12 Les graphiques avec ggplot
Dans ce chapitre, nous allons apprendre à créer des graphiques en utilisant le package spécialisé ggplot2, abrégé ci-après en ggplot. ggplot est un package très complet et très célèbre qui repose sur le parincipe de “Grammar of Graphics”. Cette grammaire permet une description précise des différents composants d’un graphique, du plus simple au plus complexe. L’idée principale est de concevoir un graphique comme une succession de couches (layers, en anglais) qui se superposent pour, au final, donner le résultat escompté, un peu comme on peut décomposer la structure d’une phrase (complexe) à l’aide de règles grammaticales.
Ce principe, ainsi que les différentes composantes d’un graphique, sont décrits plus en détail dans ce document et dans les références qu’il contient.
Pratiquement, tout graphique que l’on peut faire avec R de base (càd. avec le package graphics) peut se faire avec ggplot et vise versa. Mais, lorsqu’il s’agit de réaliser des graphiques plus complexes et plus attractifs, ggplot est souvent plus facile — une fois ses mécanismes bien compris.
Pour commencer, nous avons besoin de charger le package ggplot2.
12.1 Les bases de ggplot
Syntaxe
La création d’un graphique ggplot débute avec l’appel de la fonction ggplot(), qui initialise l’objet graphique. Des couches supplémentaires (layers) sont ensuite ajoutées à l’aide du symbole +. La syntaxe de base s’articule généralement comme suit :
ggplot(<data.name>) + aes(<variables>) + geom_<xxx>(...)
#ou, de manière équivalente :
ggplot(data = <data.name>, mapping = aes(<variables>)) +
geom_<xxx>(...)La seconde forme est la plus couramment utilisée. Pour améliorer la lisibilité du code, on commence généralement par ggplot(df, aes(...)) (ou ggplot(df) + aes(...)), puis on ajoute chaque couche sur une nouvelle ligne. Le symbole + doit impérativement figurer en fin de ligne, et non en début de ligne suivante, sous peine d’erreur d’exécution. Une autre syntaxe très répandue consiste à utiliser l’opérateur pipe pour écrire : df |> ggplot(aes(...)) + geom_<xxx>(...).
Dans la syntaxe ci-dessus
ggplot()permet, typiquement, de spécifier le jeu de données à analyser. Il doit s’agir d’un objet de typedata.frame(ou un équivalent comme un tibble).aes(), abréviation de aesthetics, permet de spécifier les variables à à représenter et d’associe à chacune un rôle/emplacement ou une propriété visuelle : les axes (x,y), couleur (color), forme (shape), taille (size), etc. Nous reviendrons sur ce sujet dans la Section Section 12.2.geom_<xxx>(), où<xxx>désigne une forme géométrique, permet de spécifier le type de représentation graphique souhaitée. Parmi les fonctionsgeomles plus utilisées, on trouve :geom_point(), pour tracer des points, etgeom_line()pour relier les données, selon l’ordre croissant dex. Nous reviendrons sur les fonctionsgeomplus en détail dans la Section Section 12.3.
Pour débuter, réalisons un graphique simple à partir d’un petit jeu de données :
df <- data.frame(Varx = c(1, 4, 3, 6, 2, 1), Vary = c(2, 4, 2, 1, 3, 3))
ggplot(data = df, # spécifier les données
mapping = aes(x = Varx, y = Vary)) + # associer 'Varx' à l'axe des x et 'Vary' à l'axe des y
geom_point() + # Couche 1 : ajouter les points
geom_line() # Couche 2 : relier les points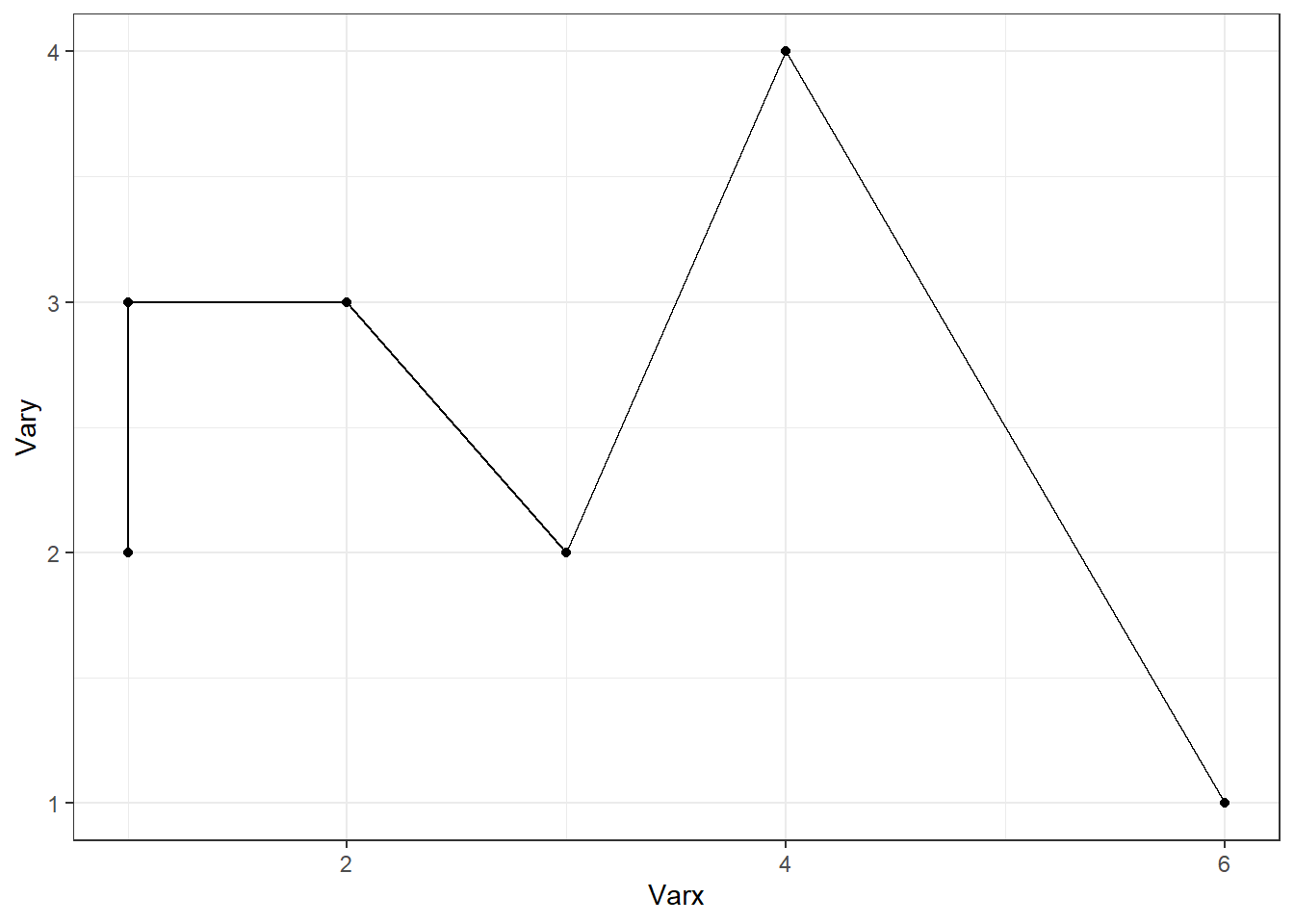
Le code ci-dessus peut être décomposé comme suite (exécutez le script ligne par ligne) :
ggplot(df) # Haut à gauche
ggplot(df) + aes(Varx, Vary) # Haut à droite
ggplot(df) + aes(Varx, Vary) + geom_point() # Bas à gauch
ggplot(df) + aes(Varx, Vary) + geom_point() + geom_line() # Bas à droite
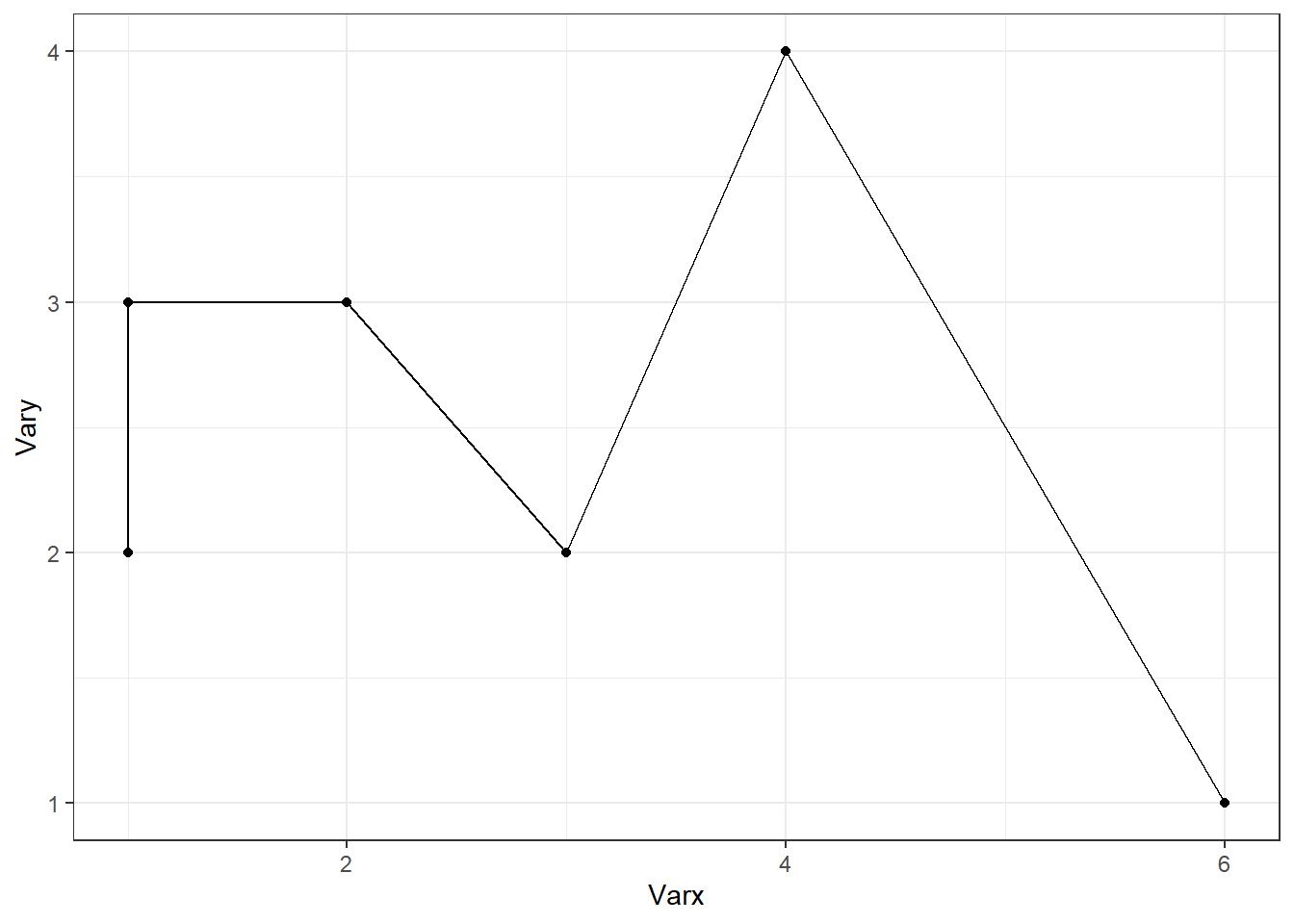
L’ordre dans lequel les geoms sont ajoutées dans ggplot a une influence directe sur le rendu graphique. Chaque couche est dessinée dans l’ordre où elle apparaît dans le code, ce qui peut affect la visibilité des éléments et leur superposition.
# Gauche
ggplot(df, aes(Varx, Vary)) +
geom_point(size = 3, color = "red") +
geom_line(linewidth = 2, color = "blue")
# Droite
ggplot(df, aes(Varx, Vary)) +
geom_line(linewidth = 2, color = "blue") +
geom_point(size = 3, color = "red")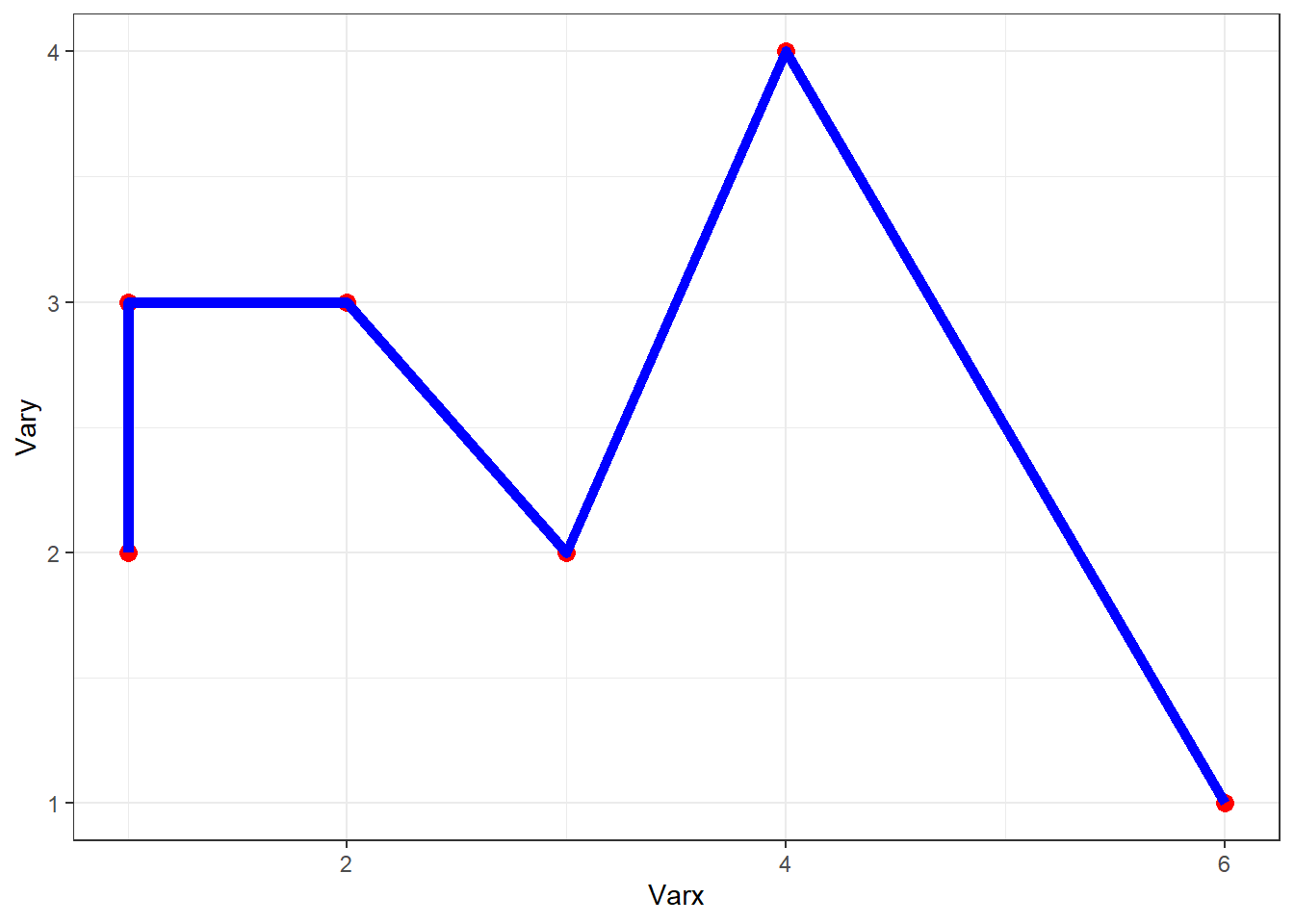
Structure interne d’un ggplot
Nous pouvons sauvegarder un ggplot dans un objet comme n’importe quel autre objet R. Cela permet de le manipuler, de le modifier ou de le réutiliser ultérieurement. Exemple :
p <- ggplot(df, aes(x = Varx, y = "")) + geom_point(size = 2, color = "red") +
geom_line(linewidth = 1, color = "blue") + labs(y = NULL)
p # ou : print(p) # ou encore : plot(p)
L’objet p contient toutes les informations nécessaires à la construction du graphique. Si vous examinez sa structure avec str(p), vous constaterez qu’il s’agit d’une liste composée de plusieurs éléments, dont voici les noms :
names(p)NULLParmi les éléments qui composent l’objet p, on trouve notamment data, qui contient le jeu de données utilisé (ici df), mapping, qui regroupe les associations entre les variables et leurs rôles visuels dans le graphique définis via aes(), et layers, qui correspond à la liste des couches ajoutées. D’autres composants importants incluent scales, theme, coordinates et facet, qui contrôlent respectivement les échelles, l’apparence générale, le système de coordonnées et le découpage éventuel du graphique en sous-parties.
Une manière plus approfondie d’examiner la structure interne d’un objet ggplot consiste à utiliser la fonction ggplot_build(), qui décompose le graphique en une structure détaillée. Parmi les éléments retournés, on trouve
ggplot_build(p)$data[[1]]
x y PANEL group shape colour fill size alpha stroke
1 1 1 1 1 19 red NA 2 NA 0.5
2 4 1 1 1 19 red NA 2 NA 0.5
3 3 1 1 1 19 red NA 2 NA 0.5
4 6 1 1 1 19 red NA 2 NA 0.5
5 2 1 1 1 19 red NA 2 NA 0.5
6 1 1 1 1 19 red NA 2 NA 0.5
[[2]]
x y PANEL group flipped_aes colour linewidth linetype alpha
1 1 1 1 1 FALSE blue 1 1 NA
6 1 1 1 1 FALSE blue 1 1 NA
5 2 1 1 1 FALSE blue 1 1 NA
3 3 1 1 1 FALSE blue 1 1 NA
2 4 1 1 1 FALSE blue 1 1 NA
4 6 1 1 1 FALSE blue 1 1 NAqui permet d’accéder aux données transformées par ggplot, prêtes à être tracées. Ces données incluent les coordonnées calculées, les propriétés visuelles (comme la couleur ou la taille), ainsi que d’autres paramètres aesthetics. ggplot_build(p)$data est organisée sous forme d’une liste de dataframes - une dataframe par couche graphique. Ce type d’inspection est particulièrement utile pour comprendre comment ggplot interprète et transforme les données en éléments graphiques.
Un objet ggplot sauvegardé peut être modifié en lui ajoutant ou retirant des éléments. Dans l’exemple ci-dessous, nous illustrons cette flexibilité en trois étapes :
p <- ggplot(df, aes(x = Varx, y = "")) + geom_point(); p
p <- p + aes(y = Vary) ; p # Ajouter y
p <- p + geom_line() ; p # Ajout la ligne
p$layers[[2]] <- NULL ; p # Supprimer la ligne
Ce type de manipulation montre que l’on peut enrichir ou épurer un graphique sans repartir de zéro. Toutefois, il n’est pas toujours simple d’intervenir directement sur les composants internes d’un objet ggplot : certains éléments sont interdépendants, et leur modification peut entraîner des incohérences ou des erreurs si elle n’est pas soigneusement orchestrée.
Pour la suite de nos exemples, nous allons travailler avec le jeu de données mpg, fourni par le package ggplot2. Ce jeu de données, que nous avons déjà exploré au chapitre précédent, contient des informations sur différents modèles de voitures, notamment leur consommation, leur type de transmission, leur cylindrée, et bien plus encore. Avant de commencer, nous appliquons quelques transformations préparatoires afin de faciliter la visualisation et l’analyse :
manufacturer model displ year cyl
Length:234 Length:234 Min. :1.600 Min. :1999 4:81
Class :character Class :character 1st Qu.:2.400 1st Qu.:1999 5: 4
Mode :character Mode :character Median :3.300 Median :2004 6:79
Mean :3.472 Mean :2004 8:70
3rd Qu.:4.600 3rd Qu.:2008
Max. :7.000 Max. :2008
trans drv cty hwy fl class
auto :157 4:103 Min. : 9.00 Min. :12.00 c: 1 2seater : 5
manual: 77 f:106 1st Qu.:14.00 1st Qu.:18.00 d: 5 compact :47
r: 25 Median :17.00 Median :24.00 e: 8 midsize :41
Mean :16.86 Mean :23.44 p: 52 minivan :11
3rd Qu.:19.00 3rd Qu.:27.00 r:168 pickup :33
Max. :35.00 Max. :44.00 subcompact:35
suv :62 Titres et noms des axes
La fonction labs() permet d’enrichir un graphique ggplot en lui ajoutant un titre principal, un sous-titre, des étiquettes d’axes personnalisées, ainsi qu’une légende ou un commentaire via l’argument caption. Exemple :
p <- ggplot(mpg, mapping = aes(x = displ, y = hwy)) + geom_point() +
labs(
title = "Fuel economy for 38 popular models of cars",
subtitle = "Data from 1999 to 2008",
x = "Engine displacement, in litres",
y = "Highway miles per gallon",
caption = "mpg data from the ggplot2 package")
p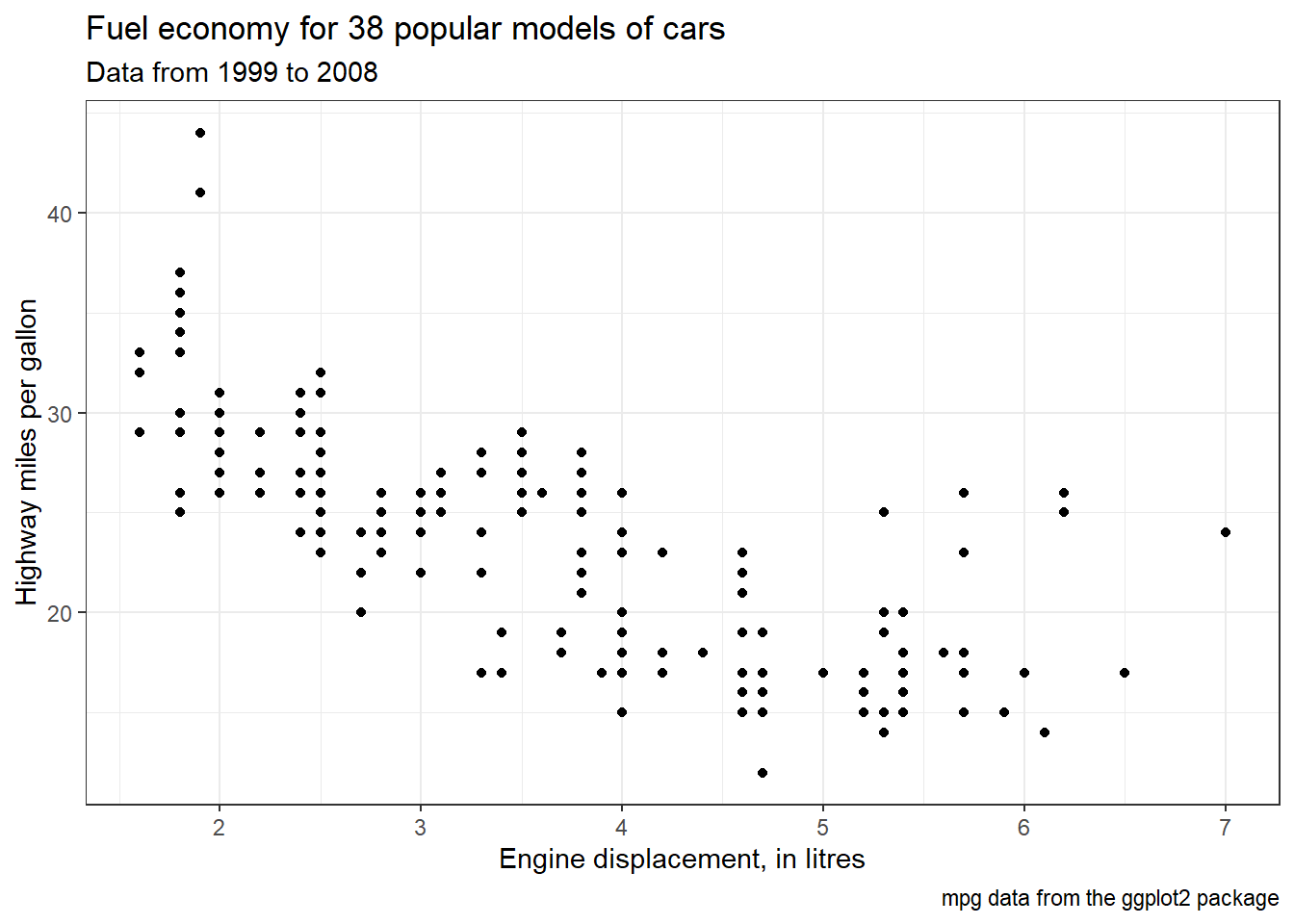
Ce type d’annotation est essentiel pour contextualiser un graphique, en particulier dans le cadre d’une communication scientifique. Il permet au lecteur de comprendre rapidement le sujet, la source des données et les unités utilisées.
Thèmes
On peut personnaliser l’apparence d’un graphique ggplot en lui appliquant un thème visuel. La manière la plus simple consiste à utiliser l’un des nombreux thèmes prédéfinis, facilement activables via les fonctions theme_<xxx>(). Exemple :
p + theme_gray() # gauche : thème par défaut de ggplot2
p + theme_bw() # droite : thème noir et blanc, plus épuré
Pour appliquer un thème à tous les graphiques de la session R en cours, on peut utiliser la fonction theme_set(). Exemple :
La fonction theme() permet quant à elle de modifier finement les composantes d’un thème, comme les titres, les axes, les légendes ou les marges. Exemple :
p + theme_bw() +
theme(
plot.title = element_text(color = "grey59", face = "italic"),
plot.subtitle = element_text(color = "red"),
axis.title = element_text(color = "blue", face = "bold"),
plot.margin = margin(t = 0.1, r = 0.1, b = 0.1, l = 0.1, unit = "mm")
)
Ces modifications peuvent également être appliquées globalement à l’aide de theme_set(). Exemple :
{
theme_bw() +
theme(
axis.title = element_text(color = "blue", face = "bold"),
plot.title = element_text(color = "blue", face = "bold"),
plot.subtitle = element_text(color = "blue", face = "bold"),
plot.margin = margin(t = 0.1, r = 0.1, b = 0.1, l = 0.1, unit = "mm")
)
} |> theme_set()Le nombre de paramètres disponibles dans theme() est considérable et couvre pratiquement tous les aspects visuels du graphique. Pour s’y retrouver plus facilement, le site ggplot2tor propose un outil interactif appelé Theme finder, qui permet d’explorer visuellement les options disponibles.
Tout au long de ce chapitre, nous utilisons le thème
theme_bw().
Scales
ggplot propose une large gamme de fonctions scale_*() qui permettent de customiser les axes du graphique (les repères, libellés, style d’affichage, etc), ainsi que d’autres aspects visuels comme les couleurs, les tailles ou les formes.
