursuit dans les environnements des packages attachés, en respectant l’ordre dans lequel ceux‑ci ont été chargés au cours de la session. Cette hiérarchie de recherche peut être consultée à l’aide de la fonction search() (ou via le le menue Environment; voir Figure 2.1) :
search()[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base" Le premier élément de cette liste est toujours .GlobalEnv, suivi des environnements des packages chargés au cours de la session, disposés dans l’ordre de leur chargement. Le dernier élément correspond systématiquement à package:base. Dès que R identifie un objet portant le nom recherché, la recherche s’interrompt et cet objet est utilisé. Si aucun objet de ce nom n’existe dans cette liste, R renvoie une erreur signalant que l’objet est introuvable.
Pour comprendre ce fonctionnement de R, considérons l’exemple suivant où l’on crée un nouveau objet nomé pi :
pi <- "A"
find("pi")[1] ".GlobalEnv" "package:base"On voit bien que R reconnaît l’existence de deux objets portant le même nom, pi, mais enregistrés dans des environnements distincts : l’un dans .GlobalEnv et l’autre dans package:base. Lorsqu’on évoque pi :
pi[1] "A"C’est l’objet pi défini dans .GlobalEnv qui est renvoyé, car R commence toujours sa recherche par cet environnement, placé en première position dans la liste des environnements. On peut néanmoins accéder à l’objet pi défini dans package:base en utilisant l’opérateur :: :
base::pi[1] 3.141593Maintenant, si l’objet pi est supprimé, le comportement de R change :
rm(pi)
pi[1] 3.141593Dans ce cas, l’appel à pi ne renvoie plus la valeur définie dans .GlobalEnv, puisqu’elle a été effacée. R poursuit alors sa recherche dans les autres environnements et trouve le pi fourni par package:base. C’est donc cette définition qui est affichée.
À noter que chaque package chargé au cours d’une session est inséré immédiatement après .GlobalEnv dans la liste des environnements. De ce fait, le dernier package ajouté prend la priorité sur ceux qui l’ont précédé lorsqu’un même nom d’objet est présent dans plusieurs packages. Exemple :
require(MASS)
search() [1] ".GlobalEnv" "package:MASS" "package:stats"
[4] "package:graphics" "package:grDevices" "package:utils"
[7] "package:datasets" "package:methods" "Autoloads"
[10] "package:base" Lorsqu’un conflit de noms survient, R génère un message dans la console précisant les packages impliqués ainsi que les objets masqués.
2.6 Répertoire de travail
R doit fréquemment lire ou écrire des fichiers externes, par exemple pour charger des données à analyser ou pour sauvegarder un objet, un résultat ou un graphique. Afin de simplifier ce type de tâches, le logiciel définit un dossier par défaut dans lequel il suppose que se trouvent les fichiers à lire et dans lequel il enregistre les fichiers à écrire. Ce dossier est appelé répertoire de travail (working directory, en anglais).
Autrement dit, lorsqu’un nom de fichier est fourni à R pour une opération de lecture ou d’écriture sans indication explicite de son emplacement (chemin d’accès), le logiciel considère que ce fichier se trouve dans le répertoire de travail. Si tel n’est pas le cas, l’exécution du code est interrompue et un message d’erreur est renvoyé.
Pour connaître le working directory de la session en cours, on utilise la fonction getwd(). Cette fonction ne prend aucun argument. Pour l’utiliser, il suffit de taper
getwd()R renvoie alors, sous forme de chaîne de caractères, le chemin du dossier actuellement défini comme working directory. Dans RStudio, le nom du working directory est affiché en gris dans le quadrant inférieur gauche, à droite de l’onglet Console.

Par défaut, le working directory correspond au dossier personnel de l’utilisateur sur la machine. Il est représenté par le symbole ~. L’emplacement précis de ce dossier dépend du système d’exploitation et peut être affiché à l’aide de la commande Sys.getenv("HOME").
En cliquant sur la petite icône en forme de flèche située à côté du nom du working directory, le contenu de ce dossier s’affiche dans le coin inférieur droit de RStudio, dans le volet Files.
Le working directory peut être modifié à l’aide de la fonction setwd(), ou plus simplement via le menu Session > Set Working Directory > Choose Directory. Une fenêtre s’ouvre alors, permettant de naviguer jusqu’au dossier que l’on souhaite définir comme nouveau working directory. Il suffit ensuite de valider en cliquant sur Open.
Pour illustrer ce concept, enregistrons les objets x, y et z suivant dans un fichier.
x <- 27
y <- 2
z <- x^yL’enregistrement s’effectue à l’aide de la fonction save(). Celle‑ci prend en argument la liste des objets à sauvegarder, suivie de l’argument file qui précise le nom du fichier de sortie. Les fichiers créés avec la fonction save() portent généralement l’extension .Rda (ou .RData), qui indique qu’il s’agit d’objets R sauvegardés.
save(x, y, z, file = "xyz.Rda")Le fichier “xyz.Rda” est alors créé dans le working directory. Il est conseillé de vérifier sa présence dans ce dossier (par exemple via le volet Files de RStudio).
Si vous souhaitez enregistrer un fichier ailleurs que dans le working directory, il est nécessaire de préciser dans l’argument file le chemin complet menant à l’emplacement désiré.
Pour charger les données d’un fichier .Rda (ou .RData), on utilise la fonction load(). Une alternative consiste à passer par le menuFile > Open File.... Il suffit alors de naviguer jusqu’au fichier souhaité, de cliquer sur Open, puis de confirmer le message “Do you want to load the R data file…” en sélectionnant Yes. Tous les objets contenus dans le fichier deviennent alors accessibles dans la session R.
Pour le vérifier, vous pouvez par exemple supprimer les objets x, y et z avec la commande : rm(x, y, z). Puis charger à nouveau le fichier xyz.Rda avec la commande : load("xyz.Rda"). Les objets x, y et z réapparaissent alors dans Global Environment et sont de nouveau disponibles.
Si R affiche un message d’erreur du type “Error in … cannot open the connection…”, cela signifie généralement qu’il ne parvient pas à trouver ou à ouvrir le fichier demandé. Dans ce cas, vérifiez : (1) l’emplacement de votre working directory, (2) que le fichier existe bien dans ce dossier, et (3) que vous avez correctement indiqué son nom (y compris l’extension).
Il est possible de sauvegarder en une seule fois tous les objets créés au cours d’une session, càd l’ensemble du contenu du Global Environment. Pour cela, on utilise la fonction save.image() :
save.image(file = "objets_session.Rda")Le fichier objets_session.Rda est alors enregistré dans le working directory et contient l’intégralité des objets de la session en cours.
Vous pouvez configurer RStudio pour qu’il effectue automatiquement une sauvegarde du Global Environment à chaque fermeture de la session. Pour cela, ouvrez le menu : Tools > Global Options.... Puis, dans la rubrique R General, repérez l’option : Save workspace to .RData on exit et choisissez Always. Validez en cliquant sur OK.
Vous pouvez également cocher l’option Restore .RData into workspace at startup pour recharger automatiquement le dernier workspace sauvegardé au démarrage de RStudio. Cependant, cette pratique n’est généralement pas conseillée, car elle peut réintroduire d’anciens objets dans votre session et rendre plus difficile la traçabilité de votre code. Il est préférable de recréer explicitement les objets nécessaires à partir de vos scripts.