Par défaut, ggplot choisit automatiquement les scales à appliquer en fonction de la nature des données et du type de géométrie utilisée. Par exemple, lorsque vous exécutez :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point()ggplot ajoute automatiquement les scales suivants
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point() +
scale_x_continuous() + scale_y_continuous()Ces deux fonctions permettent notamment de choisir le nombre de graduations ou de définir des libellés personnalisés. Pour en savoir plus sur les options disponibles, consultez leur aide. Voici un exemple simple :
p <- ggplot(mpg, aes(x = displ, y = hwy)) + geom_point() ; p
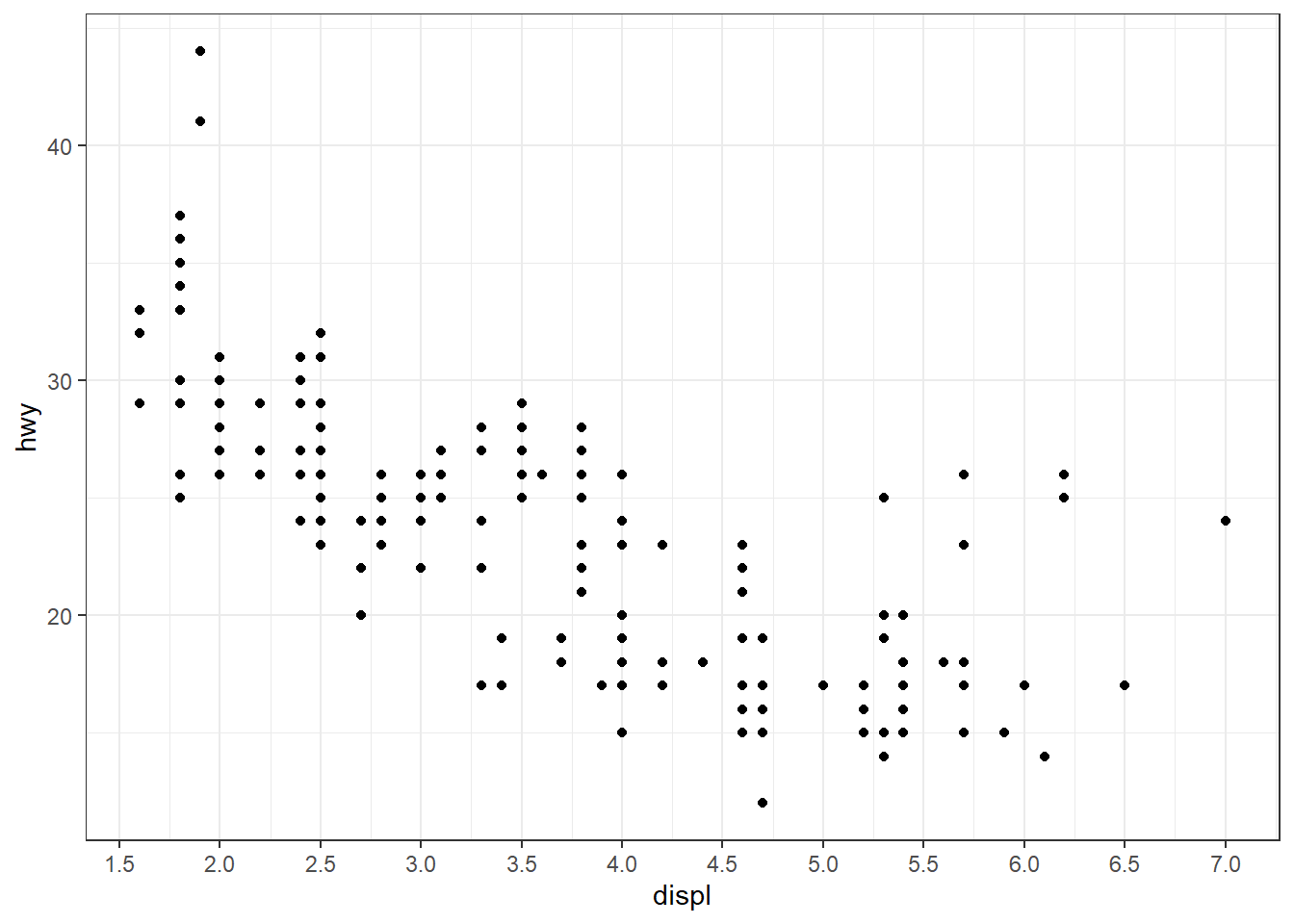
p + scale_x_continuous(n.breaks = 10)
p + scale_x_continuous(breaks = c(2, 4, 6), labels = c("a", "b", "c"), minor_breaks = seq(1, 7, 0.1))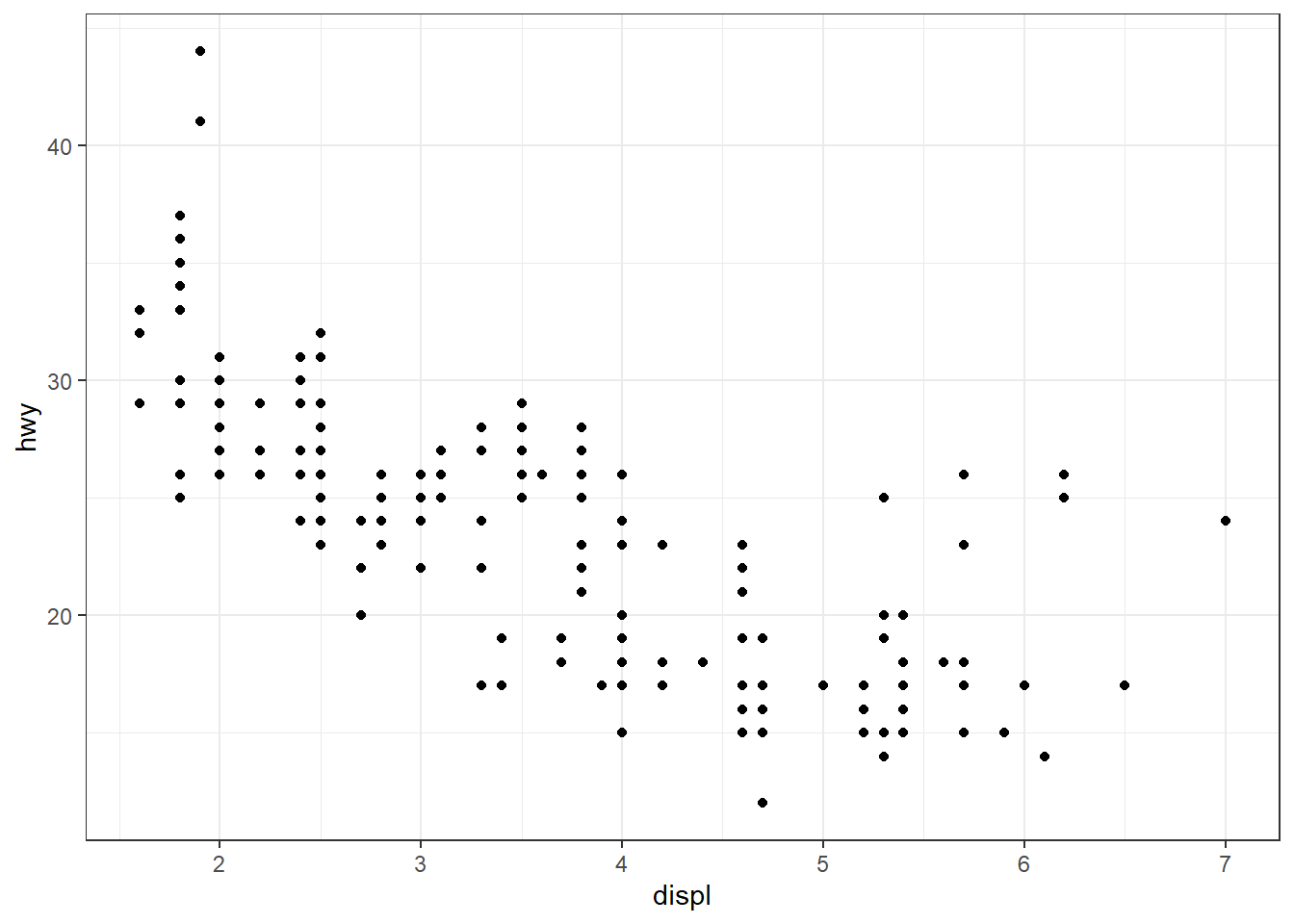
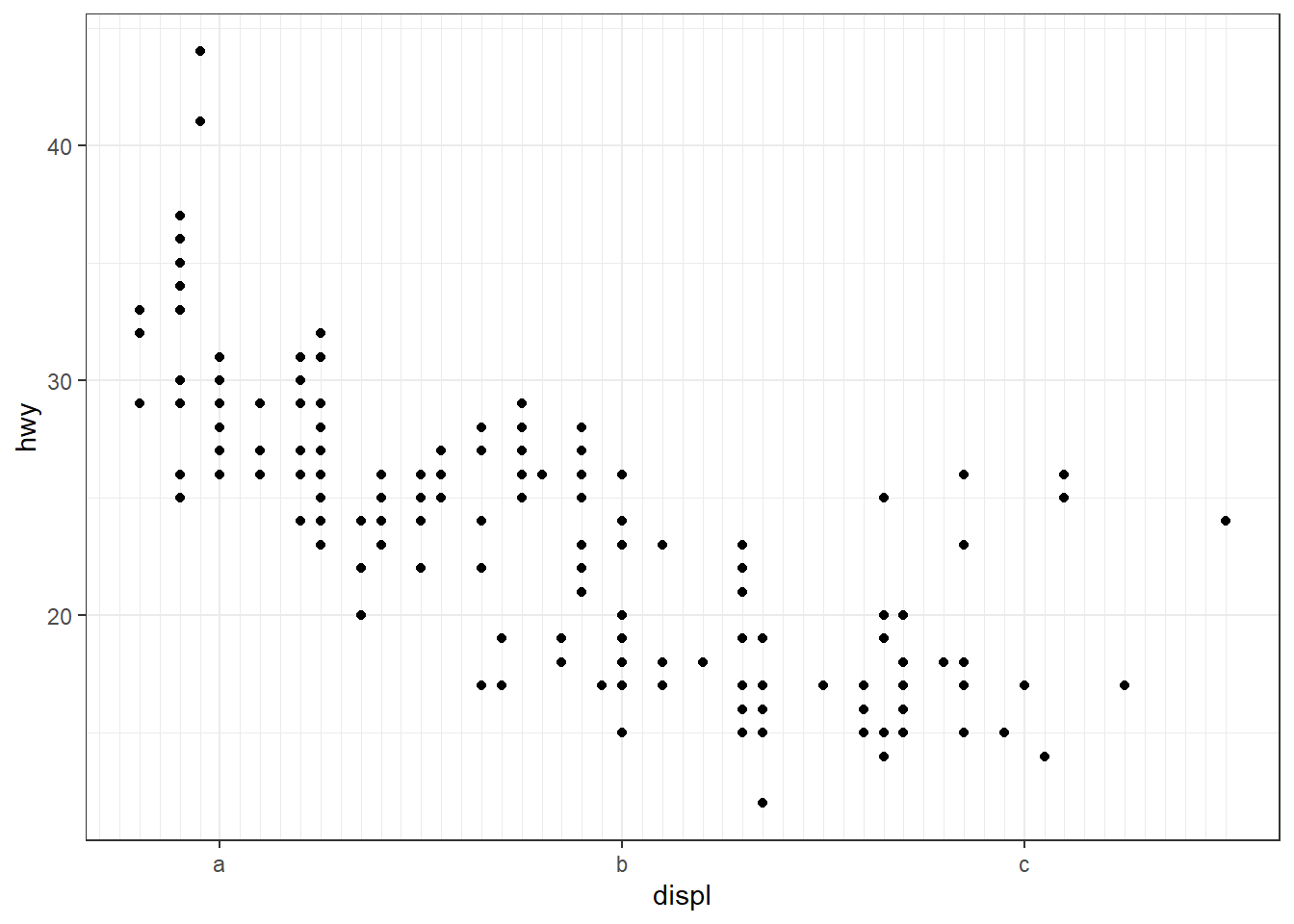
Ces fonctions peuvent aussi être utilisées pour restreindre l’affichage à un sous-ensemble spécifique de données. Exemple :
p + scale_y_continuous(limits = c(20, 30)) #--> Warning
# ou encore : p + ylim(20, 30)
# ou encore : p + lims(y = c(20, 30))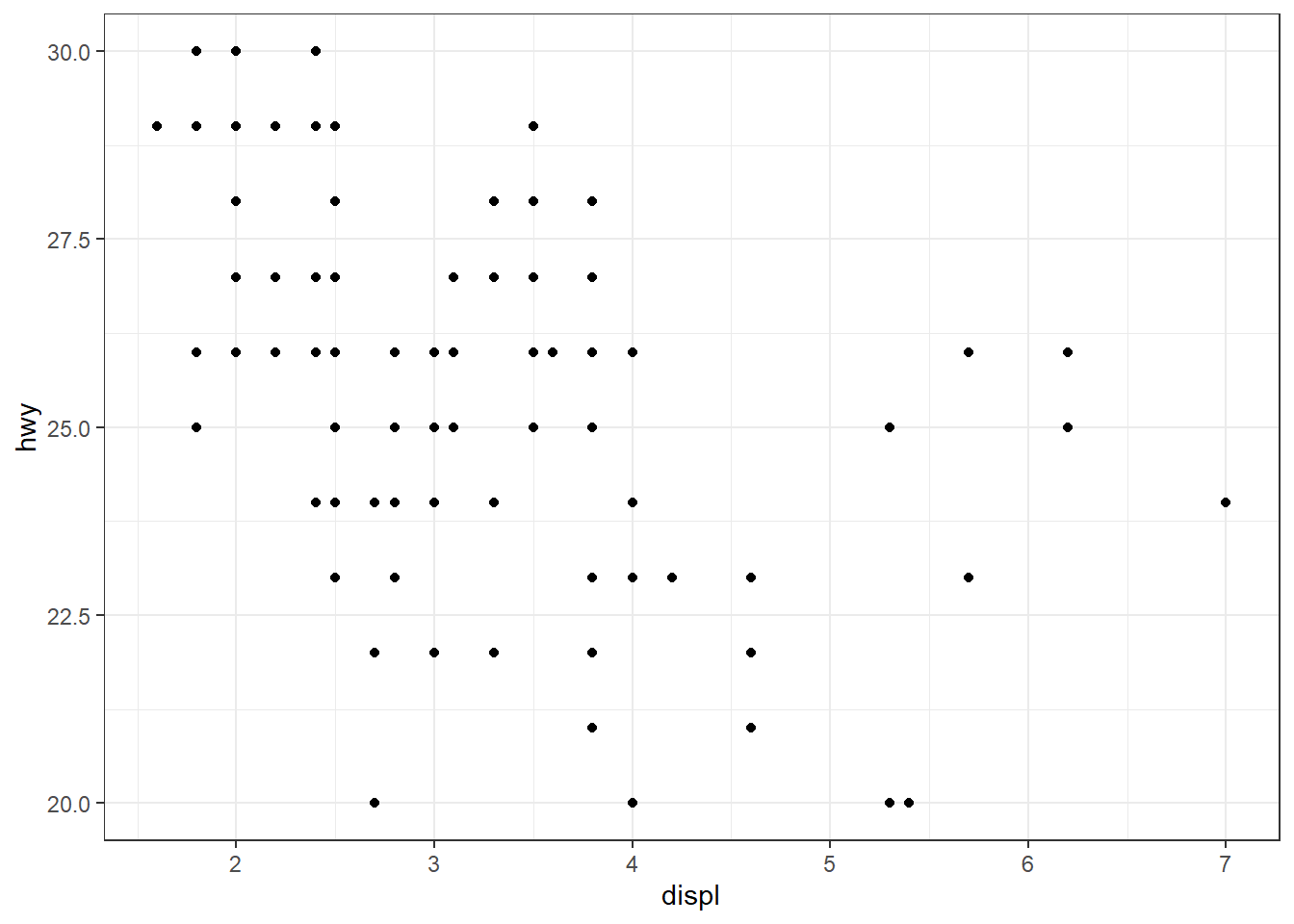
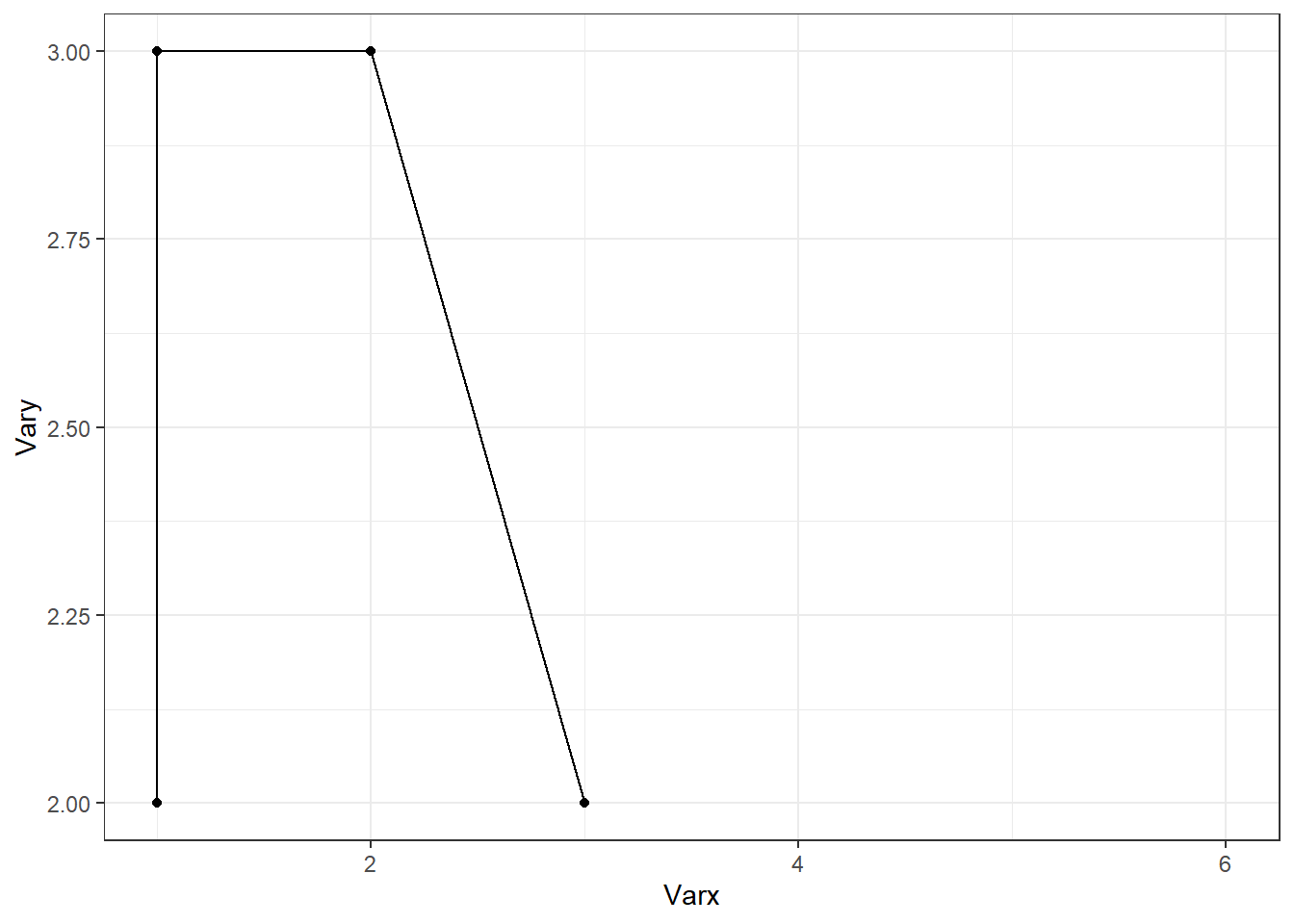
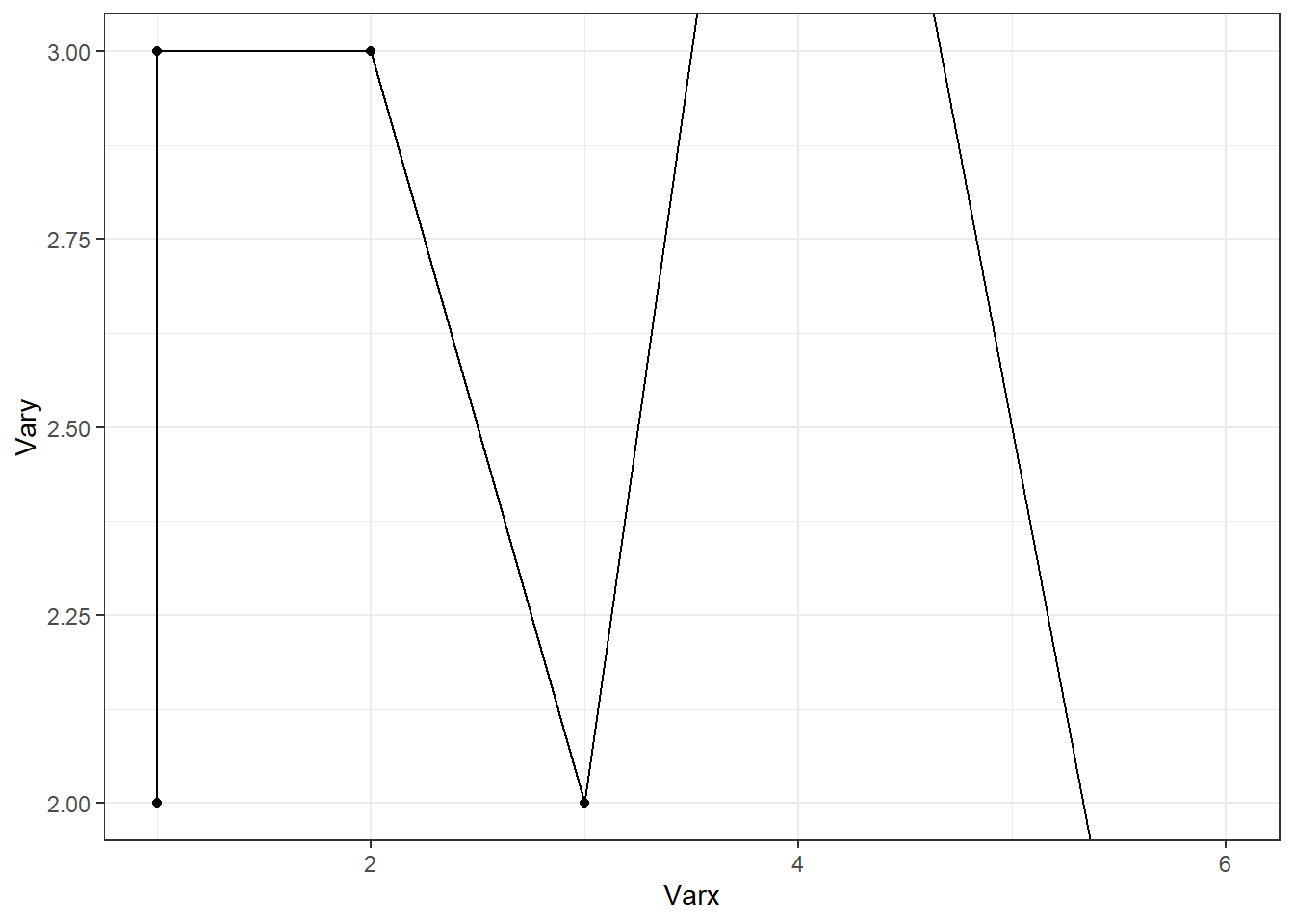
Lorsque l’on utilise scale_y_continuous(limits = c(20, 30)), on impose une plage de valeurs autorisées pour l’axe des ordonnées. Cette opération entraîne la suppression des données situées en dehors de l’intervalle spécifié : ces valeurs sont remplacées par NA dans les couches graphiques, ce qui signifie qu’elles ne sont ni affichées ni prises en compte dans les calculs statistiques ou les annotations. Si l’on souhaite uniquement restreindre l’affichage du graphique à une région spécifique, càd effectuer un zoom visuel sans modifier ni filtrer les données, il est préférable d’utiliser la fonction coord_cartesian(). Exemple (avec la dataframe df) :
p <- ggplot(df, aes(Varx, Vary)) + geom_point() + geom_line() ; p
p + scale_y_continuous(limits = c(2, 3))
p + coord_cartesian(ylim = c(2, 3))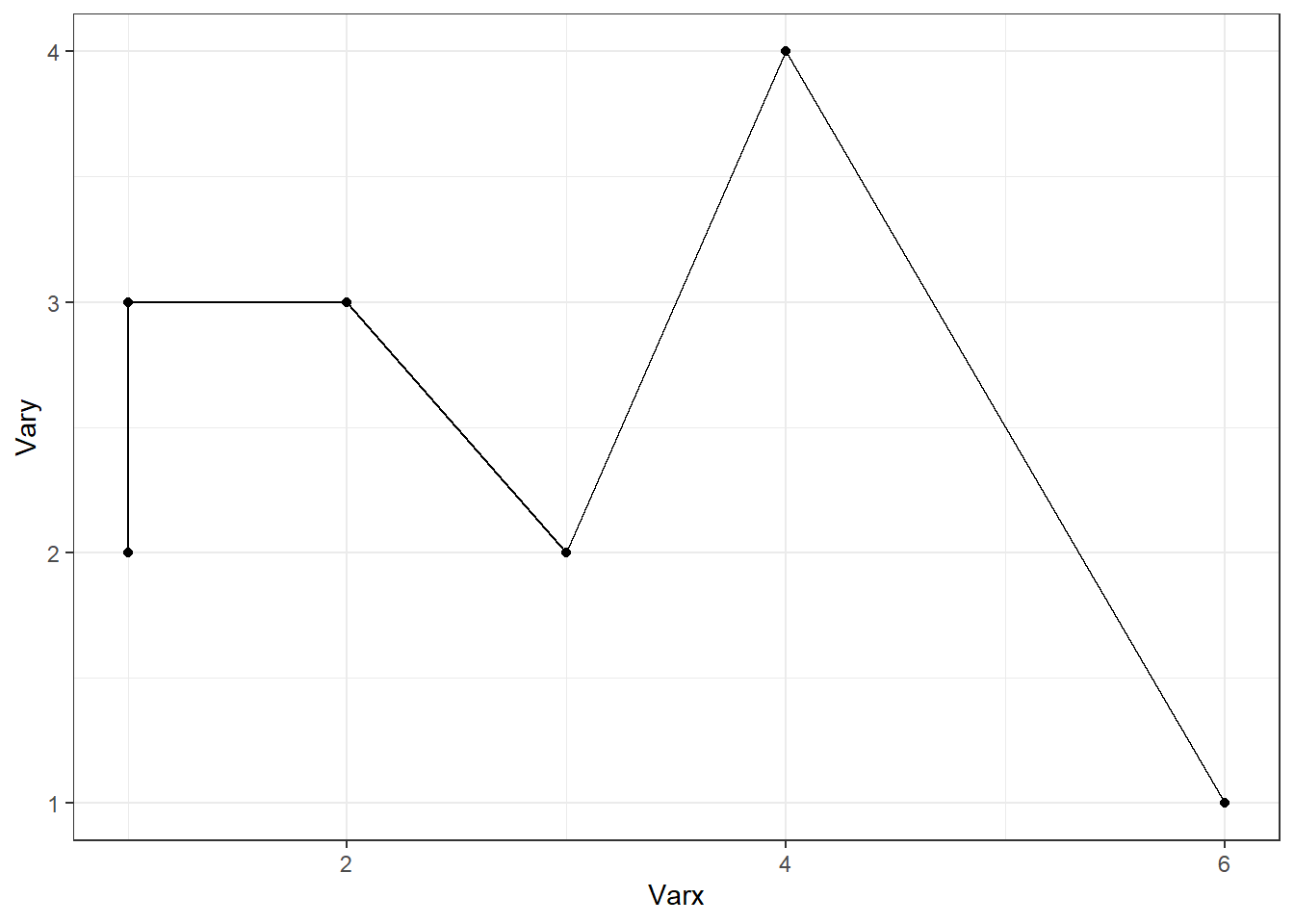
Pour les variables qualitatives, les fonctions scale_x_discrete() et scale_y_discrete() offrent des possibilités similaires. Exemple :
ggplot(mpg, aes(x = trans, y = hwy)) + geom_point() +
scale_x_discrete(
limits = c("manual", "auto"),
labels = c("auto" = "Automatique", "manual" = "Manuelle"))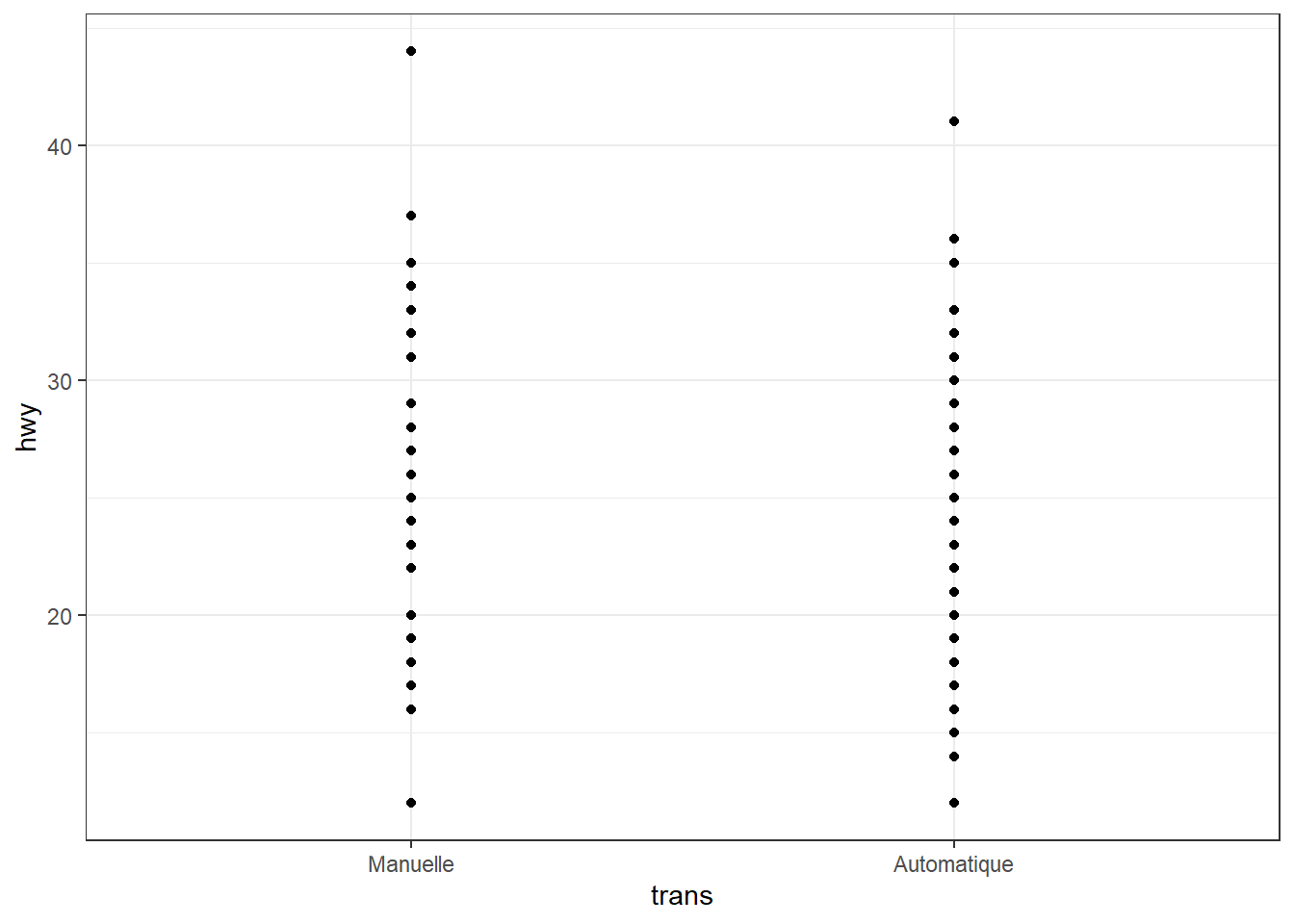
Au-delà du contrôle des axes, les fonctions scale_*() permettent de personnaliser un large éventail de paramètres esthétiques liés à la représentation graphique. Par exemple : le choix des couleurs avec scale_color_manual(), les tailles avec scale_size_continuous(), les formes avec scale_shape_manual(), etc. Si l’on ne spécifie pas explicitement les fonctions scale_*(), ggplot utilise par défaut des valeurs automatiques adaptées au type de données et à la présentation graphique. Par exemple, les couleurs sont choisies selon une palette prédéfinie, les formes sont attribuées selon un ordre standard, et les tailles sont réparties de manière proportionnelle. Ces choix automatiques permettent d’obtenir un graphique lisible sans configuration manuelle, mais les fonctions scale_*() offrent la possibilité de personnaliser ces associations pour mieux répondre à des besoins spécifiques.
Pour une vue d’ensemble des possibilités offertes, consultez le chapitre dédié aux scales dans le livre ggplot2: Elegant Graphics for Data Analysis. Et pour une exploration interactive des options disponibles, le site ggplot2tor propose un outil visuel très utile, notamment dans la rubrique Scales finder.
12.2 Les arguments aesthetics
Dans ggplot, le terme aesthetic (que l’on pourrait traduire en esthétique) désigne la manière dont les données sont traduites en éléments visuels dans un graphique. Cela peut correspondre, par exemple, à la position d’une variable (x, y), à la forme des points (shape), à leur couleur (color), ou à leur taille (size). Exemple :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(shape = 18, size = 3, color = "blue")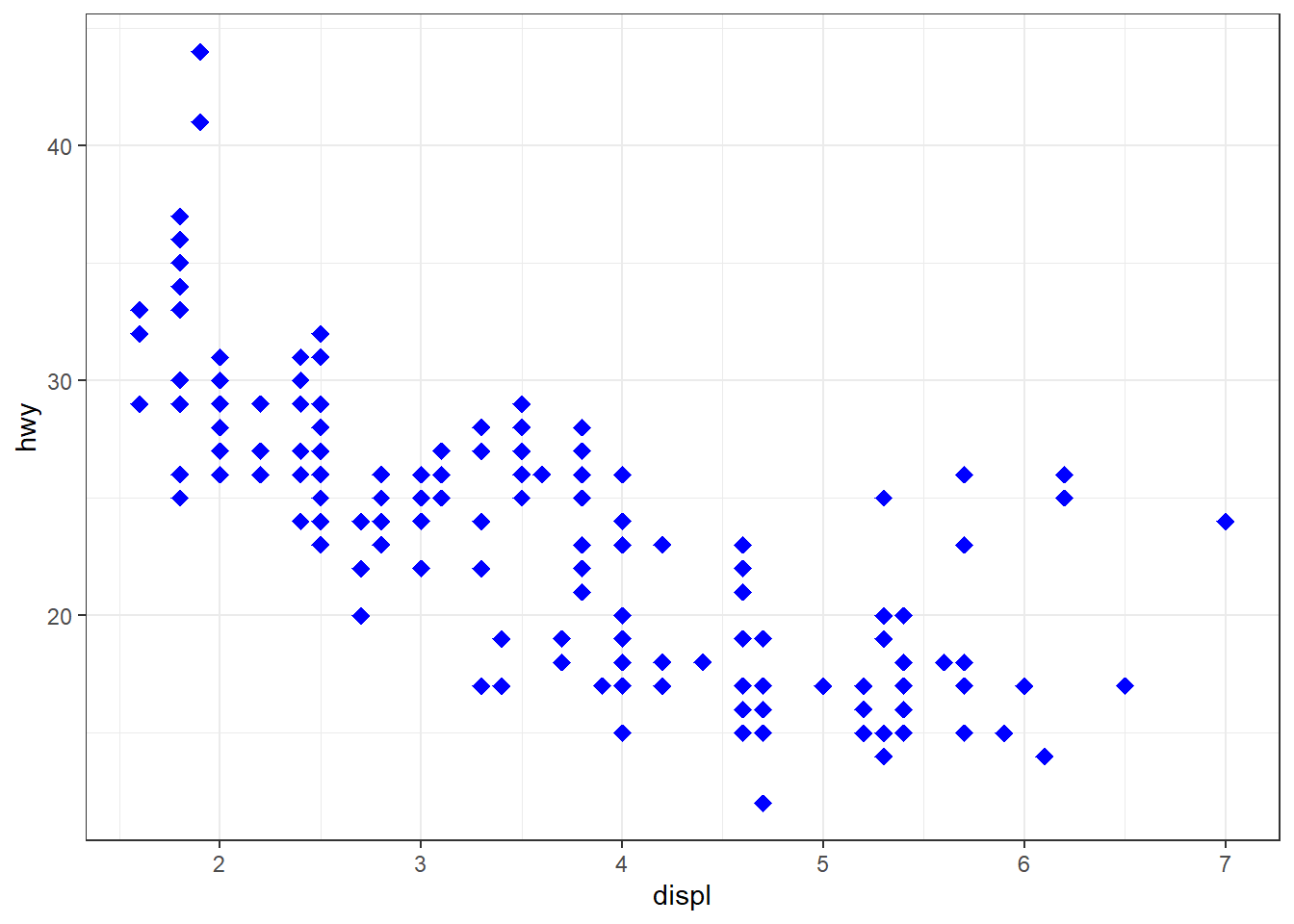
Les aesthetics qui ne sont pas explicitement définis dans le code ggplot conservent les valeurs par défaut attribuées par le système. Autrement dit, ggplot applique automatiquement des paramètres standards afin de produire un rendu cohérent, même en l’absence de spécifications précises. Par exemple, pour les points ggplot utilise, par défaut, shape = 19, size = 1.5, et color = "black".
Setting vs mapping
Les aesthetics peuvent être définies de deux façons, en fonction de l’effet recherché. Prenons l’exemple de shape, qui contrôle la forme des points. Deux situations sont à distinguer :
- On désire une forme statique (fixe) à appliquer à l’ensemble des points. Dans ce cas il faut placer l’argument
shapedirectement à l’intérieur dugeom_point(), et écrire, par exemple,geom_point(shape = <value>). - On désir une forme dynamique qui varie en fonction des valeurs prises par une variable de la dataframe; càd on désire mapper (associer) une variable à
shape. Dans ce cas il faut placershapeà l’intérieur de la fonctionaes(), et écriregeom_point(mapping = aes(shape = <var.name>)), ou simplementgeom_point(aes(shape = <var.name>)).
On désigne la première situation par le terme setting et la deuxième par le terme mapping. Un mapping est une mise en correspondance entre un argument aesthetic (shap, color, size, etc.) et une variable de la dataframe, alors qu’un setting est le fait d’assigner une valeur (fixe) à l’argument aesthetic. Contrairement au setting, un mapping doit toujours se faire à l’intérieur de la fonction aes().
L’exemple suivant illustre ces deux cas d’utilisation avec l’aesthetic shape. Tous les autres aesthetics suivent le même principe : ils peuvent être fixés ou mappés, selon le besoin.
# Gauche : setting (tous les points ont la même forme)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(shape = 1)
# Droite : mapping (chaque niveau de trans est représenté par une forme différente)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = trans))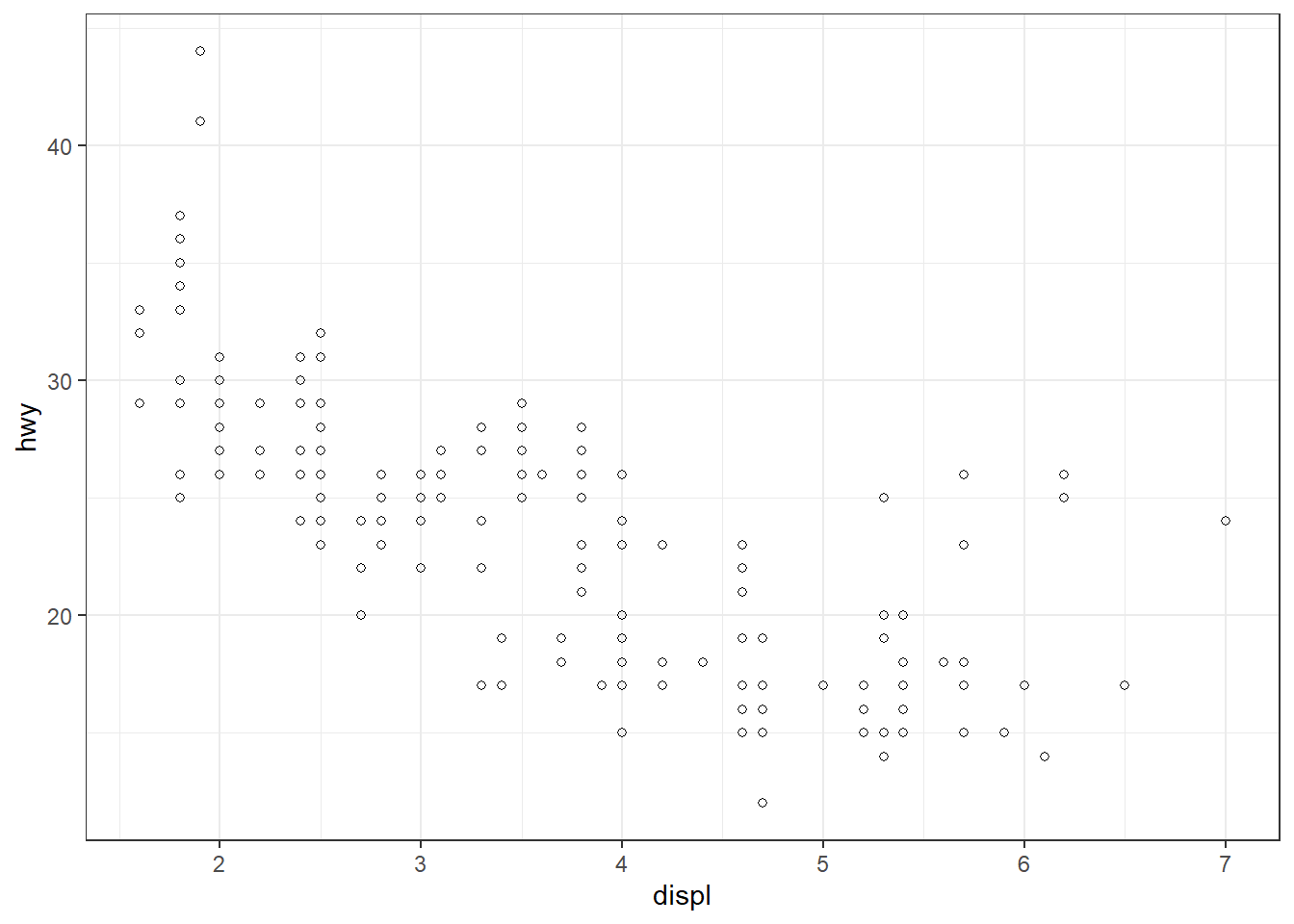
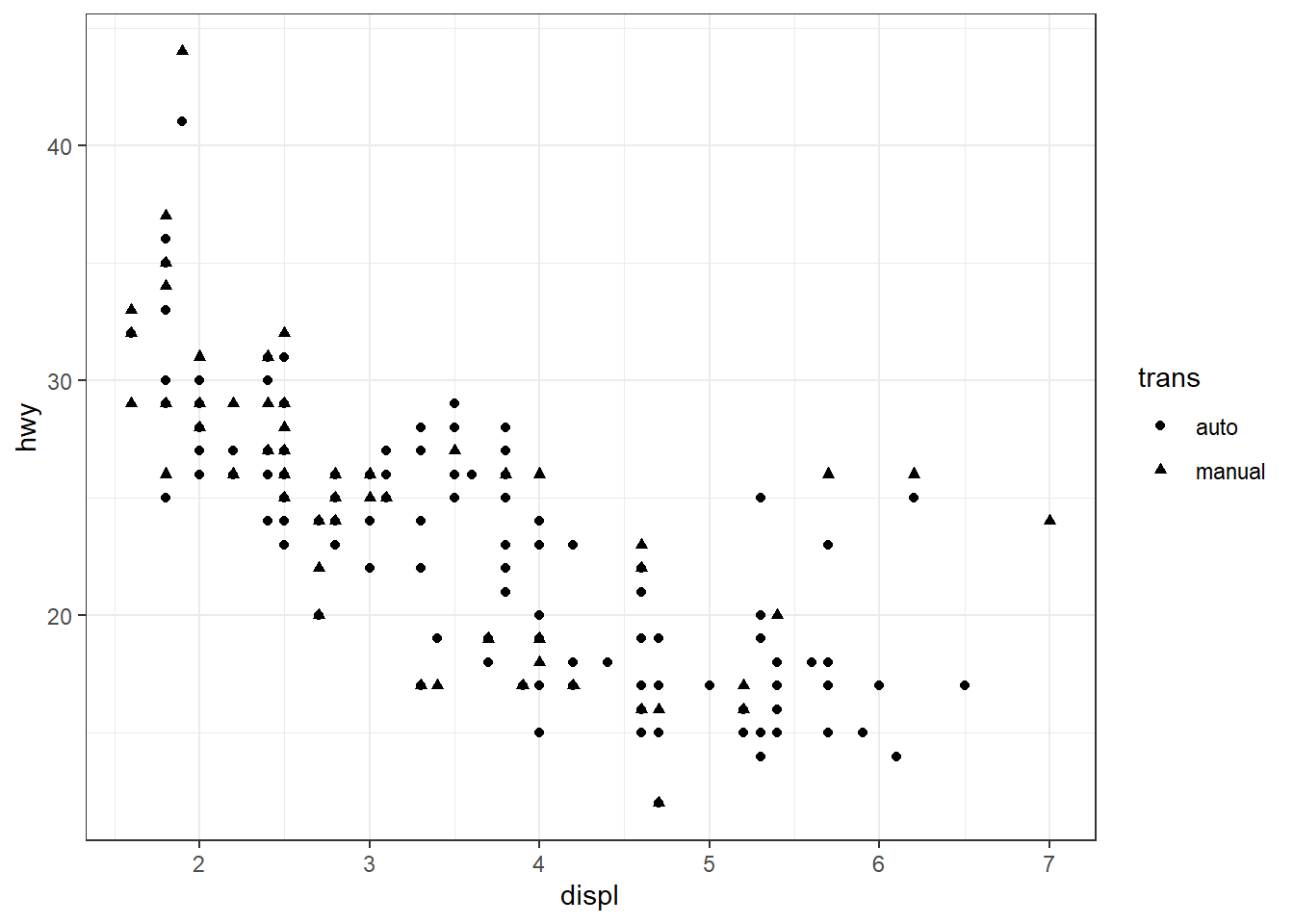
Dans la dernière ligne du code ci-dessus, nous avons placé aes() à l’intérieur de la fonction geom_point(). On pourrait aussi écrire ggplot(mpg, aes(x = displ, y = hwy, shape = trans)) + geom_point(), ou encore ggplot(mpg) + aes(x = displ, y = hwy, shape = trans) + geom_point(), ce qui produirait exactement le même plot. Cela dit, en règle générale, l’emplacement de aes() dans un ggplot a une importance capitale, dans la mesure où cela peut conduire à des sorties très différentes. Nous reviendrons sur ce point à la section Section 12.2.3.
Par défaut, ggplot ajoute automatiquement une légende lorsqu’un mapping (aes()) est effectué, dès lors que cela est jugé pertinent. Le titre de la légende correspond au nom de la variable mappée. Par exemple, dans l’appel geom_point(aes(shape = trans)), une légende est générée pour l’aesthetic shape, et son titre est simplement “trans”. Lorsque plusieurs aesthetics utilisent une même variable, ggplot fusionne les légendes en une seule, afin de limiter les redondances. Le titre de cette légende unique reprend le nom de la variable partagée. Exemple :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = trans, color = trans))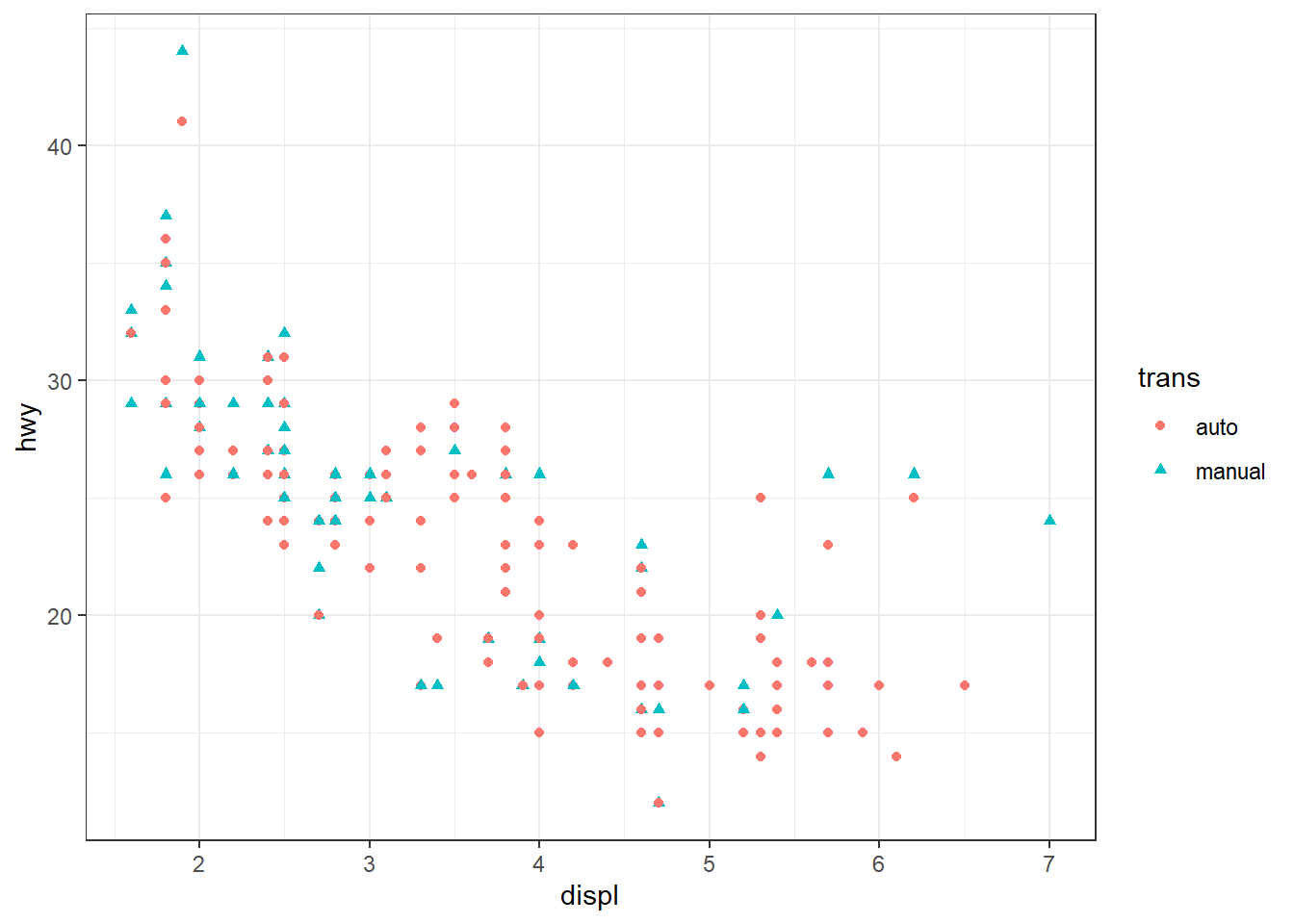
La fonction labs() permet de modifier les titres des légendes générées automatiquement par ggplot. Elle peut être utilisée pour remplacer le nom par défaut (issu de la variable mappée) par un libellé plus explicite ou plus lisible. Exemple :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = trans, color = trans)) +
labs(color = "Transmission", shape = "Transmission")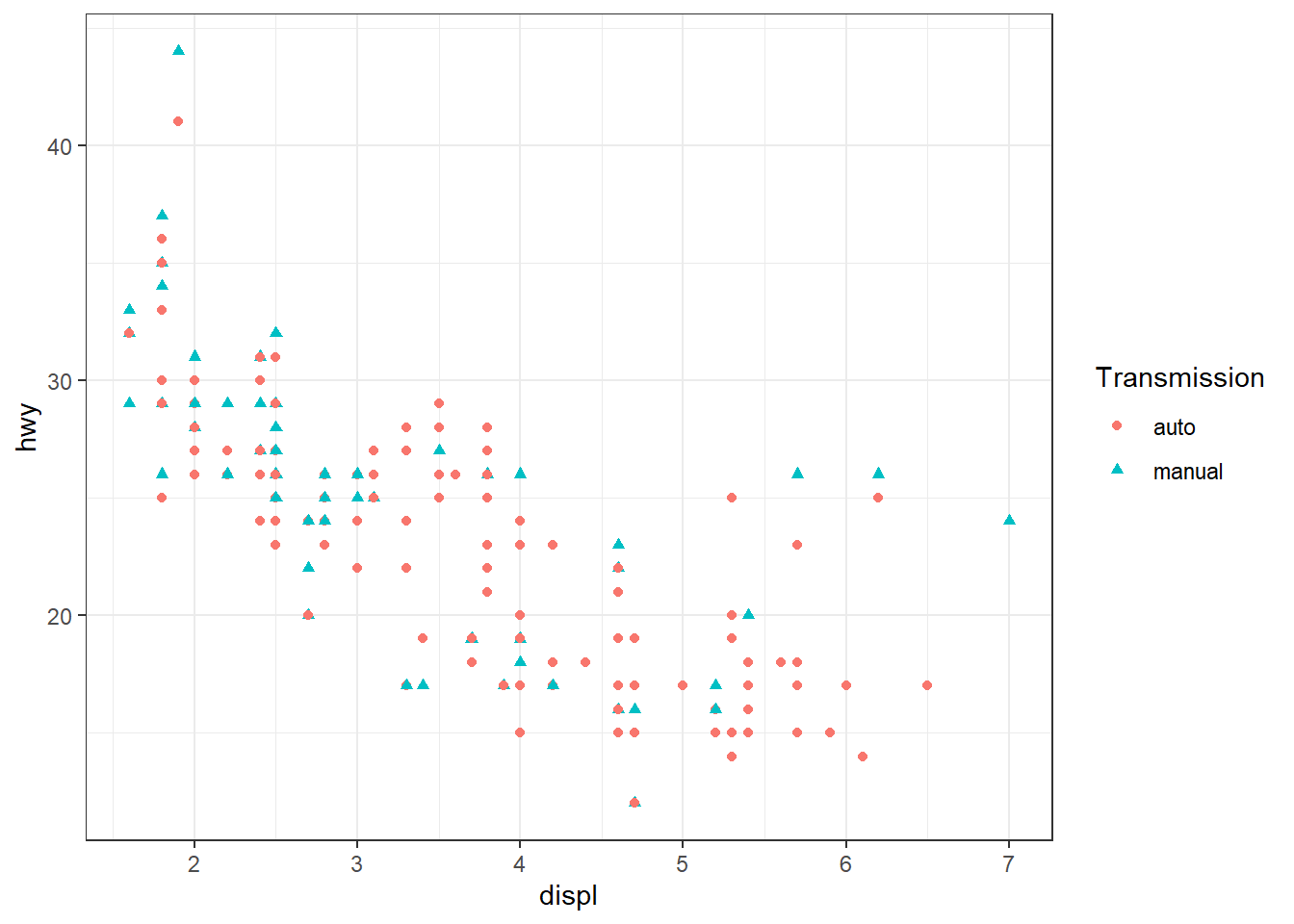
Un mapping ou un setting mal spécifié entraîne typiquement une erreur ou un résultat atypique. Voici trois exemples qui illustrent cela.
-
Exemple 1 : mauvais setting (Error)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(shape = trans)Error: object 'trans' not foundCette erreur est due au fait que ggplot interprète
transcomme un objet (chiffre) existant dans l’environnement de travail, or cela n’est pas le cas. Pour corriger cette erreur, il suffit de taperggplot(mpg, aes(x = displ, y = hwy)) + geom_point(shape = mpg$trans), ou mieux encore,ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = trans)). -
Exemple 2 : mauvais mapping (Error)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = 1))Error in `geom_point()`: ! Problem while computing aesthetics. ℹ Error occurred in the 1st layer. Caused by error in `scale_f()`: ! A continuous variable cannot be mapped to the shape aesthetic. ℹ Choose a different aesthetic or use `scale_shape_binned()`.Ici, ggplot interprète 1 comme une variable numérique constante, ce qui est incompatible avec l’argument
shape, qui, lorsqu’il est mappé, attend une variable de type factoriel; voir?geom_point. -
Exemple 3 : mauvais mapping (Résultat atypique)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(shape = '1'))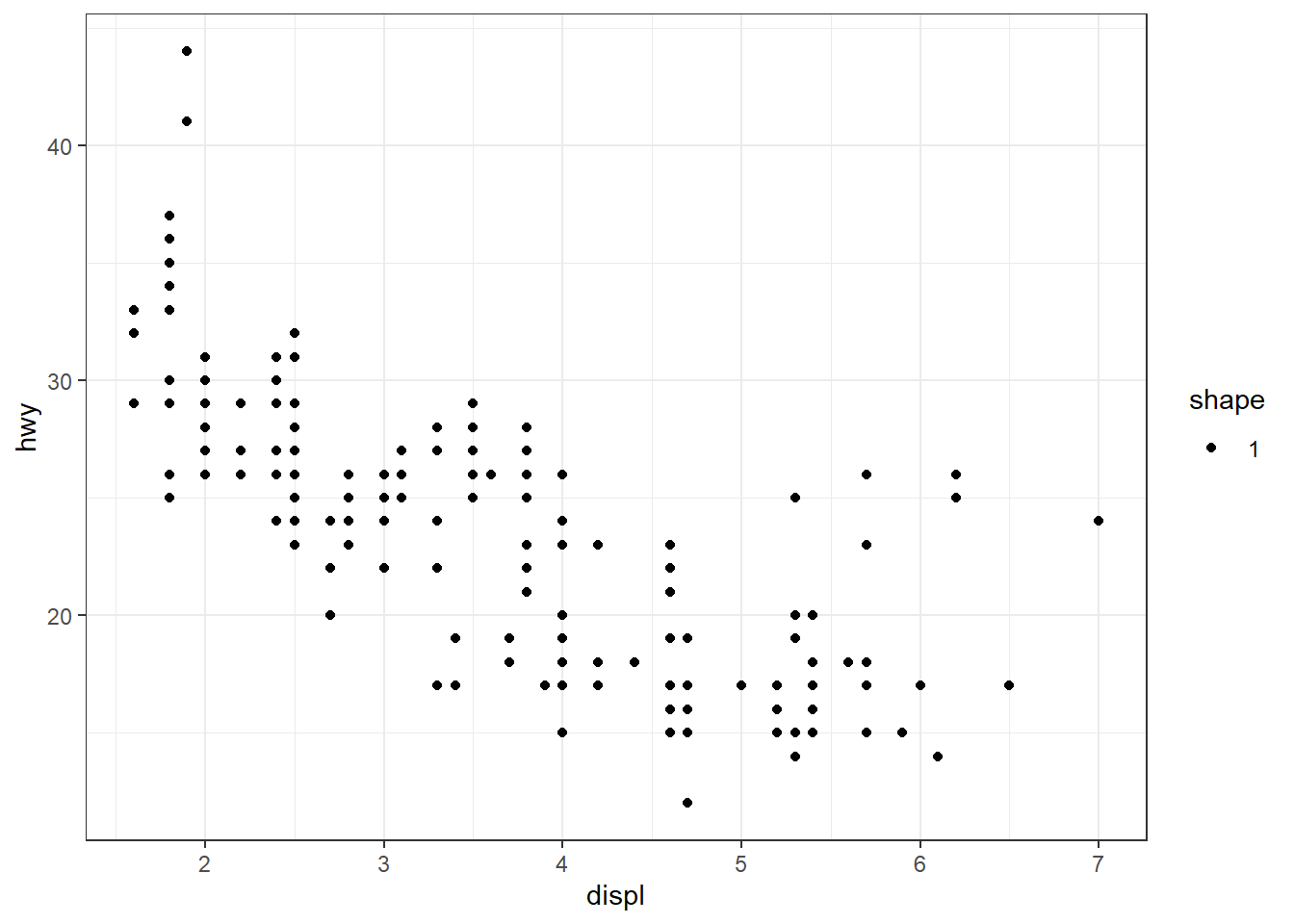
Cette fois, l’erreur disparaît, mais tous les points ont la forme par défaut et une légende apparaît. La raison est que ici ‘1’ est interprété comme une variable factorielle à un seul niveau, ce qui déclenche la création automatique d’une légende, sans effet visuel sur les points. Cette “anomalie” peut être exploitée pour forcer l’apparition d’une légende, comme illustré dans la Section 12.3.5.
Principaux aesthetics et leur usage
En plus de x et/ou y, chaque fonction geom (geom_<xxx>()) accepte un certain nombre d’aesthetics, les plus utilisés sont :
-
color: couleur du contour ou des lignes.
-
fill: couleur de remplissage des formes (barres, boîtes, surfaces, etc.). -
label: texte à afficher dans un graphique (voirgeom_text()). -
size: taille des points, du texte ou des symboles.
-
alpha: niveau de transparence (de 0 = invisible à 1 = opaque).
-
linewidth: épaisseur des lignes. -
linetype: style de ligne (continue, pointillée, etc.).
-
shape: forme des points (cercles, triangles, croix, etc.).
-
group: regroupe les données pour les calculs ou les tracés (voirgroup).
Les aesthetics color, fill et label peuvent être mappés à des variables continues ou discrètes, tandis que size, alpha et linewidth doivent être associés à des variables numériques. À l’inverse, linetype, shape et group se mappent à des variables discrètes.
La liste des formes (shape) et des types de lignes (linetype) reconnus par ggplot est identique à celle du système graphique de base de R, décrite dans le chapitre précédent : elles correspondent respectivement aux paramètres pch et lty de la fonction de base plot() (voir Section 11.2.3). ggplot reconnaît également les noms de couleurs de base R, mais il utilise par défaut un système de palettes plus riche, plus cohérent et mieux différencié visuellement.
Plusieurs aesthetics sont communs à presque l’ensemble des geoms — notamment color, size et alpha. Pour connaître les aesthetics spécifiques à une fonction donnée, il est recommandé de consulter son aide (par exemple avec ?geom_point); un résumé est présenté dans le tableau Table 12.1 ci‑dessous. Par la suite, nous illustrons rapidement l’usage de ces aesthetics, à l’exception de shape (déjà présenté ci‑dessus), ainsi que de fill et label que nous aborderons plus loin.
color
# Haut à gauche : setting color to red
ggplot(mpg, aes(x = displ, y = hwy)) + geom_line(color = "red")
# Haut à droite : mapping color to cty (numeric)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(color = cty))
# Bas à gauche : mapping color to trans (factor)
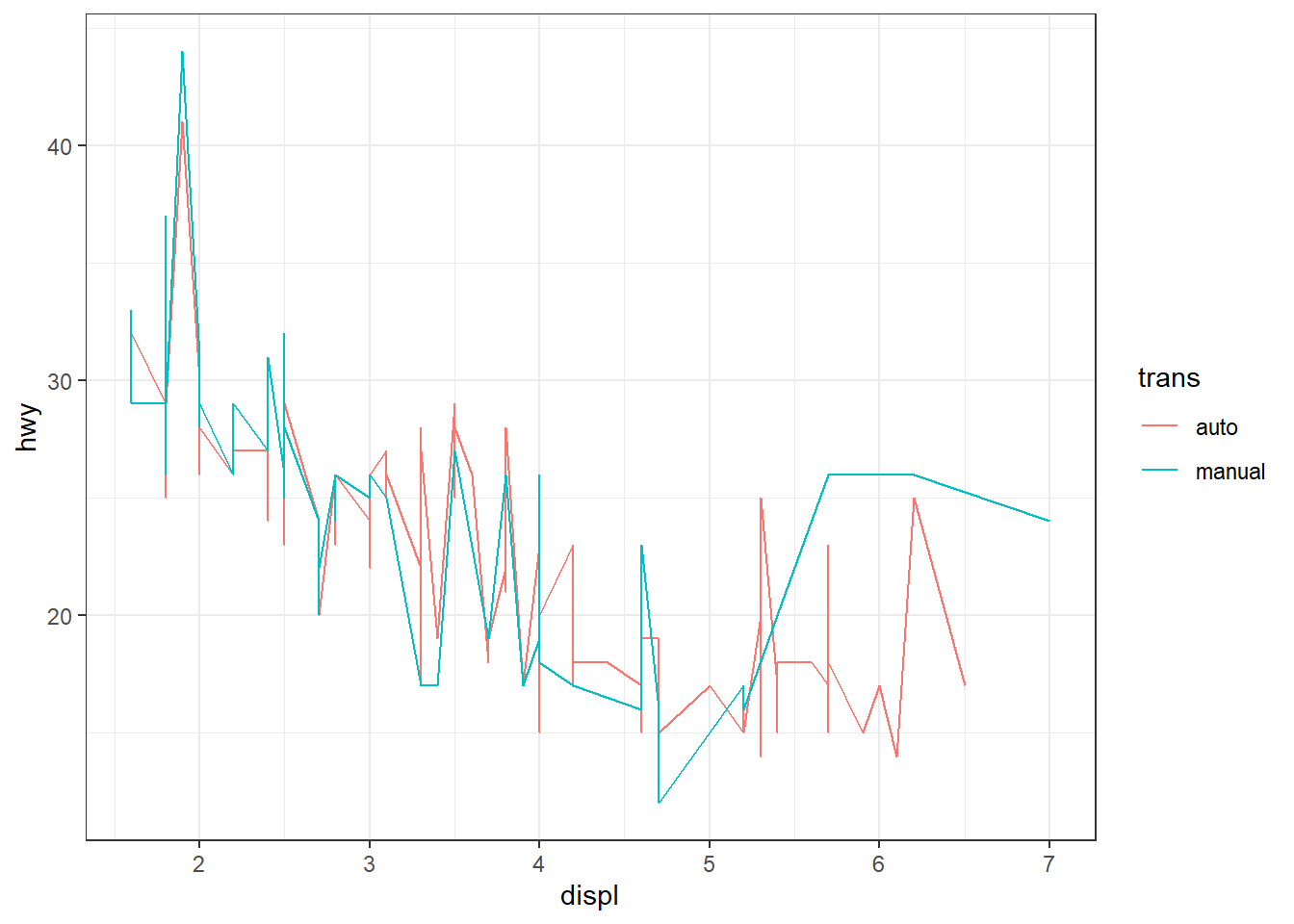
ggplot(mpg, aes(x = displ, y = hwy)) + geom_line(aes(color = trans))
# Bas à droite : mapping color to a logical variable
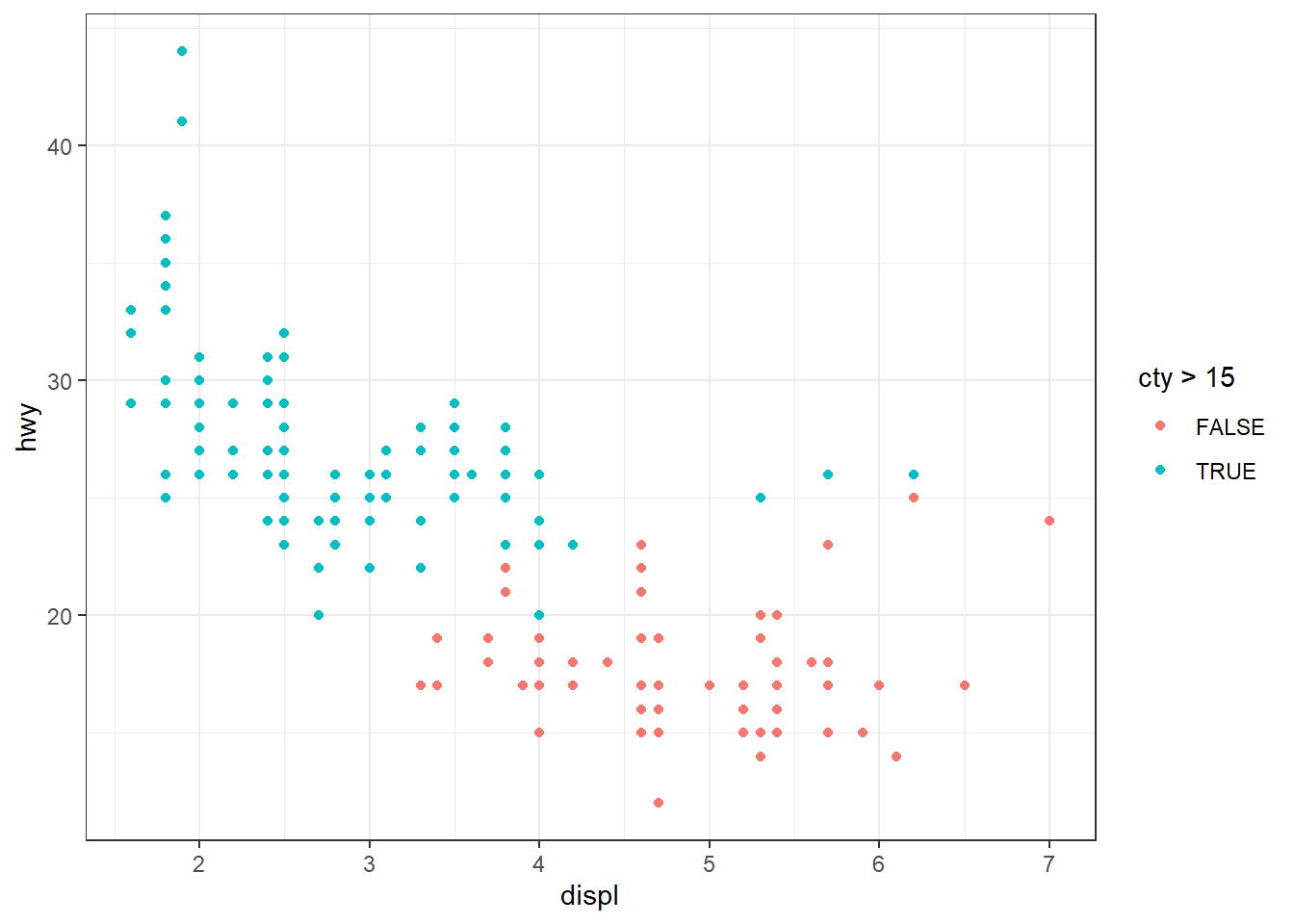
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(color = cty > 15))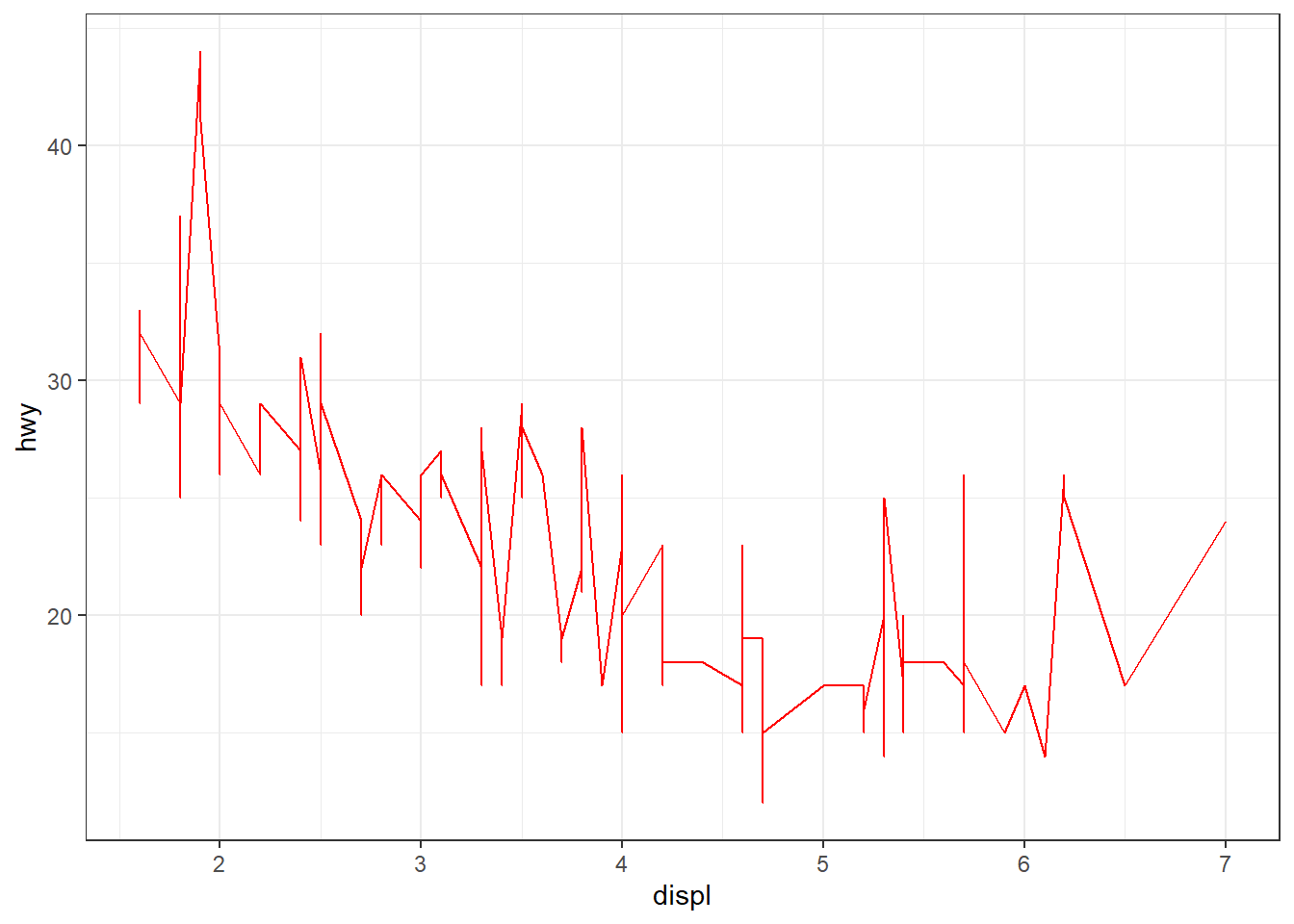
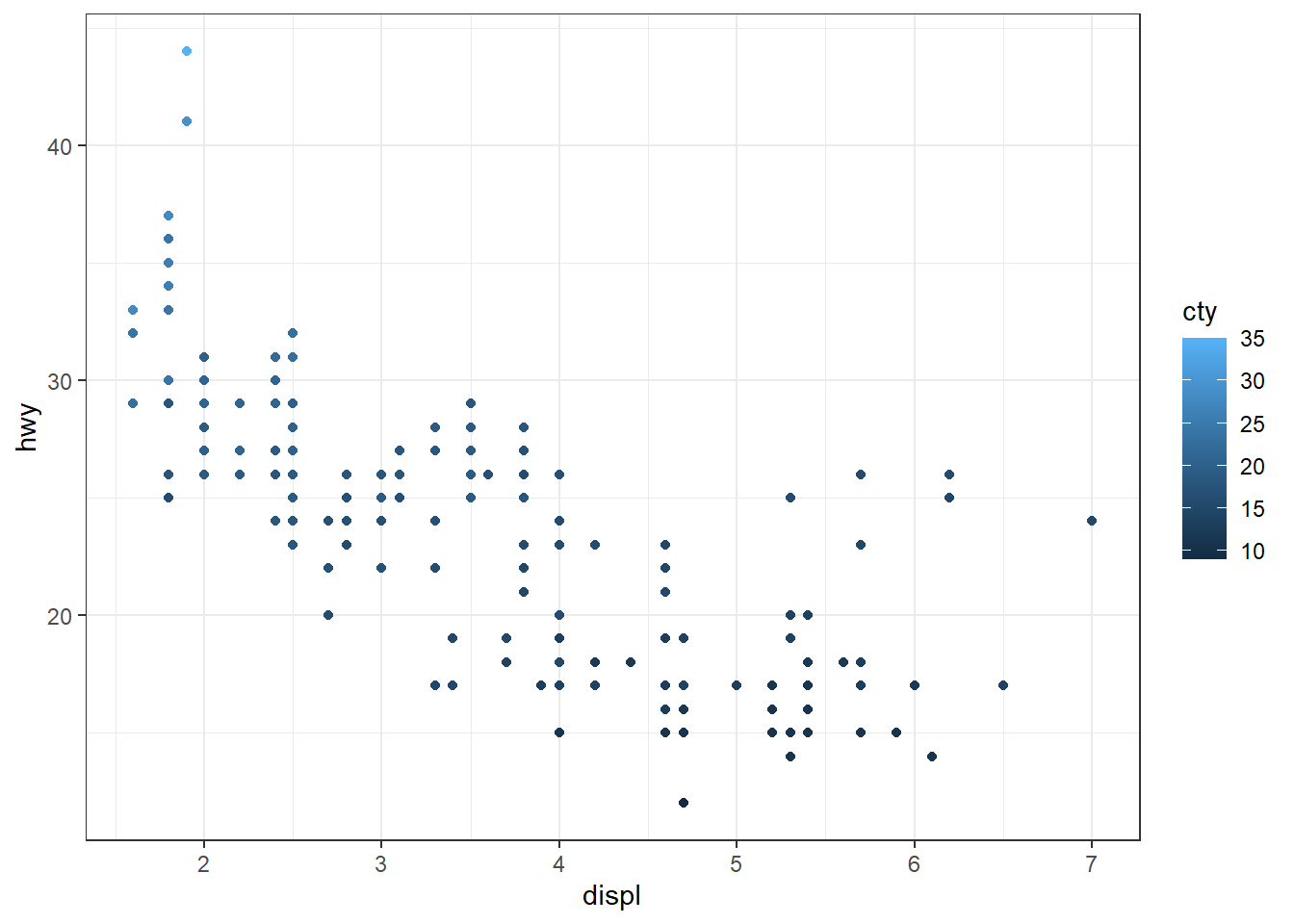
La couleur, comme tous les autres aesthetics, peut être personnalisée grâce aux fonctions scale_*(). Ces fonctions définissent comment les valeurs d’une variable sont traduites en éléments visuels du graphique : elles permettent par exemple d’associer des couleurs précises à des catégories, de créer un gradient pour une variable continue ou encore de choisir une palette adaptée pour améliorer la lisibilité du graphique. Exemple :
# scale_color_manual() : on définit manuellement les couleurs
ggplot(mpg, aes(x = displ, y = hwy)) + geom_line(aes(color = trans)) +
scale_color_manual(values = c("auto" = "steelblue", "manual" = "orange"))
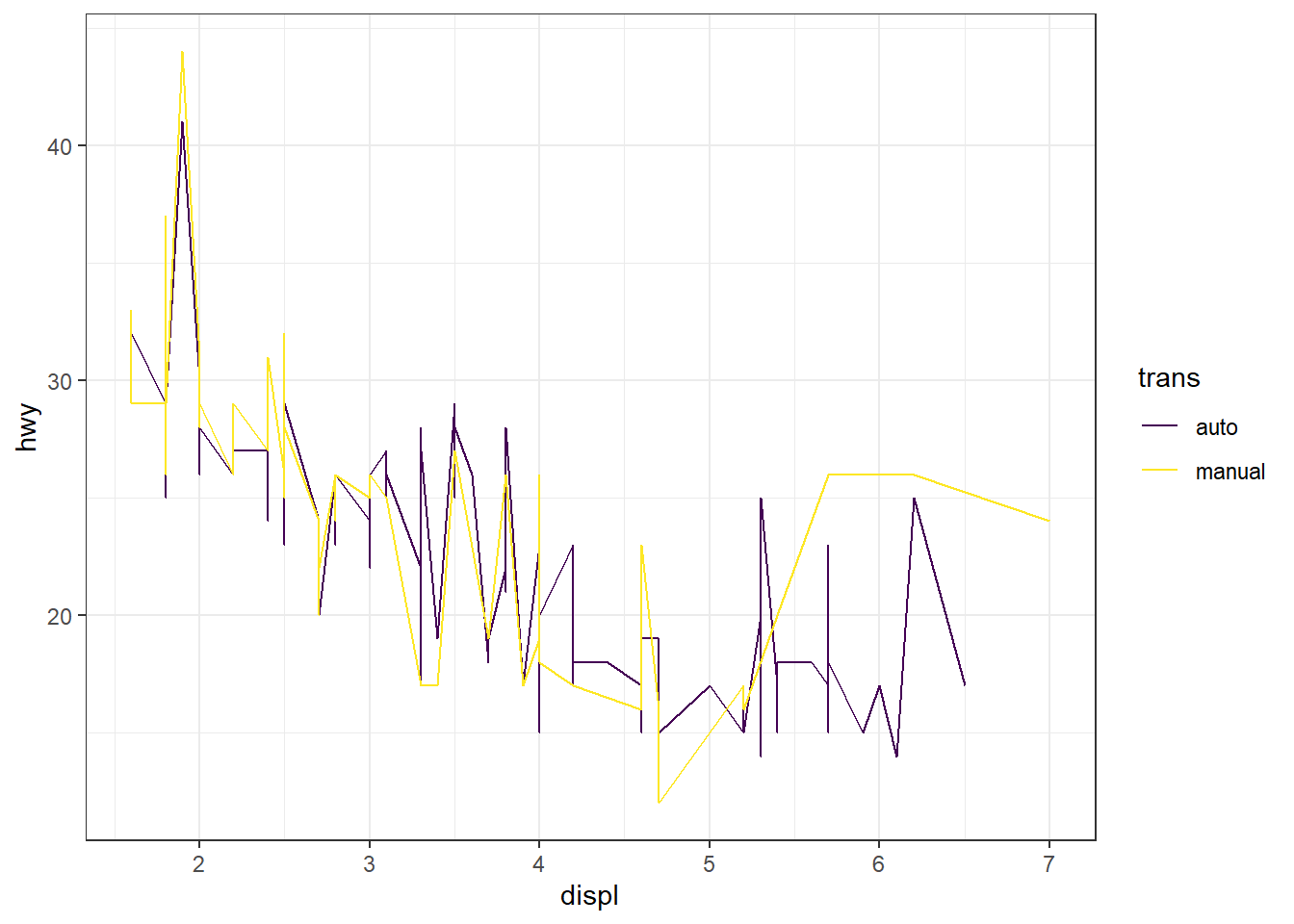
# scale_colour_viridis_d() : palette viridis pour variable discrète.
ggplot(mpg, aes(x = displ, y = hwy)) + geom_line(aes(color = trans)) +
scale_colour_viridis_d()
# scale_color_gradient() : gradient personnalisé pour variable continue.
# low/high définissent les couleurs extrêmes ; n.breaks découpage de la légende
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(color = cty)) +
scale_color_gradient(low = "gray90", high = "gray10", n.breaks = 4)
# scale_colour_viridis_c() : palette viridis pour variable continue.
# direction = -1 inverse le gradient
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(color = cty)) +
scale_colour_viridis_c(direction = -1, n.breaks = 4)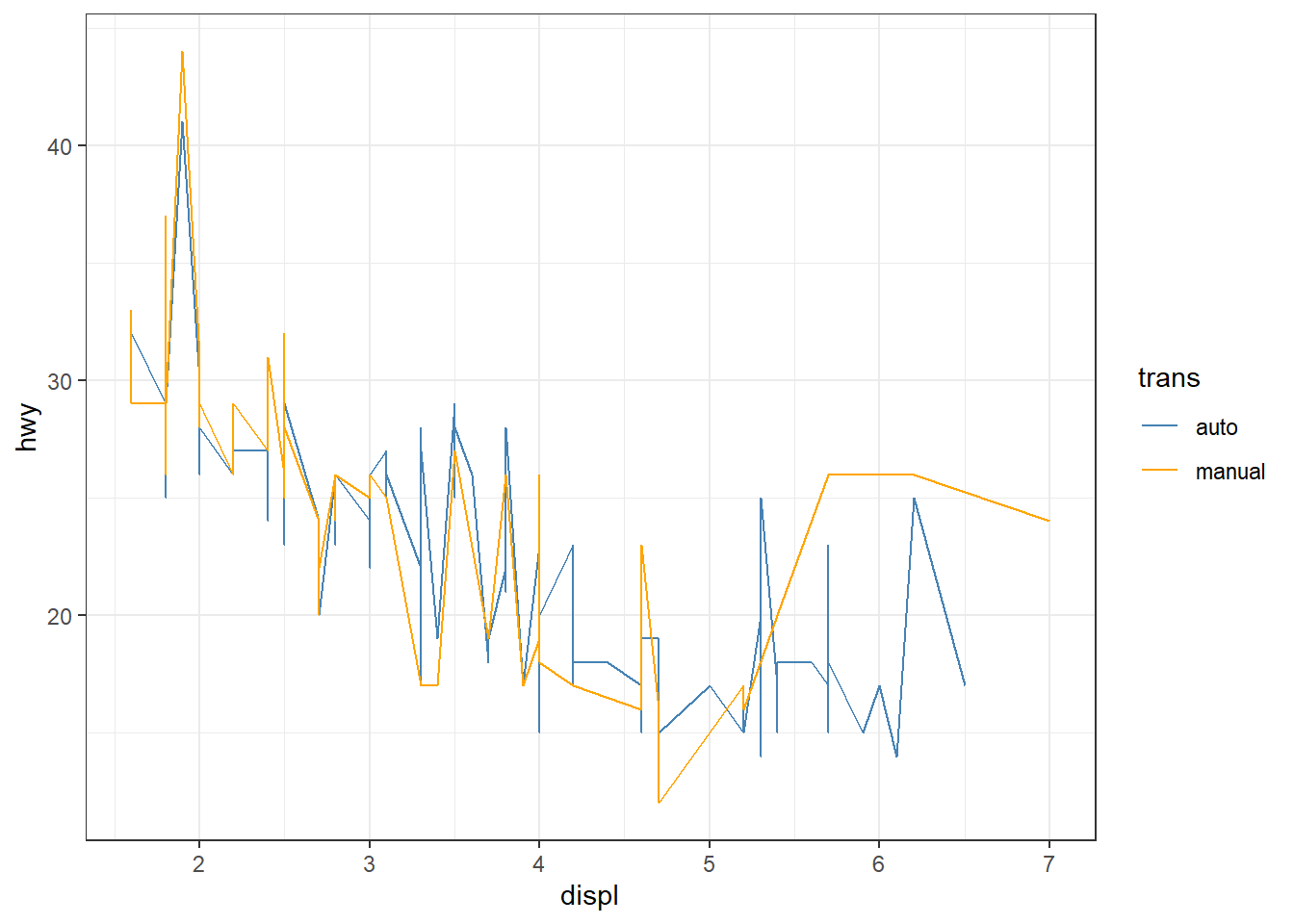
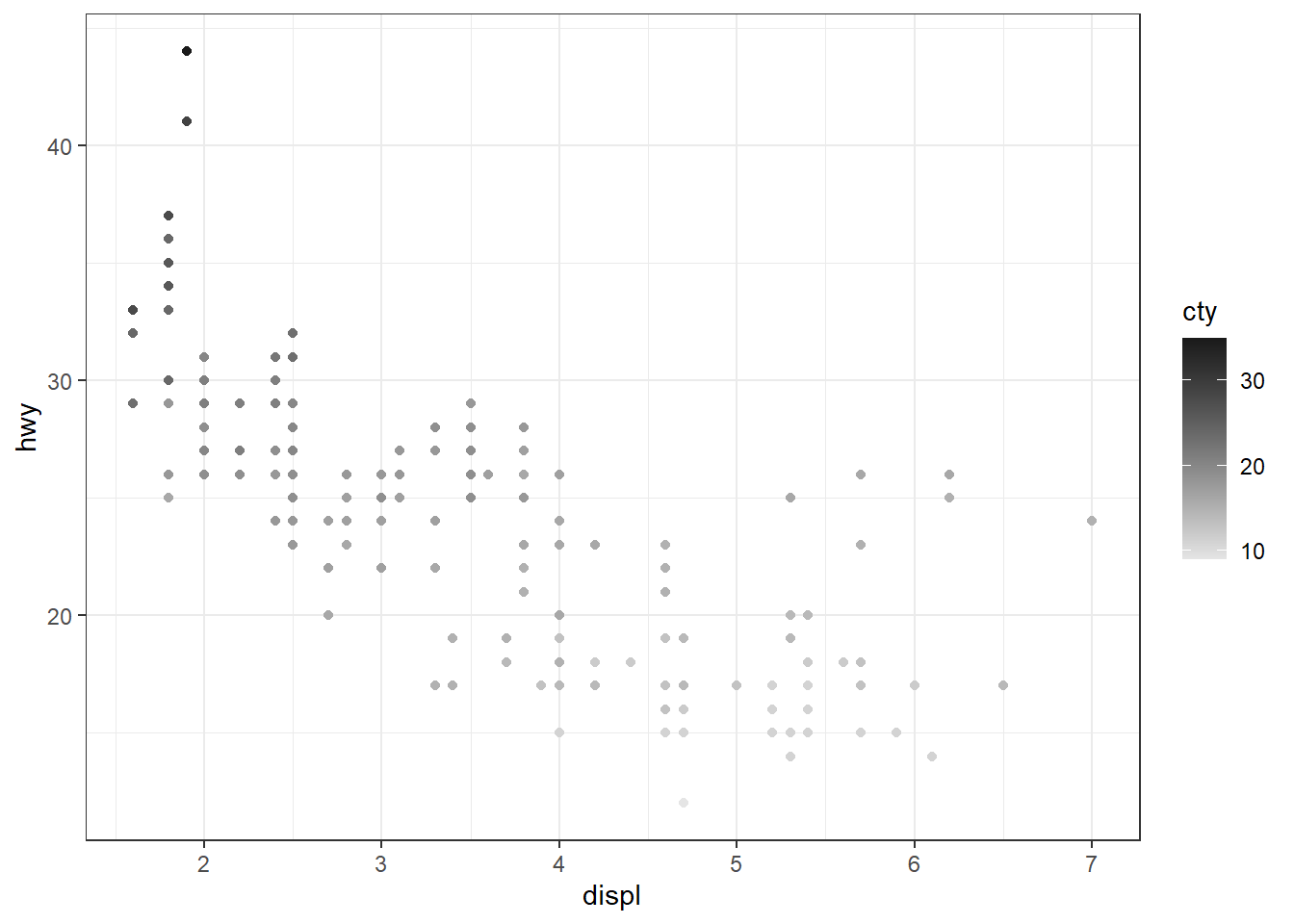
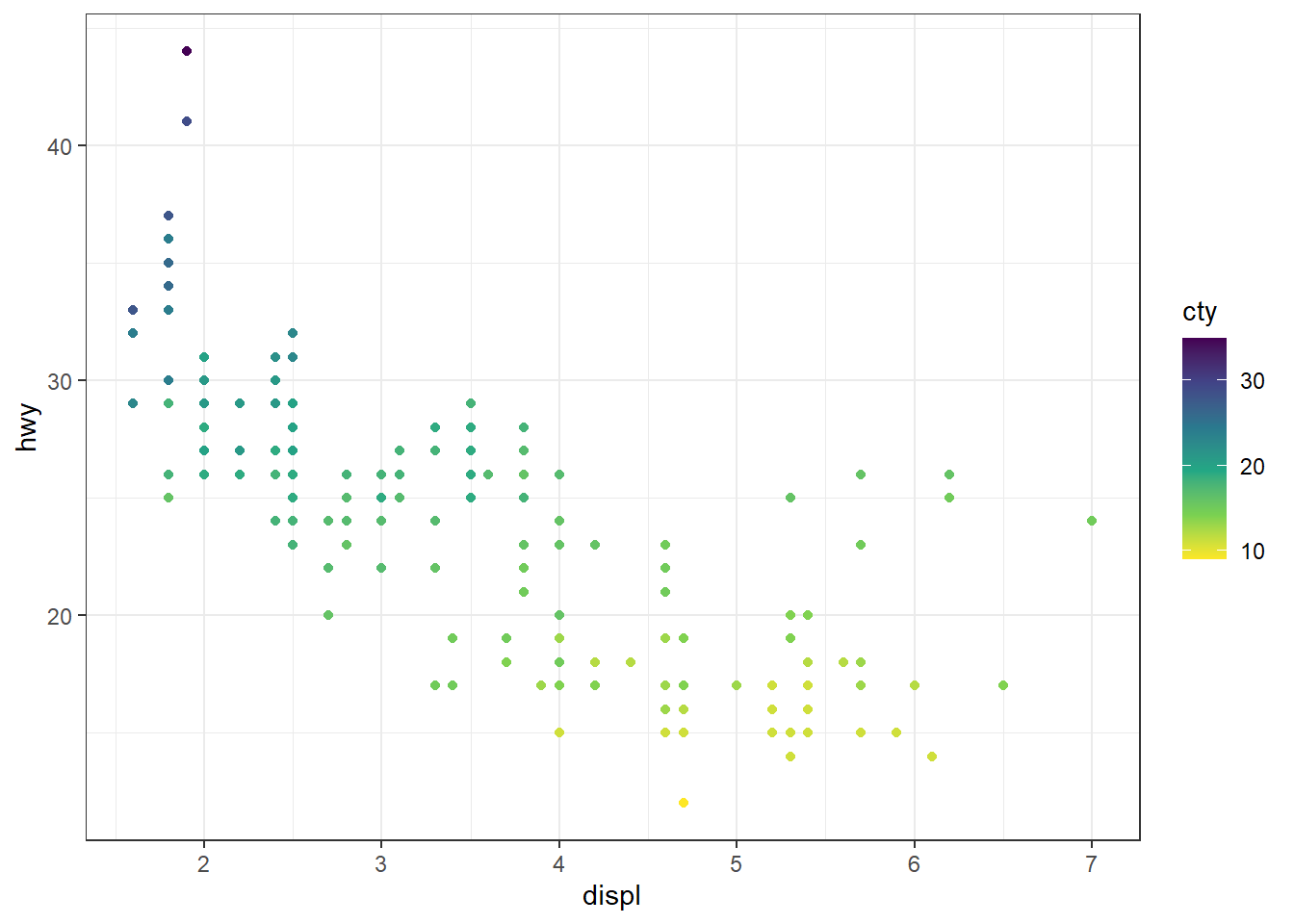
Pour plus de détails, voir https://ggplot2-book.org/scales-colour.html.
size
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(size = 3)
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(aes(size = cty))
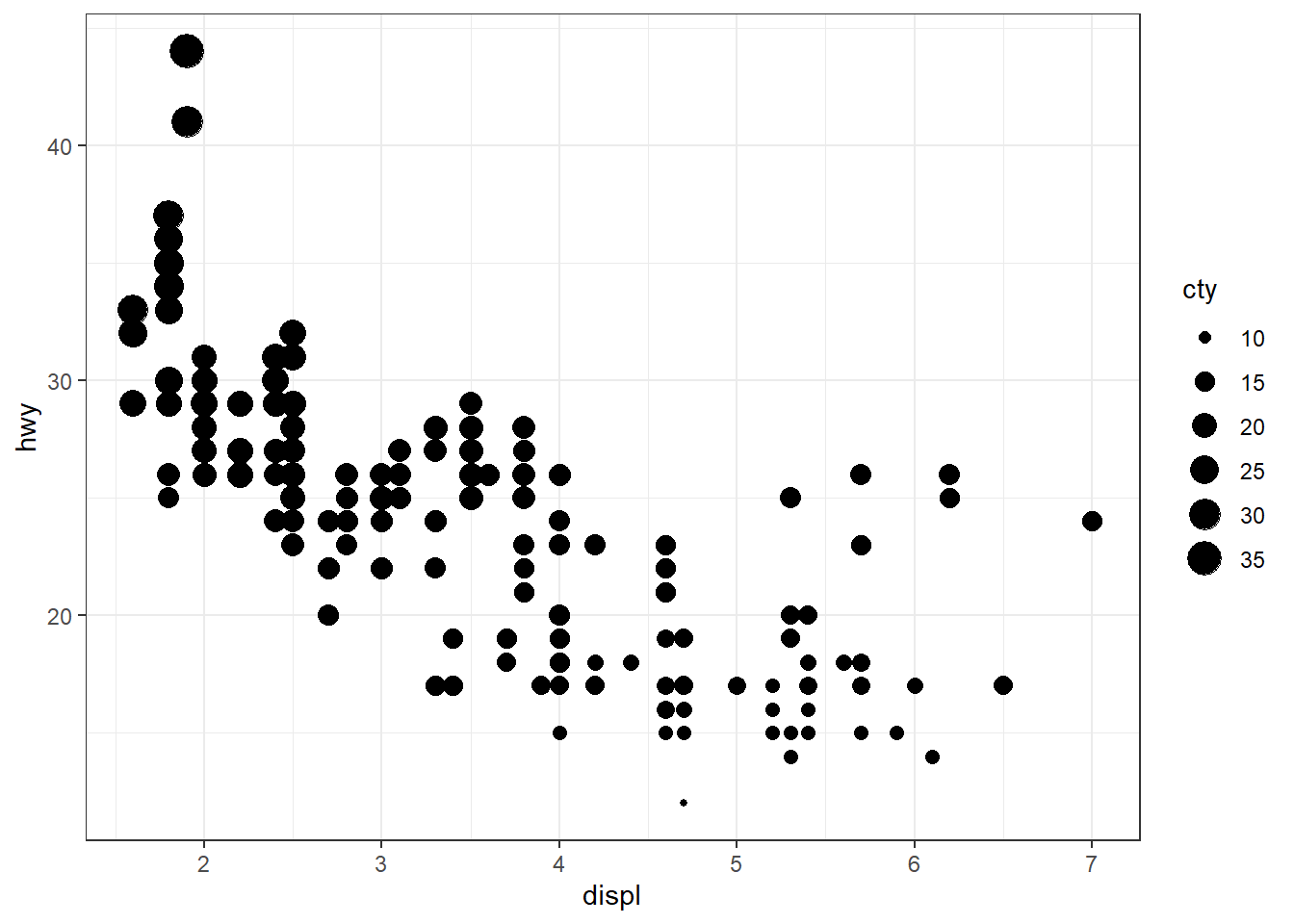
alpha
L’aesthetic alpha permet de régler la transparence des éléments graphiques (points, polygones, etc.). En attribuant une valeur entre 0 (invisible) et 1 (pleinement opaque), on peut visualiser plus clairement les zones de forte densité, notamment dans les cas de chevauchement important entre observations.
Pour mieux comprendre cet aspect, considérant la variable hwy. Cette variable contient beaucoup de valeurs identiques. Par exemple, la valeur 26 apparaît 32 fois (20 fois dans la catégorie trans = 'auto' et 12 dans trans = 'manual').
sum(mpg$hwy == 26)[1] 32Cela sera impossible à voir sur un simple geom_point(), mais plus facile à percevoir avec l’argument alpha.
ggplot(mpg, aes(x = trans, y = hwy)) + geom_point(size = 4)
ggplot(mpg, aes(x = trans, y = hwy)) + geom_point(alpha = 0.1, size = 4)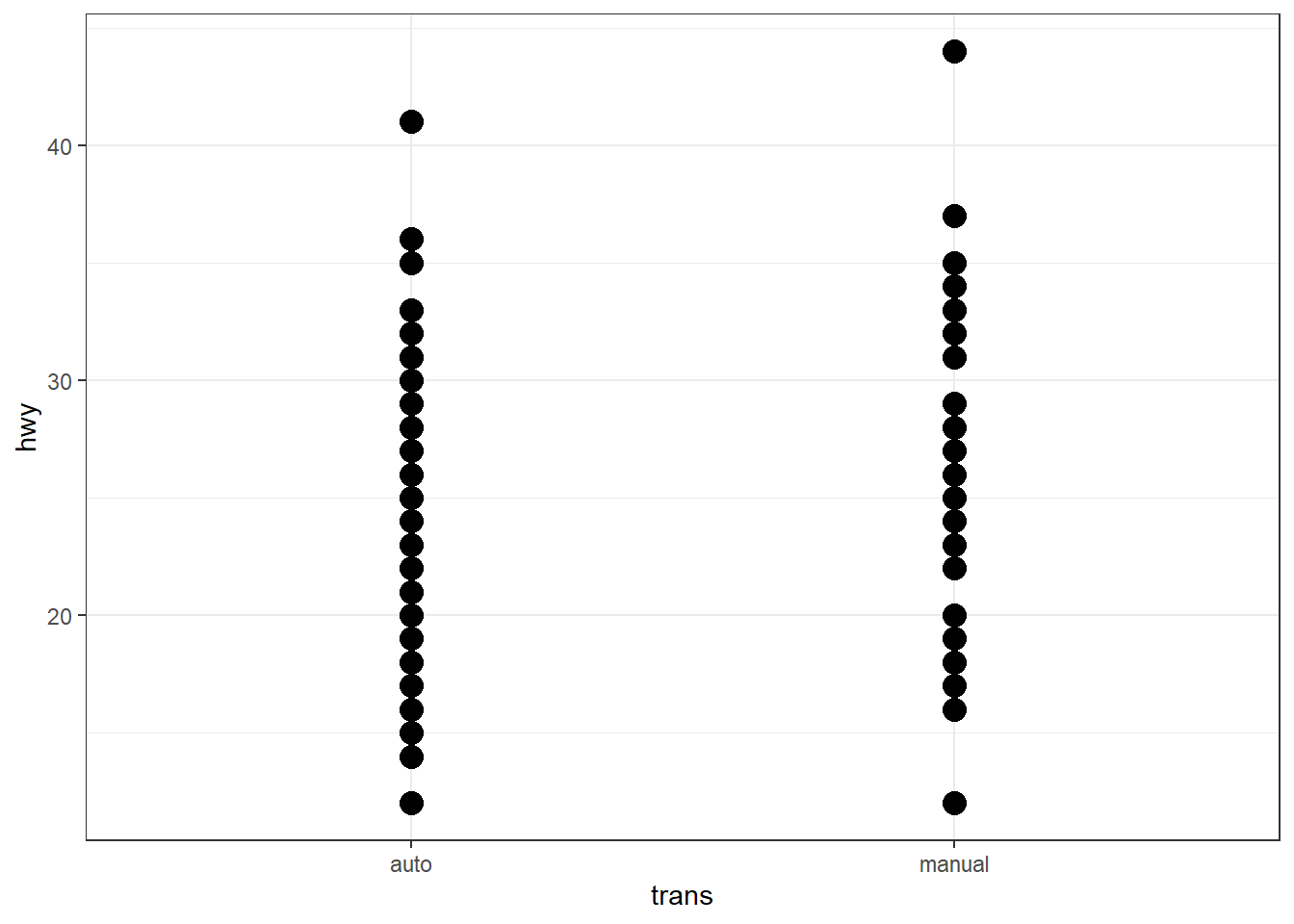
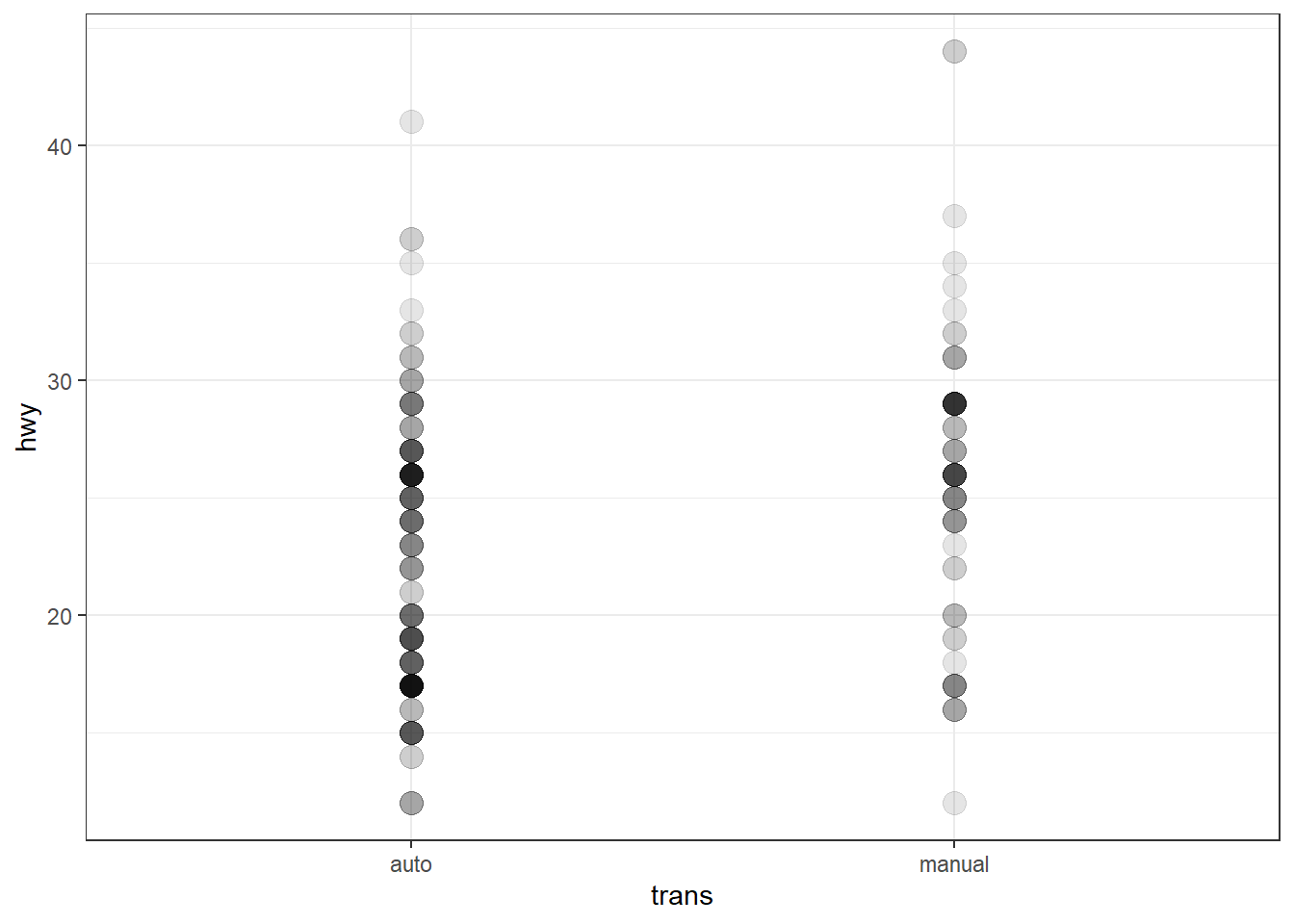
Pour atténuer le chevauchement des points, on peut également recourir à geom_count() ou geom_jitter(); voir Section 12.3.1.
linetype et linewidth
group
L’aesthetic group permet de diviser les données afin qu’elles soient représentées séparément pour chaque groupe, plutôt que comme un seul ensemble. Dans la plupart des cas, le regroupement est appliqué implicitement lorsqu’un mapping est effectué via des aesthetics tels que size, color, shape, linetype, etc. Ainsi, dans le code ci-dessus, aes(linetype = trans) entraîne une division des données en deux groupes, selon les modalités du facteur trans.
Il existe toutefois des situations où l’on souhaite appliquer un regroupement qui ne correspond pas à un aesthetic visible. C’est précisément dans ce cas que où group devient utile. Exemple :
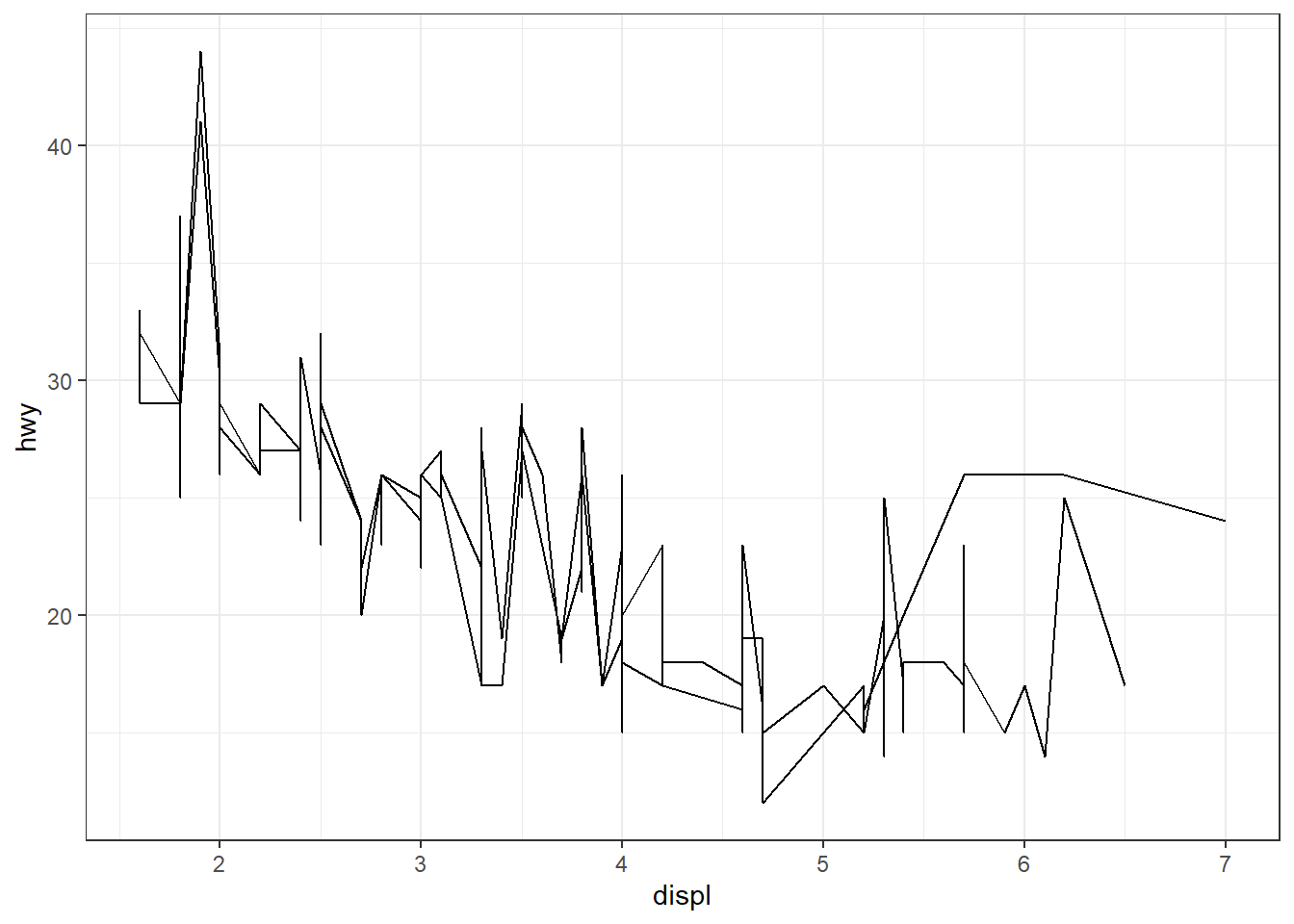
Voici un exemple nettement plus intéressant:
Mapping global vs mapping local
Dans ggplot, il existe deux manières de définir un mapping (aes()) : soit de façon globale, soit de façon locale. Le mapping global est établi dans l’appel à ggplot() et s’applique par défaut à toutes les geoms (geom_<xxx>()) du graphique. À l’inverse, un mapping local est défini directement dans une geom_<xxx>() et ne concerne que celle-ci.
Prenons un exemple de mapping global :
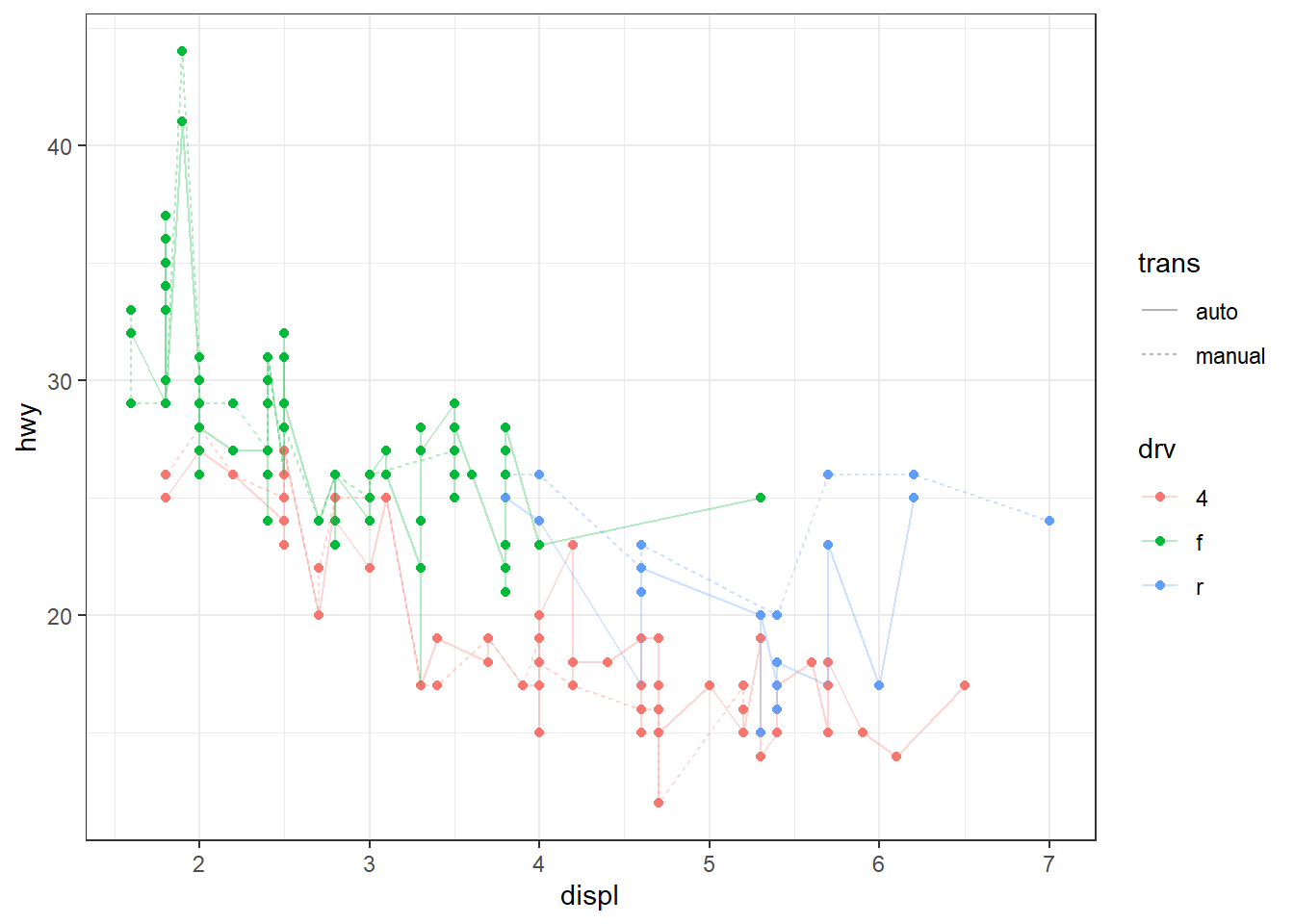
ggplot(mpg, aes(x = displ, y = hwy, color = drv, linetype = trans)) +
geom_point(size = 1.5) +
geom_line(alpha = 0.3)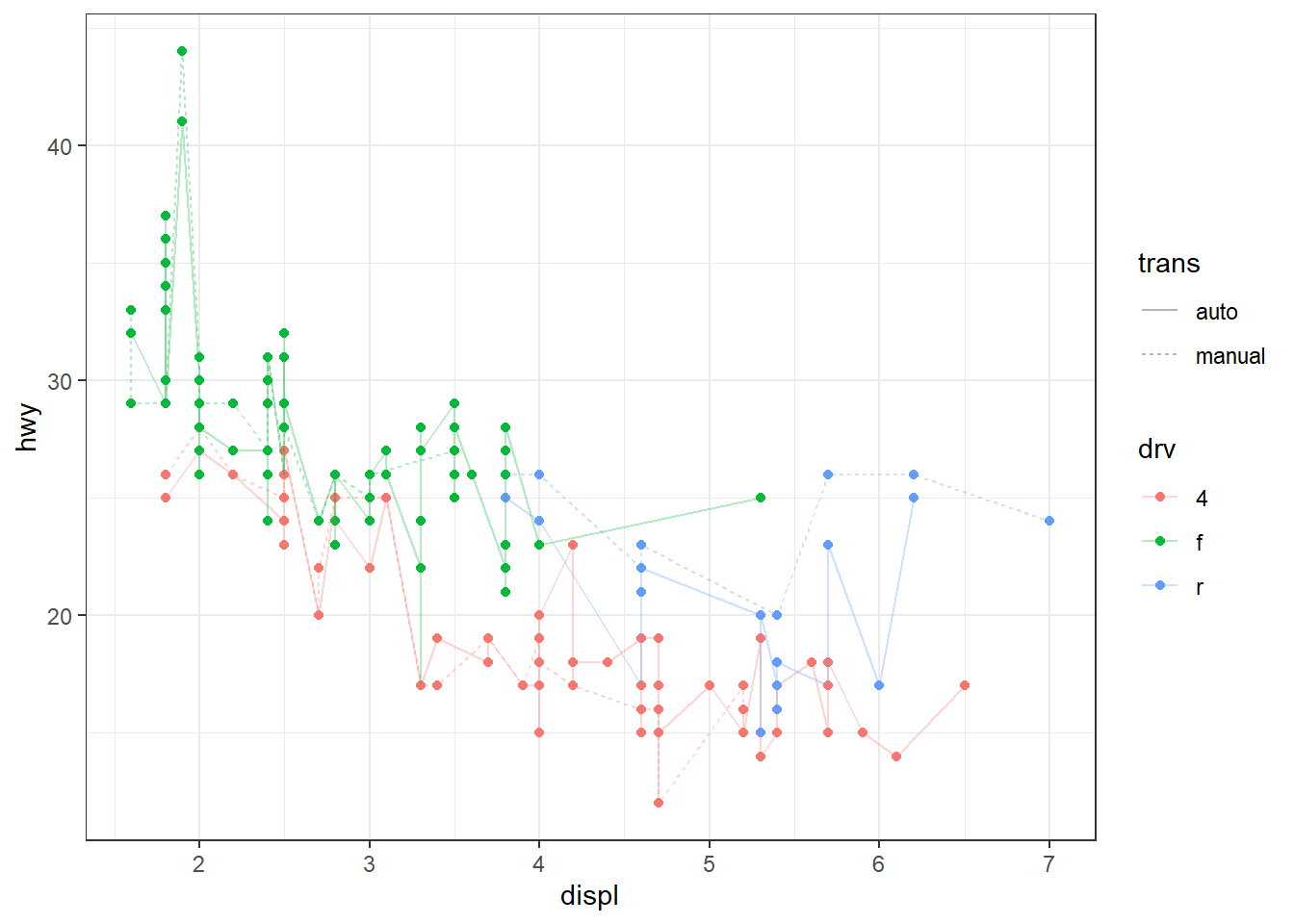
Ici, toutes les geoms (geom_point et geom_line) héritent des aesthetics définis dans ggplot(). Cela permet d’éviter les répétitions et de garder le code concis. Ce graphique peut être réécrit en utilisant des mappings locaux, comme suit :
ggplot(mpg) +
geom_point(aes(x = displ, y = hwy, color = drv), size = 1.5) +
geom_line(aes(x = displ, y = hwy, color = drv, linetype = trans), alpha = 0.3)Bien que cette version soit correcte, elle introduit des redondances et rend le code plus difficile à modifier. Pour cette raison, le mapping global est généralement préférable lorsque plusieurs geoms partagent les mêmes aesthetics.
Il est également possible de combiner les deux approches, en définissant certains aesthetics globalement et d’autres localement. Exemple :
Dans ce cas, x et y sont définis globalement, tandis que color et linetype sont définis localement dans les geoms concernées. Cette approche permet une plus grande flexibilité tout en limitant les répétitions.
Lorsque le même aesthetic est spécifié localement (dans une geom_<xxx>()), il prévaut sur le mapping global. Exemple :
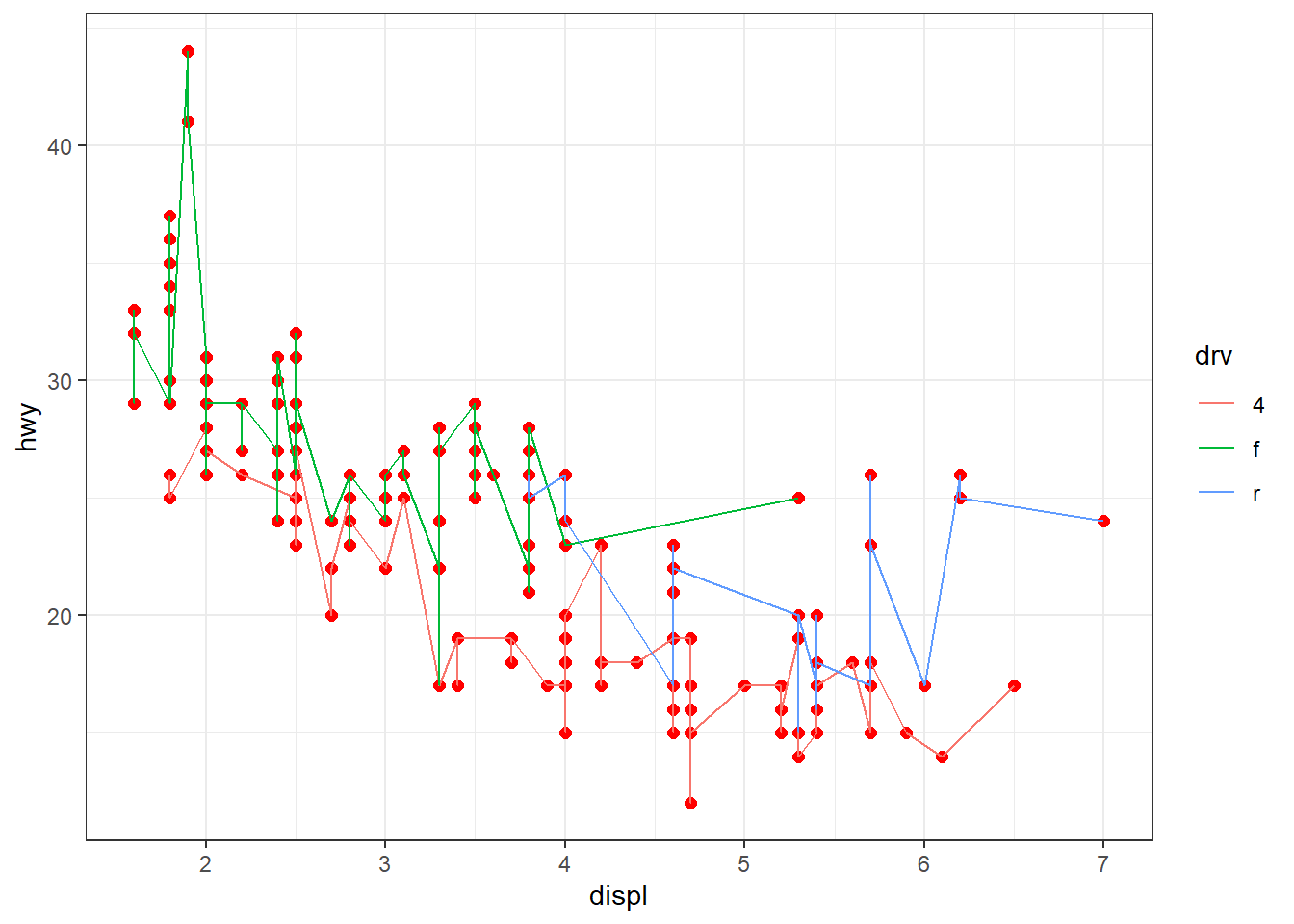
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point(color = "red", size = 2) +
geom_line()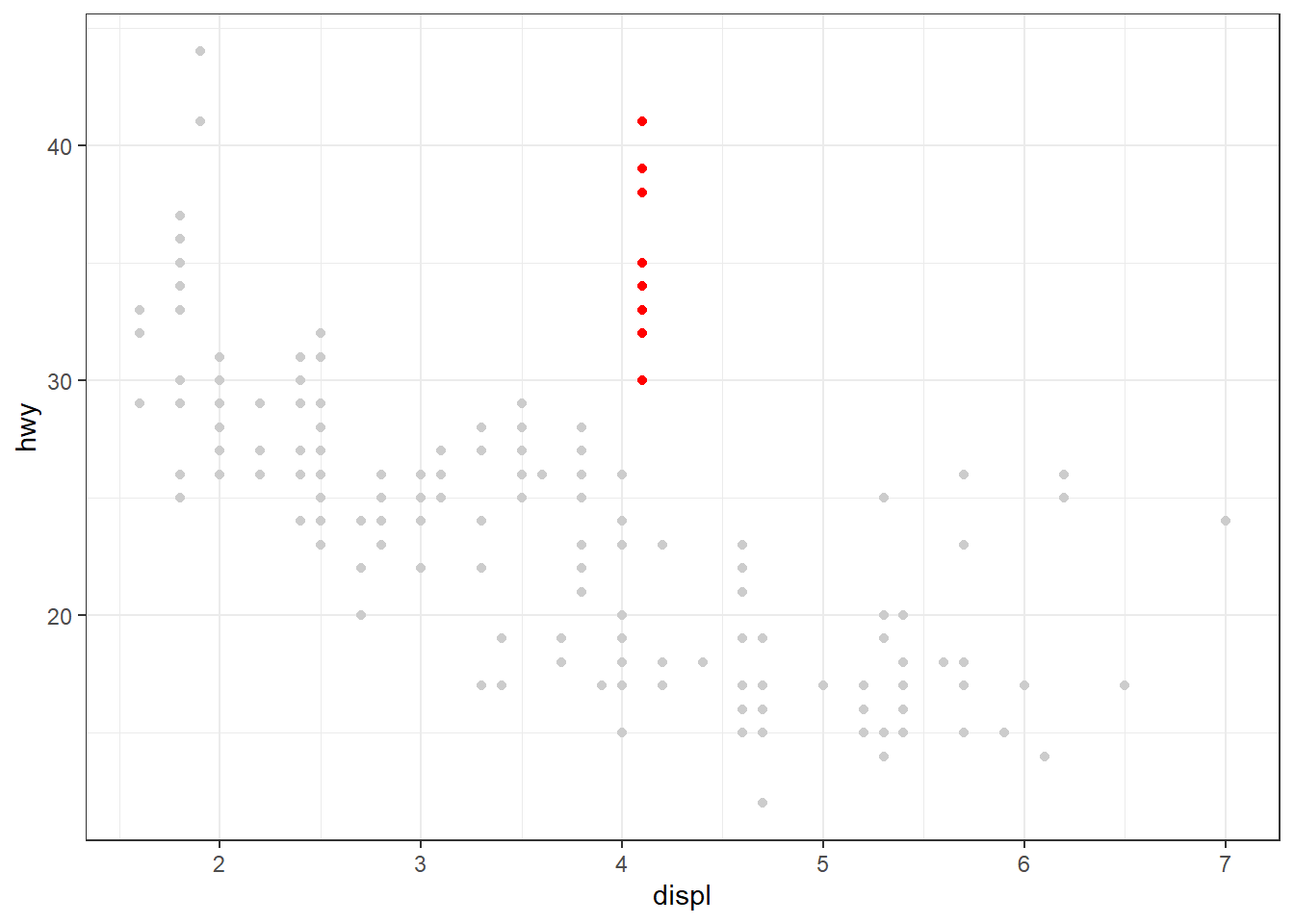
x et y, tout comme l’argument data, peuvent également être définis localement, ce qui autorise chaque geom à utiliser, par exemple, un jeu de données distinct. Voici un exemple illustrant cette possibilité :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point() +
geom_point(data = mpg |> dplyr::summarise(mean.hwy = mean(hwy), mean.displ = mean(displ)),
mapping = aes(x = mean.displ, y = mean.hwy),
color = "red", size = 3)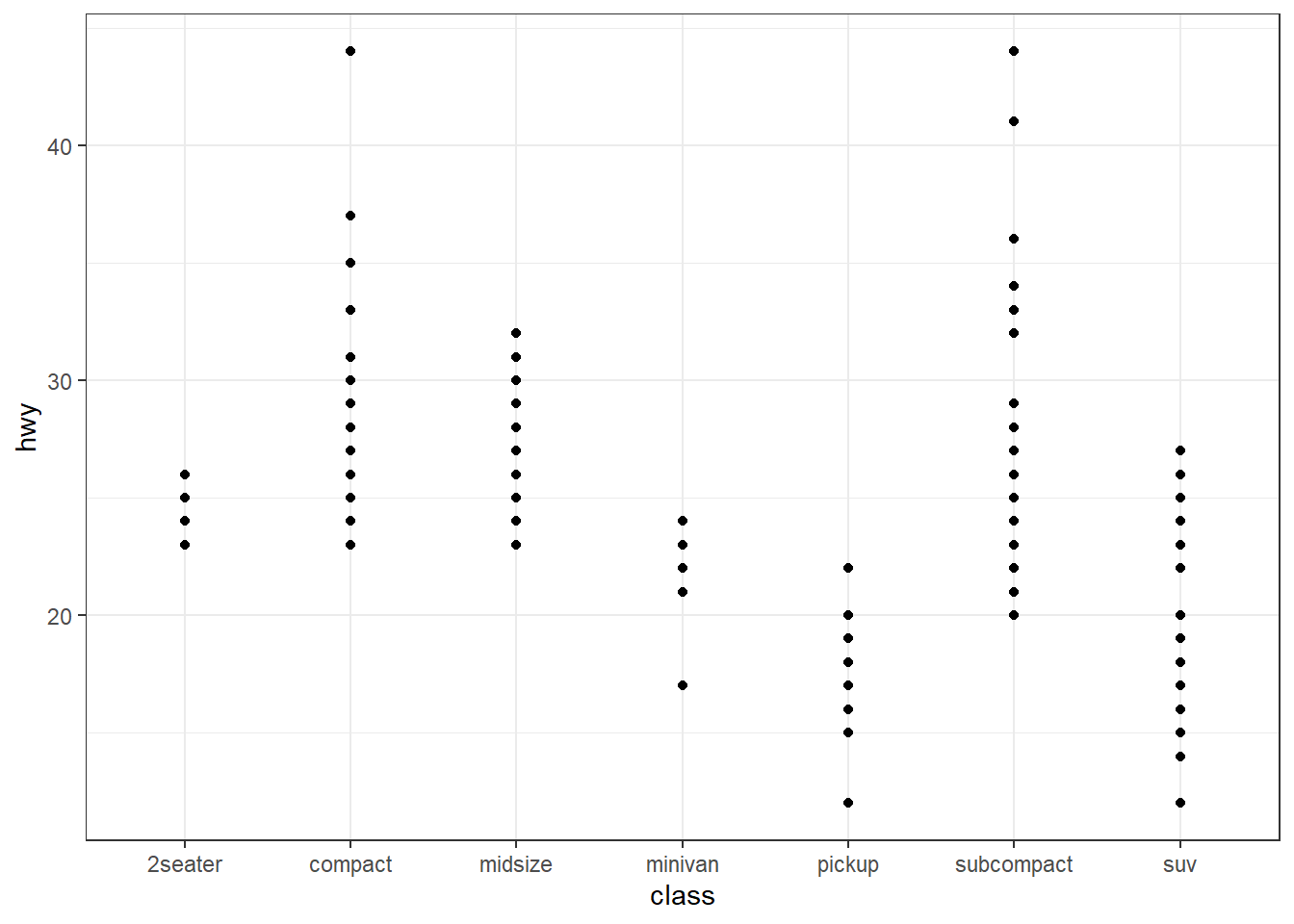
12.3 Fonctions géométriques
Outre geom_point() et geom_line(), que nous avons présentées et utilisées ci-dessus, ggplot propose une vaste gamme de fonctions similaires permettant de représenter ou résumer les données sous des formats variés. Chaque fonction geom_<xxx>() correspond à une géométrie spécifique, càd un type de visualisation spécifique (barres, histogrammes, courbes de densité, boîtes à moustaches, etc.) et dispose de sa propre fiche d’aide en ligne, accompagnée de nombreux exemples illustrant son utilisation.
Vous trouverez la liste complète des fonctions geom_<xxx>() ainsi que leurs fiches d’aide officielles sur le site du ggplot2.
Chaque fonction geom_<xxx>() fait appel, en interne, à une fonction stat_*() qui réalise les calculs ou transformations nécessaires sur les données avant leur représentation graphique. Par exemple, geom_point() et geom_line() utilisent par défaut stat_identity() (aucune transformation : les données sont affichées telles quelles), tandis que geom_boxplot() s’appuie sur stat_boxplot() pour calculer la médiane, les quartiles et les moustaches. Voici quelques points importants à retenir :
-
Chaque fonction
geom_<xxx>()possède un argumentstatqui permet de consulter, ou éventuellement de modifier, la fonctionstat_*()utilisée. Ainsi, dans l’aide degeom_point(), on peut lirestat = "identity", ce qui signifie questat_identity()est utilisée. Au besoin, cette valeur peut être remplacée par une autre fonction stat. Exemple :ggplot(mpg, aes(class, hwy)) + geom_point() ggplot(mpg, aes(class, hwy)) + geom_point(stat = "summary", fun = "mean", size = 3)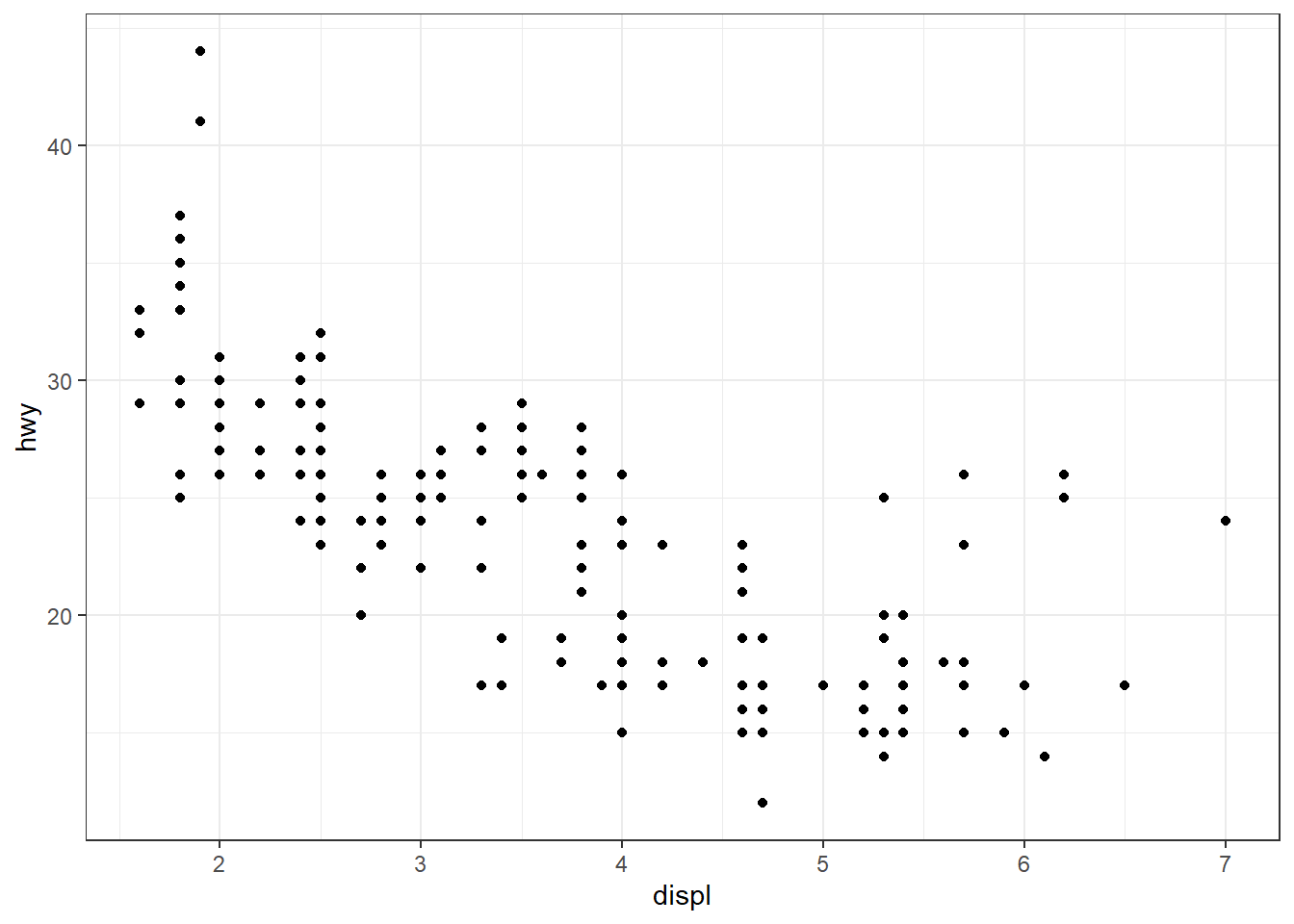
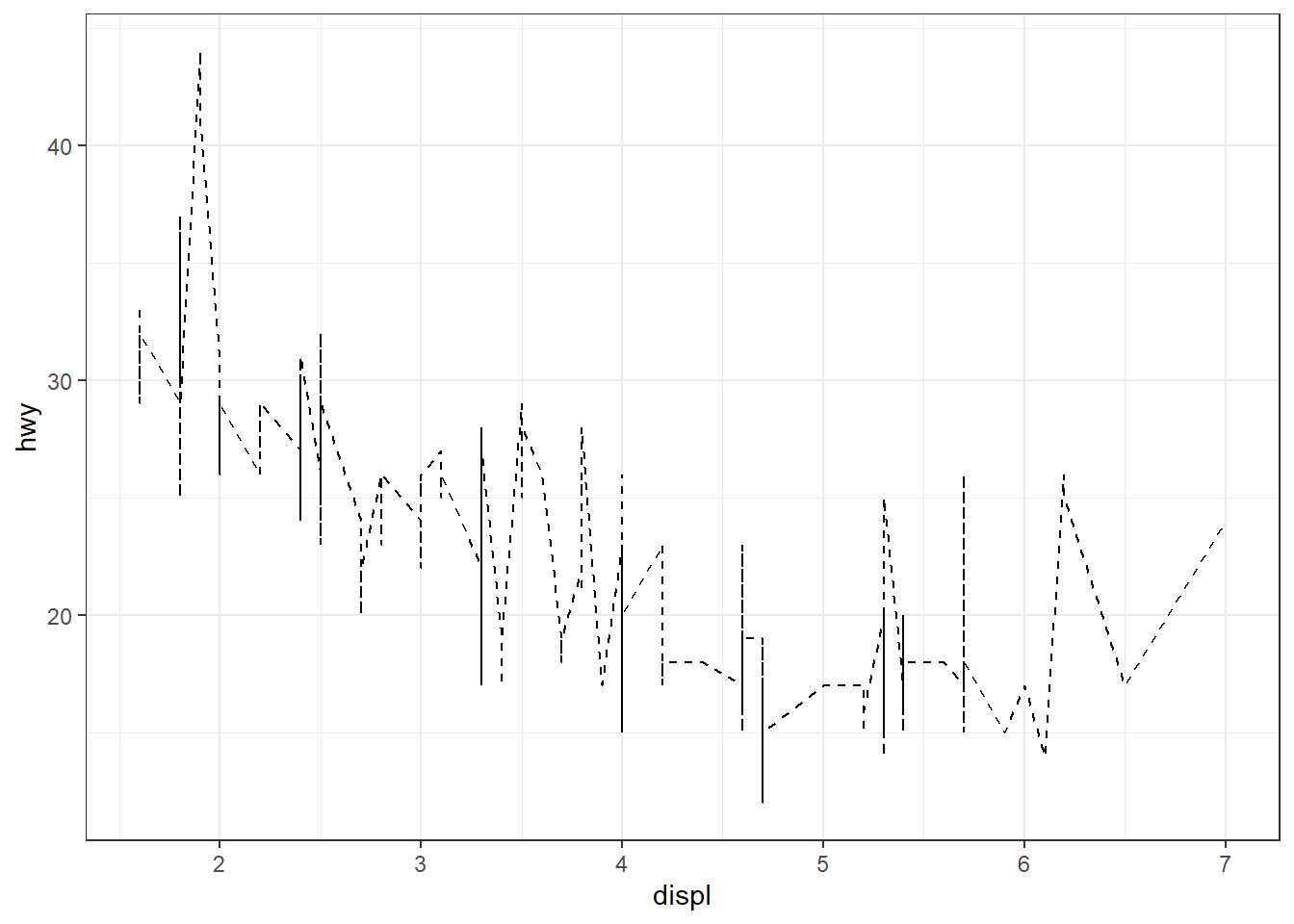
Dans le dernier graphe,
geom_point()utilisestat_summary()à la place destat_identity(). Dans une fonction
geom_<xxx>(), on peut combiner deux types d’arguments : d’une part ceux propres au geom, qui contrôlent l’apparence graphique des objets tracés (par exemplesize = 3), et d’autre part ceux spécifiques à la stat utilisée, qui définissent les calculs ou transformations à réaliser sur les données avant de les représenter (par exemple avecfun = "mean").À l’inverse, chaque
stat_*()admet un argumentgeomqui définit la forme graphique à employer pour représenter le résultat de la transformation statistique. Par exemple,stat_identity()utilisegeom_point()par défaut (voir l’aide). Au besoin, cette valeur peut être remplacée par une autre fonction geom, auquel cas on peut recourir aux arguments spécifiques à ce geom. Exemple :
ggplot(mpg, aes(x = displ, y = hwy)) + stat_identity()
ggplot(mpg, aes(x = displ, y = hwy)) + stat_identity(geom = "line", linetype = "dashed")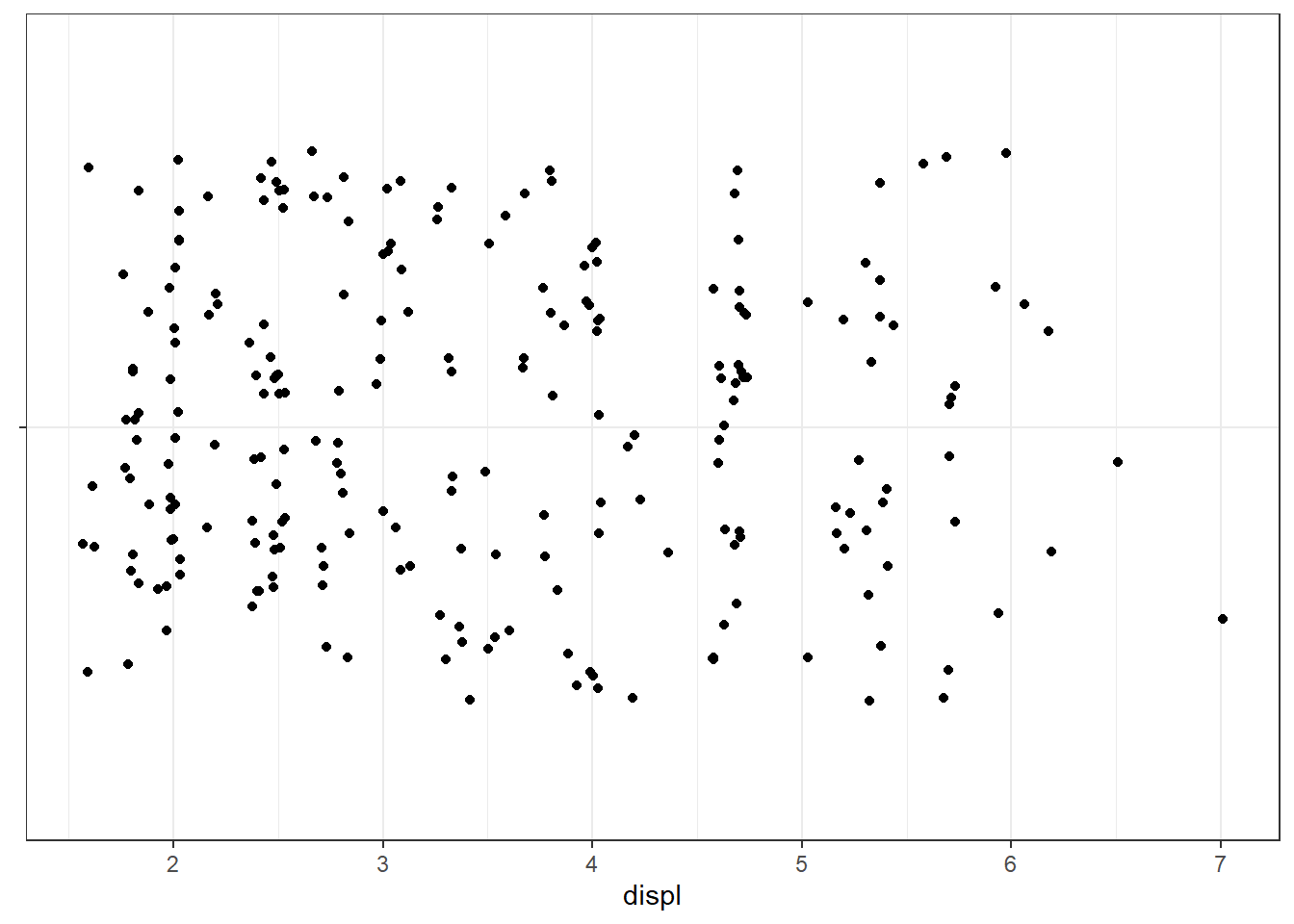
Cette logique offre une grande souplesse pour contrôler à la fois les calculs/transformations et leur représentation graphique. Elle établit aussi une véritable dualité entre geom_<xxx>() et stat_*(), permettant de construire un ggplot aussi bien en partant des fonctions geoms (le cas le plus fréquent) qu’en partant des fonctions stats.
Le tableau suivant présente un récapitulatif des principaux geoms, de leurs arguments et des aesthetics (càd arguments pouvant être mappés via aes()) qui leur sont le plus fréquemment associés. Les aesthetics obligatoires y sont indiqués en gras.
| Fonction | Description de la geom | Aes. ; arguments |
|---|---|---|
| Points et dispersion | ||
geom_point() |
Observations sou forme de points | x, y, color, alpha, shape, size |
geom_jitter() |
geom_point() + dispersion aléatoire |
x, y, color, alpha, shape, size ; width, height |
geom_count() |
Points dont la taille est proportionnelle au nombre d’observations superposées | x, y, color, alpha, shape, size |
| Lignes et tendances | ||
geom_line() |
Lignes reliant les points selon l’ordre des x | x, y, color, alpha, linetype, linewidth, group |
geom_smooth() |
Courbe de tendance lissée selon une méthode statistique (loess, lm, glm, …) | x, y, color, alpha, linetype, linewidth, group ; method, formula, se |
| Barres et colonnes | ||
geom_bar() |
Barres proportionnelles au nombre d’observations par catégorie | x et/ou y, color, alpha, fill ; position, width |
geom_col() |
Variante de geom_bar() avec hauteurs (y) explicites |
x, y, color, alpha, fill ; position, width |
| Distribution | ||
geom_boxplot() |
Boîte(s) à moustaches | x, y, color, alpha, fill ; outliers, varwidth, width |
geom_histogram() |
Histogramme | x, color, alpha, fill ; binwidth, bins, breaks |
geom_density() |
Courbe de densité estimée | x, color, alpha, fill, linetype, linewidth ; bw, adjust, kernel |
geom_violin() |
Boxplot enrichi sous forme de densité | x, y, color, alpha, fill, linetype, linewidth ; bw, adjust, kernel, quantile.linetype, trim |
| Texte et annotations | ||
geom_text() |
Affiche du texte (label) à des coordonnées données | x, y, label, color, alpha, size ; angle, hjust, vjust, check_overlap |
| Fonctions et résumés | ||
stat_summary() |
Résumé statistique (moyenne, médiane, etc.) | x, y ; geom, fun, fun.args |
stat_function() |
Évalue/trace une fonction mathématique | x, y ; geom, fun, args, xlim |
Dans la suite de cette section, nous passerons brièvement en revue les geoms les plus couramment utilisés, à l’exception de geom_point() et de geom_line(), déjà présentés ci‑dessus.
geom_jitter() et geom_count()
La fonction geom_jitter() est une variante de geom_point(). Elle sert à représenter des points, mais en leur ajoutant un bruit aléatoire (jitter) sur l’axe des abscisses et/ou des ordonnées. Ce procédé permet de déplacer légèrement les points afin de réduire le problème de chevauchement, très fréquent lorsque plusieurs observations ont (presque) les mêmes coordonnées.
Par défaut, geom_jitter() ajoute un bruit horizontal et vertical. On peut contrôler l’amplitude du bruit avec les arguments width (pour l’axe x) et height (pour l’axe y).
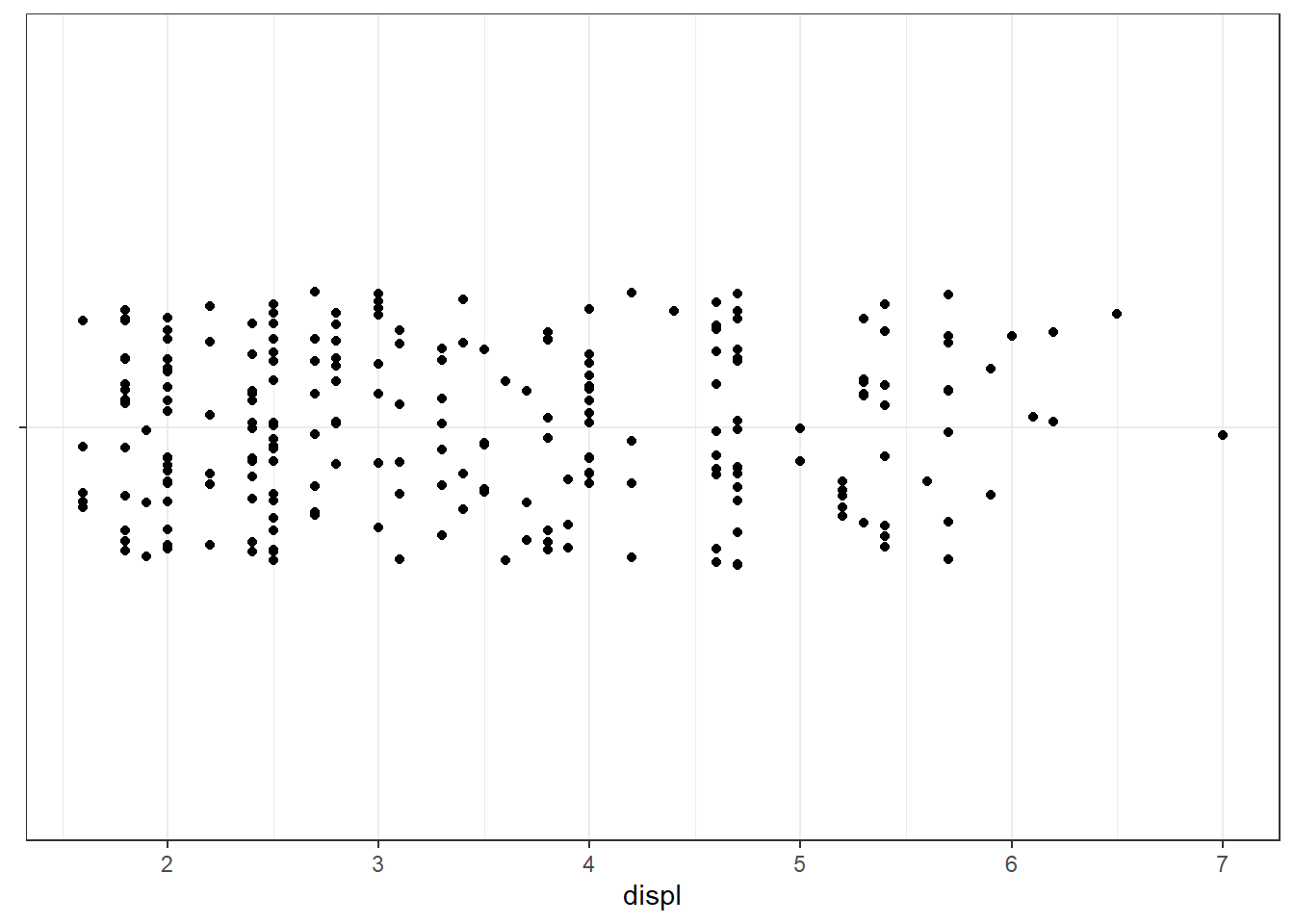
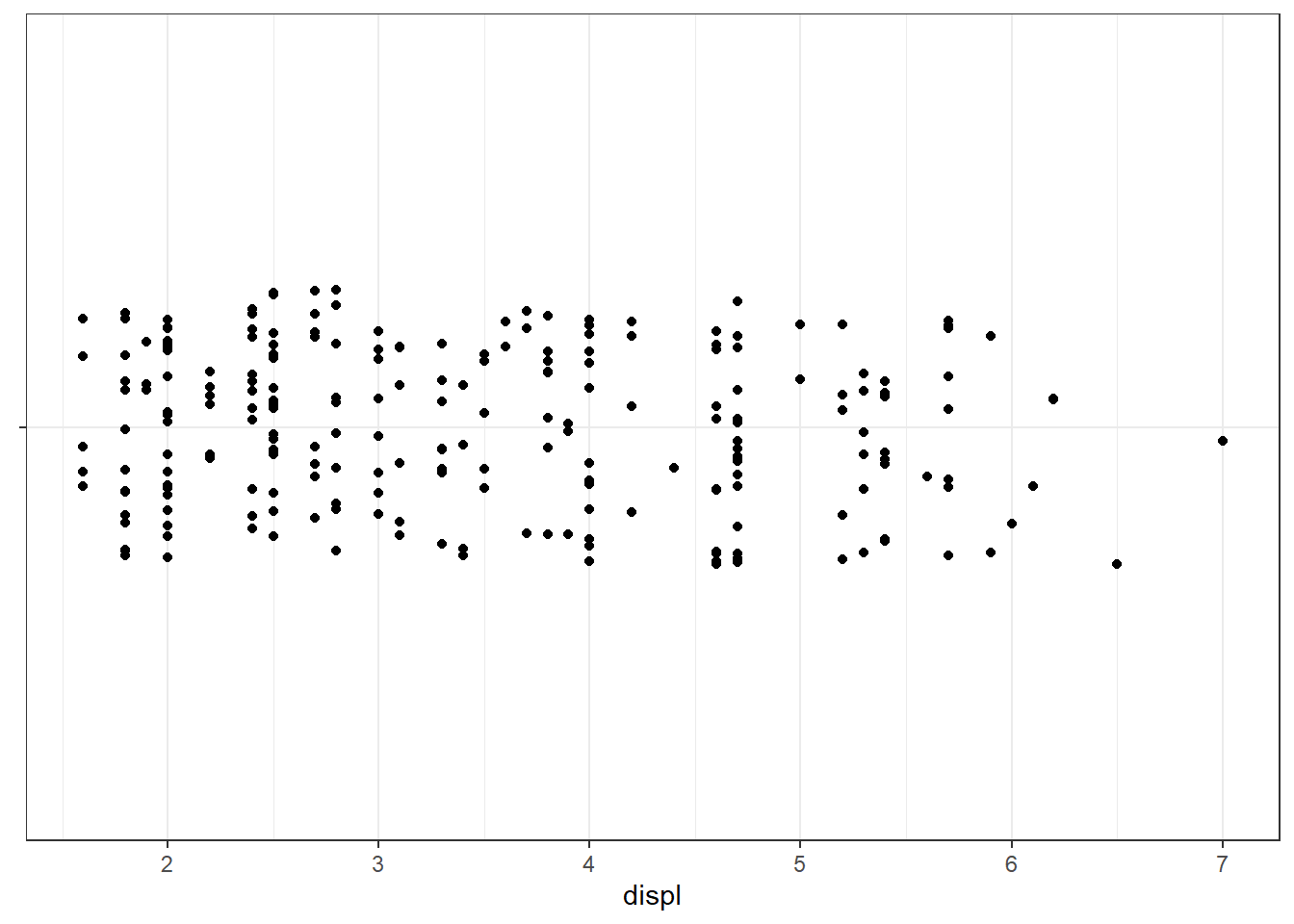
# Bruit horizontal et vertical
ggplot(mpg, aes(x = displ, y = "")) +
geom_jitter() +
labs(y = NULL)
# Bruit uniquement vertical (les points restent alignés en x)
ggplot(mpg, aes(x = displ, y = "")) +
geom_jitter(width = 0, height = 0.2) +
labs(y = NULL)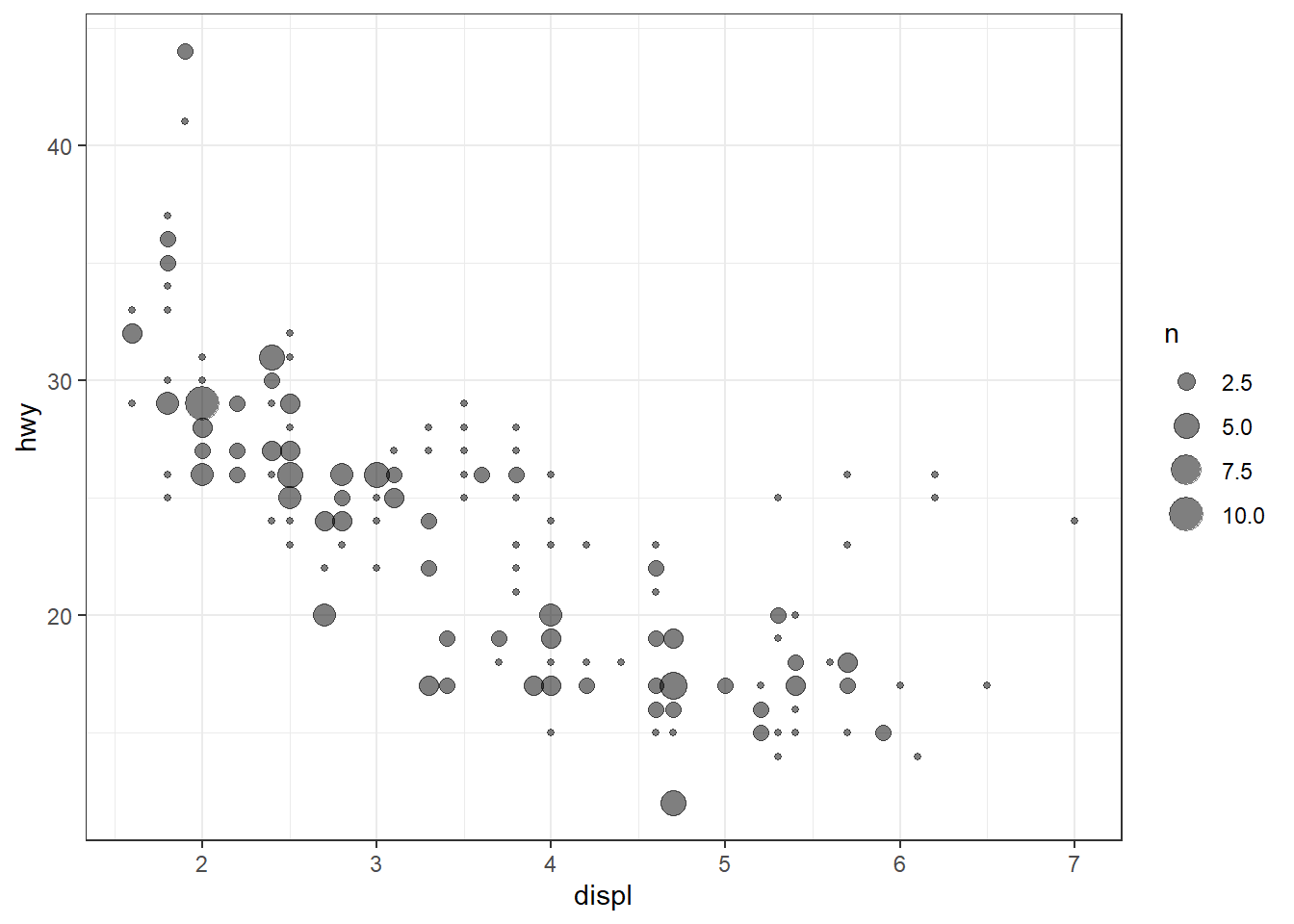
Une autre fonction utile pour contourner le problème de chevauchement est geom_count() qui agrège les points identiques et ajuste automatiquement leur taille en fonction du nombre d’occurrences. Ainsi, au lieu d’avoir une masse illisible de points superposés, on obtient un seul symbole dont la surface reflète la fréquence des données à cette position. Exemple :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_count(alpha = 0.5)
geom_boxplot() et stat_summary()
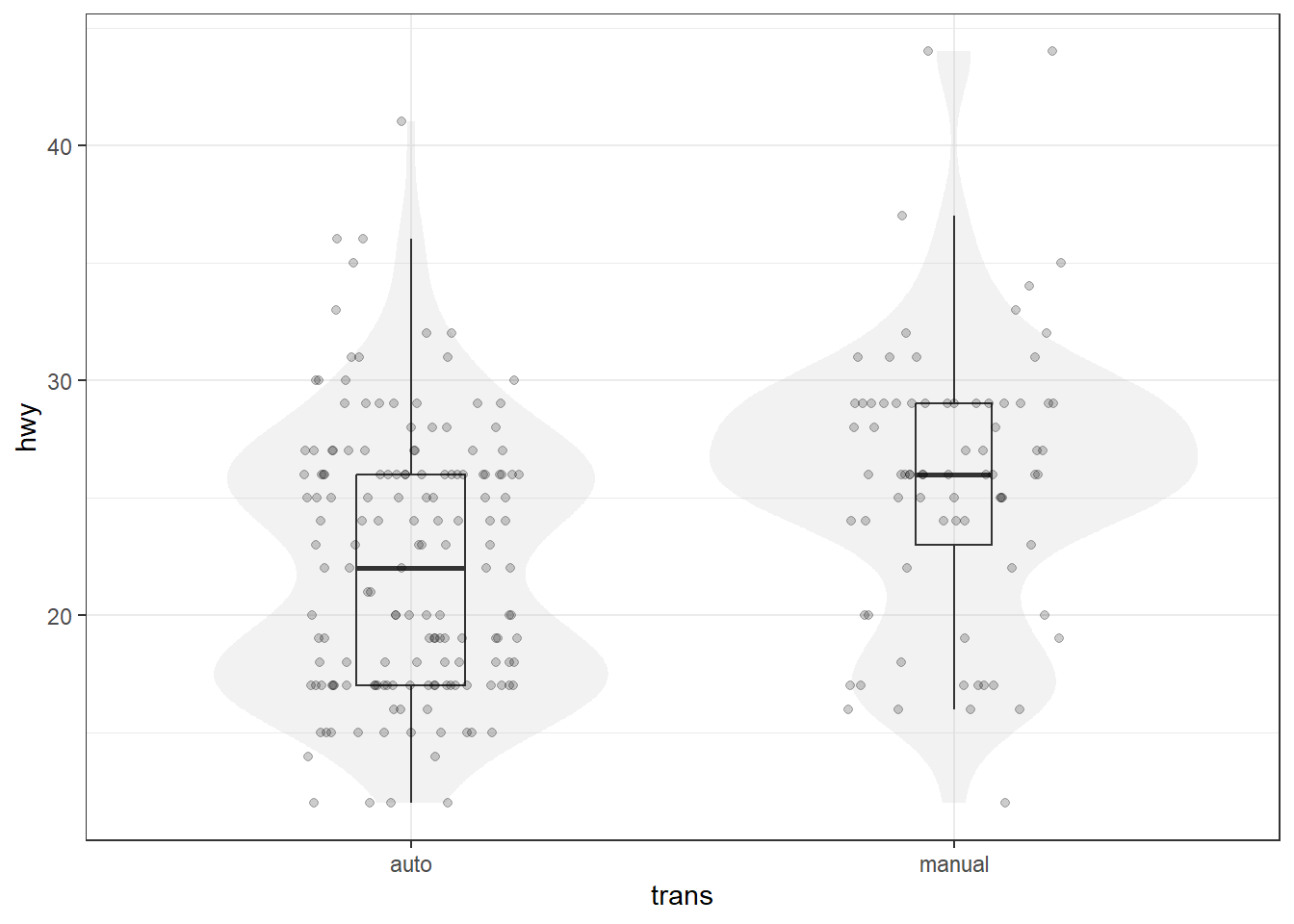
Comme son nom l’indique, geom_boxplot() sert à tracer des boîtes à moustaches (boxplots). Parmi les arguments les plus utiles, on trouve width, qui contrôle la largeur des boîtes (ex. width = 0.5 → les boîtes occupent la moitié de la largeur), varwidth = TRUE, qui ajuste cette largeur en fonction du nombre d’observations par groupe (par défaut la largeur est fixe), fill, qui définit la couleur de remplissage de la boîte, color, qui détermine la couleur des contours (boîte et moustaches), et outliers = FALSE qui supprime l’affichage des outliers; voir ?geom_boxplot pour plus d’info.
# Boxplot de hwy (consommation sur autoroute)
ggplot(mpg, aes(x = "", y = hwy)) + geom_boxplot() + labs(x = NULL)
# Boxplot de hwy par type de transmission (trans) + geom_jitter + stat_summary
ggplot(mpg, aes(x = trans, y = hwy)) +
geom_boxplot(color = "darkblue", fill = NA, varwidth = TRUE, outliers = FALSE) +
geom_jitter(alpha = 0.2, size = 2, width = 0.1, height = 0) +
stat_summary(fun = mean, geom = "point", shape = "+", size = 5, color = "red")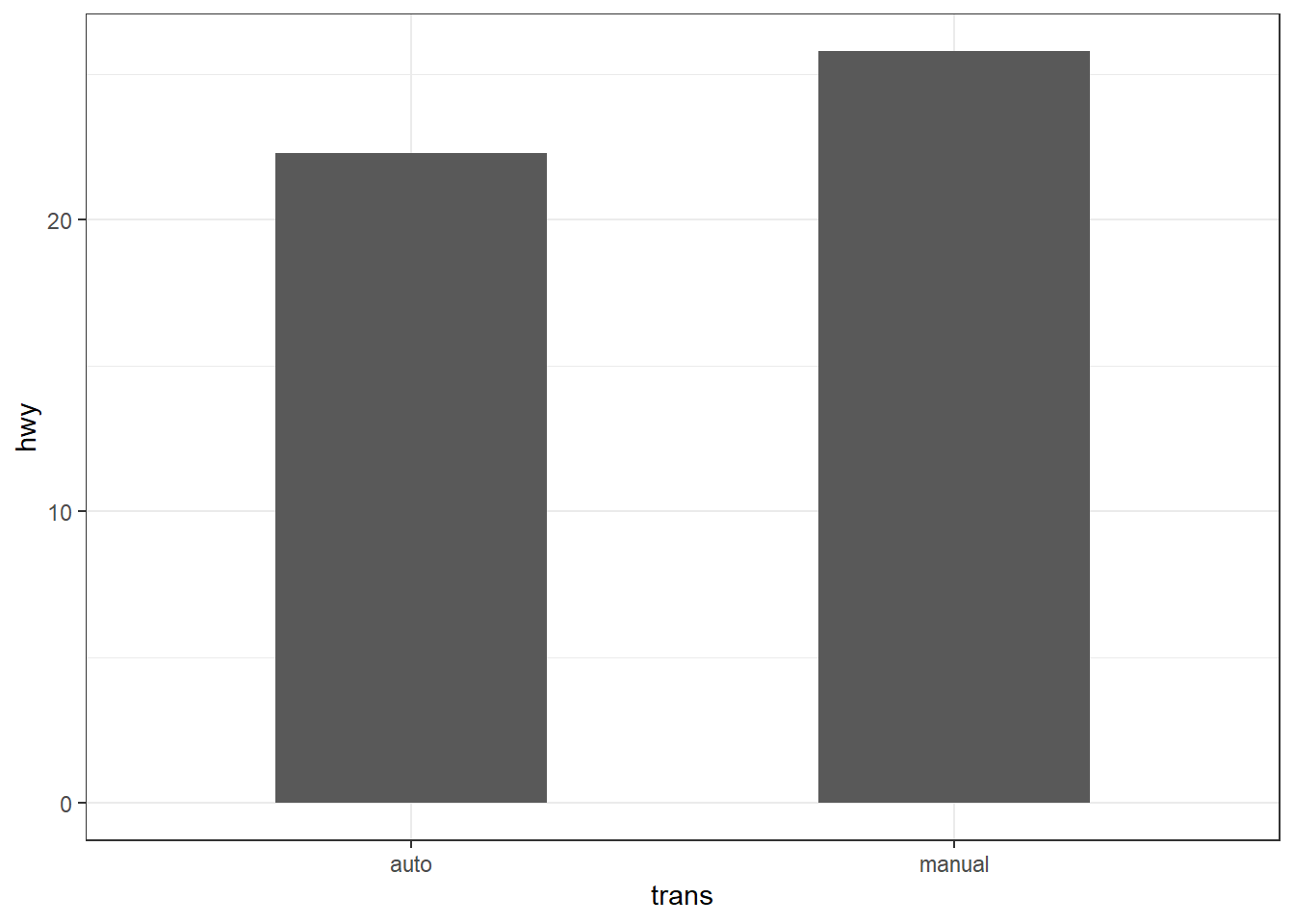
Dans la dernière ligne du code ci‑dessus, nous faisons appel à stat_summary() afin d’ajouter les moyennes par groupe. Notez que cette fonction stat_summary() peut également être utilisée seule. Exemple :
ggplot(mpg, aes(x = trans, y = hwy)) + stat_summary(fun = mean, geom = "bar", width = 0.5)
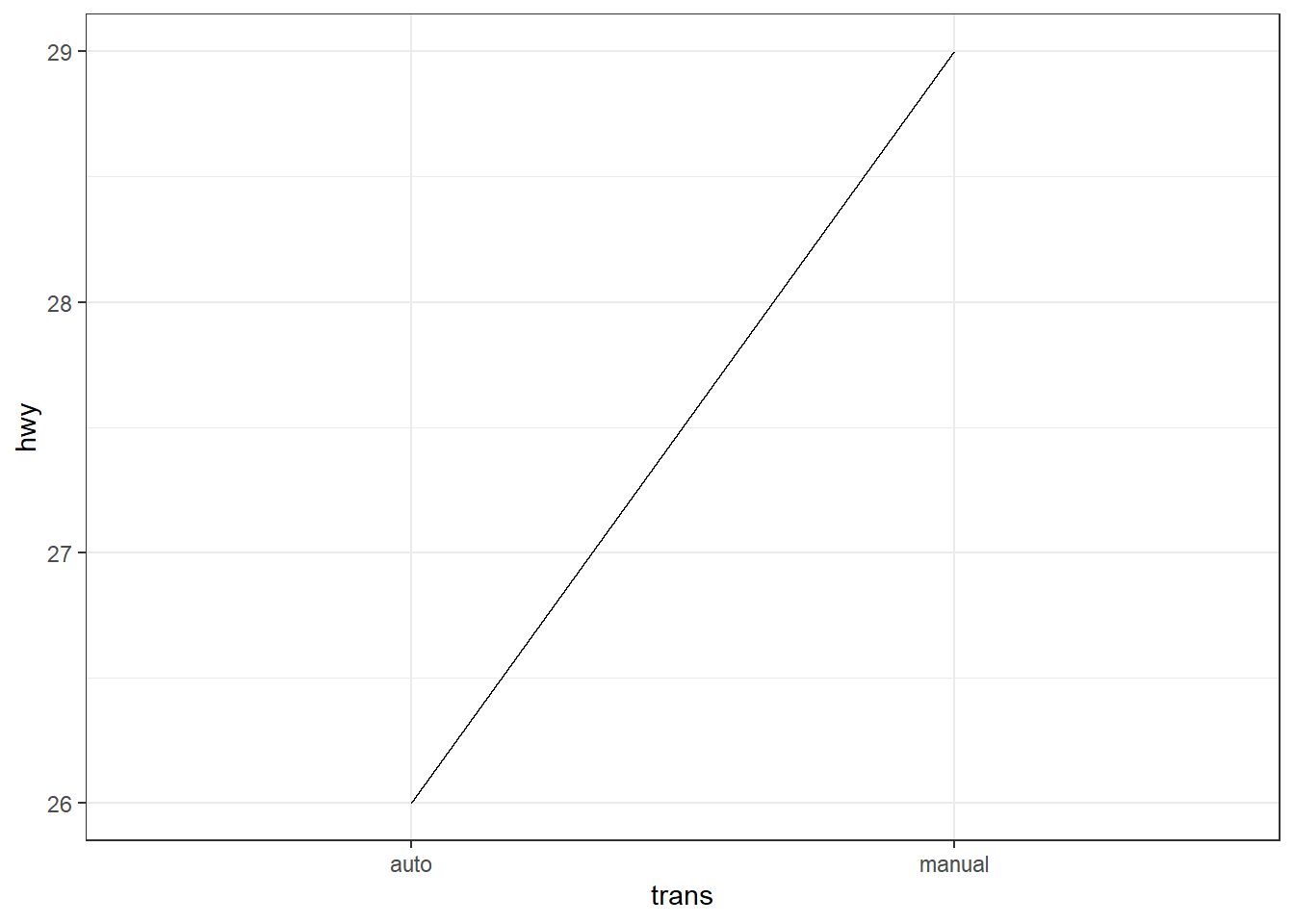
ggplot(mpg, aes(x = trans, y = hwy)) +
stat_summary(fun = quantile, fun.args = list(probs = 0.75), geom = "line", group = 1)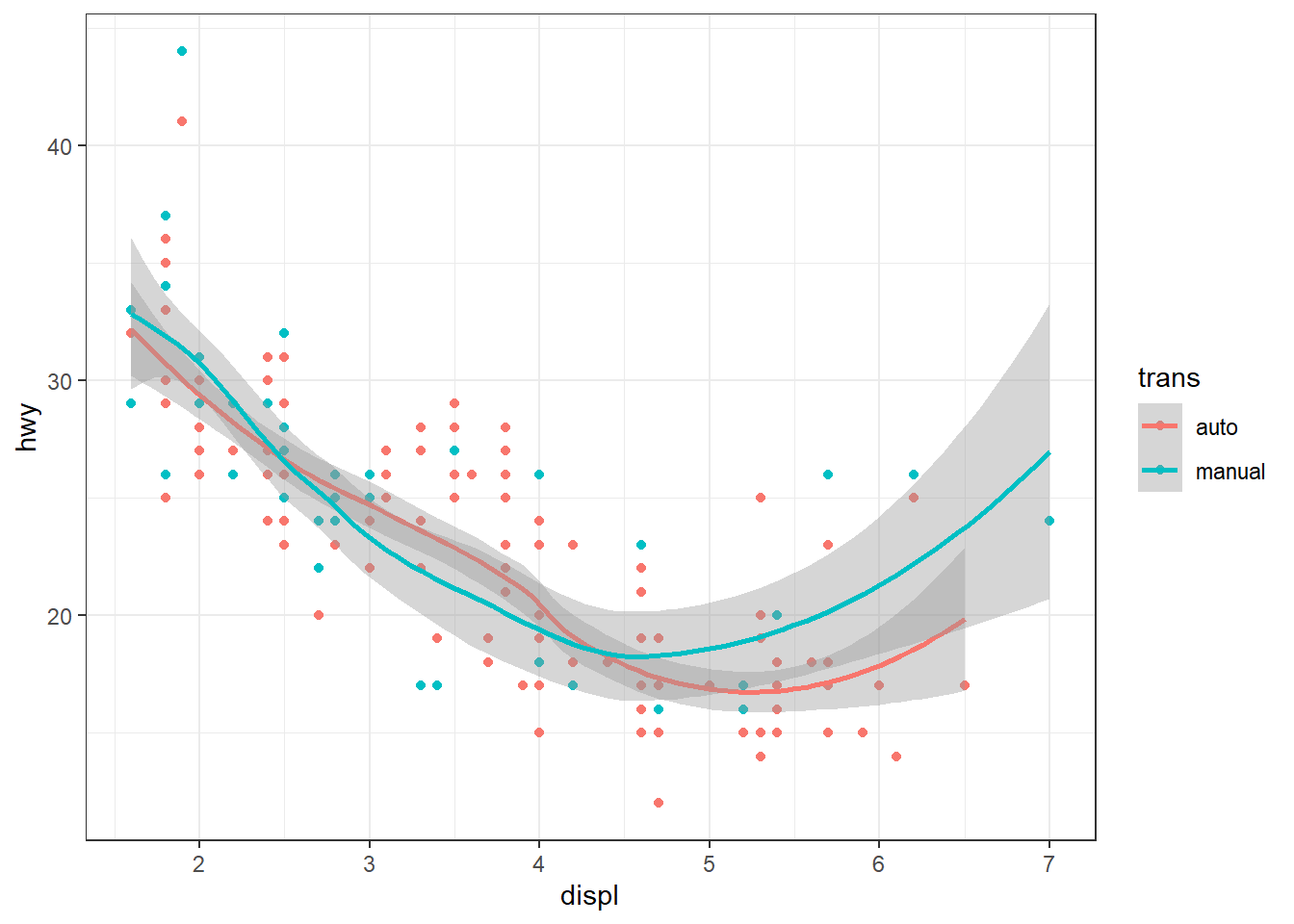
geom_smooth()
La fonction geom_smooth() permet de tracer une courbe de tendance à partir d’un nuage de points. Par défaut, cette courbe est accompagnée d’un intervalle de confiance à 95 %. Pour supprimer cet intervalle, il suffit d’ajouter l’argument se = FALSE.
L’argument method détermine la méthode de lissage ou de régression utilisée pour construire la courbe. Par défaut, method = "loess", ce qui signifie que la fonction loess() (voir ?loess) est appelée en arrière‑plan afin d’effectuer les calculs nécessaires. Il est également possible de spécifier d’autres méthodes comme par exemple lm pour ajuster une droite de régression par la méthode des moindres carrés classiques, et glm pour ajuster une courbe à l’aide d’un modèle linéaire généralisé.
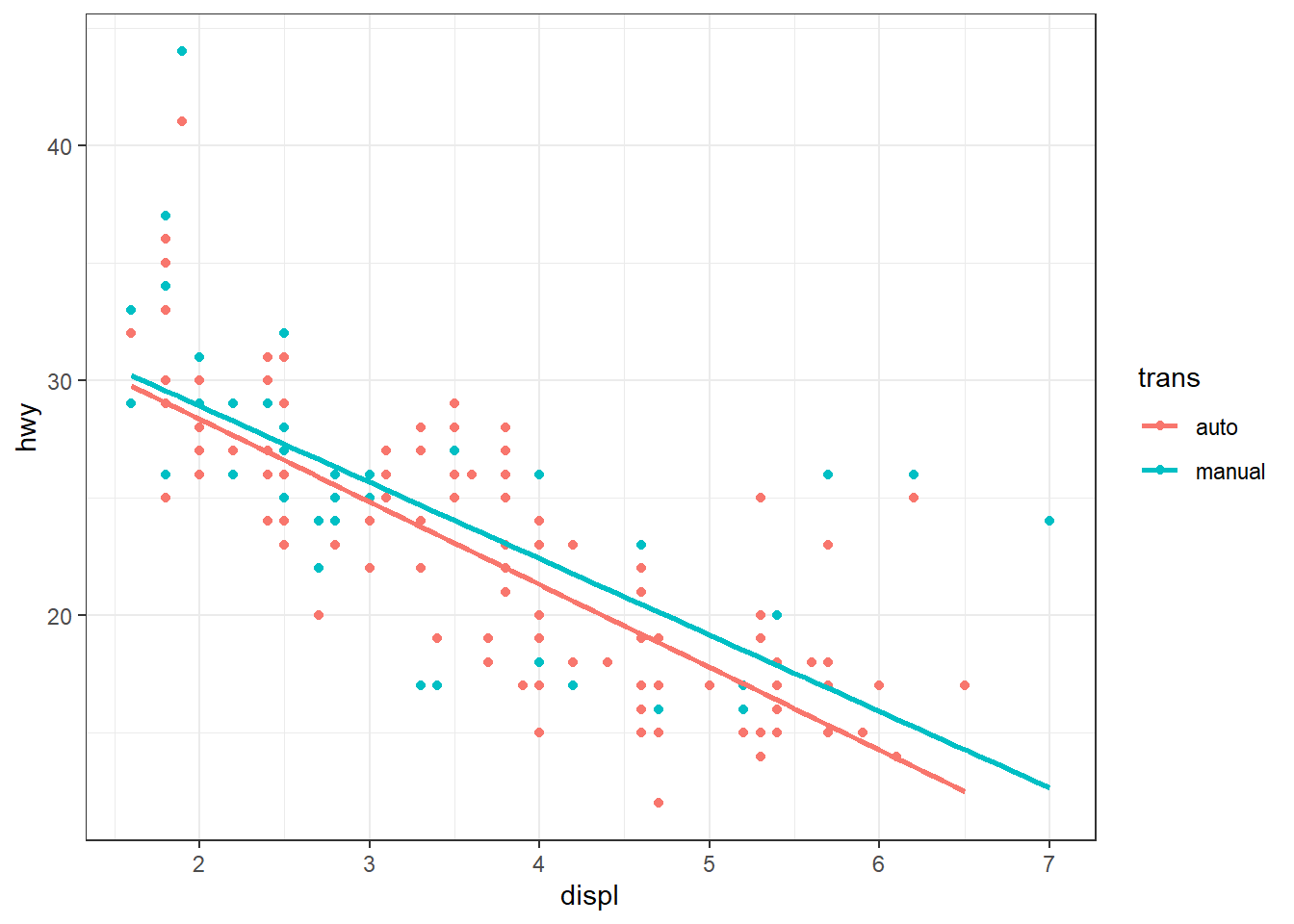
ggplot(mpg, aes(x = displ, y = hwy, color = trans)) + geom_point() + geom_smooth()
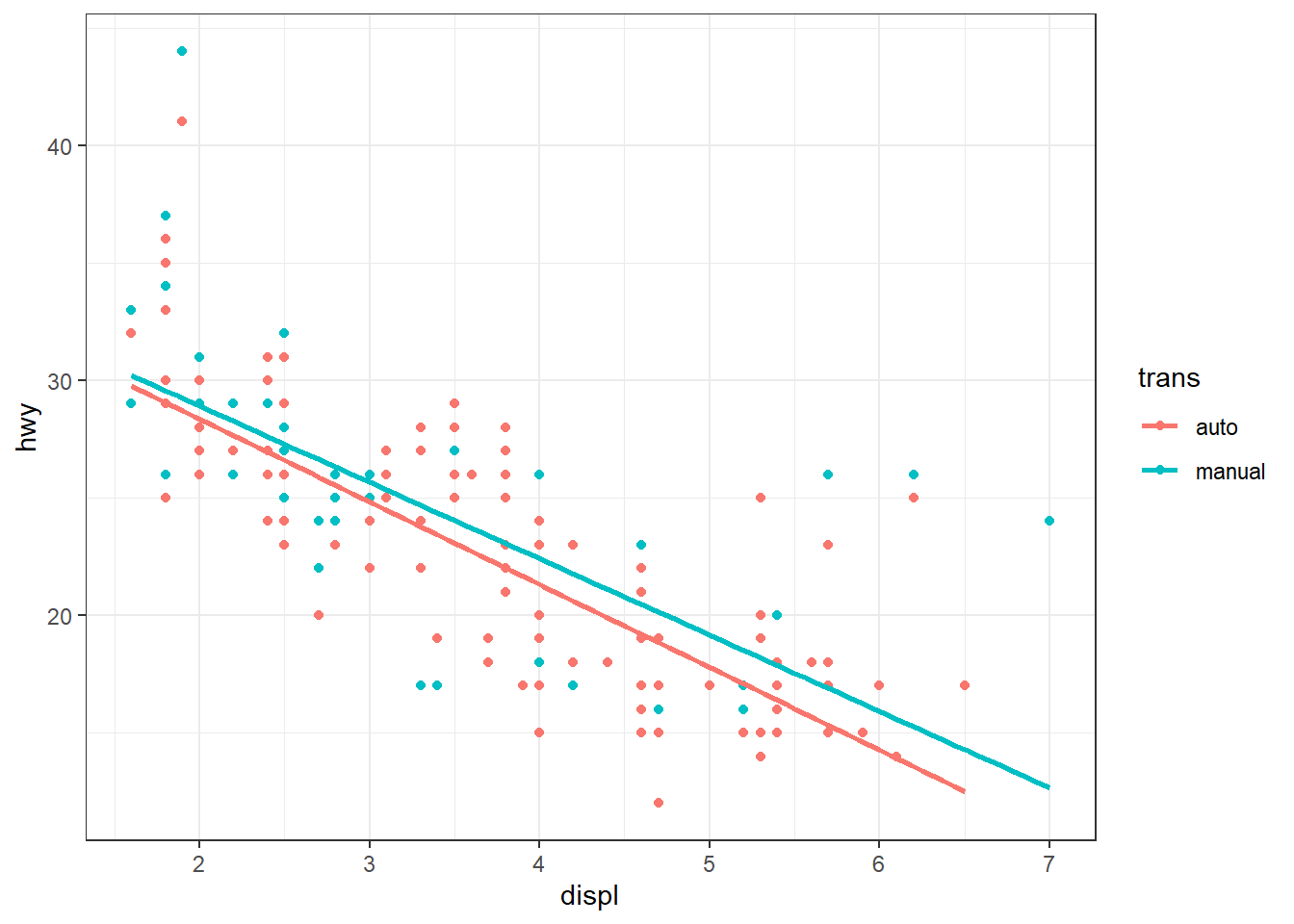
ggplot(mpg, aes(x = displ, y = hwy, color = trans)) + geom_point() + geom_smooth(method = "lm", se = FALSE)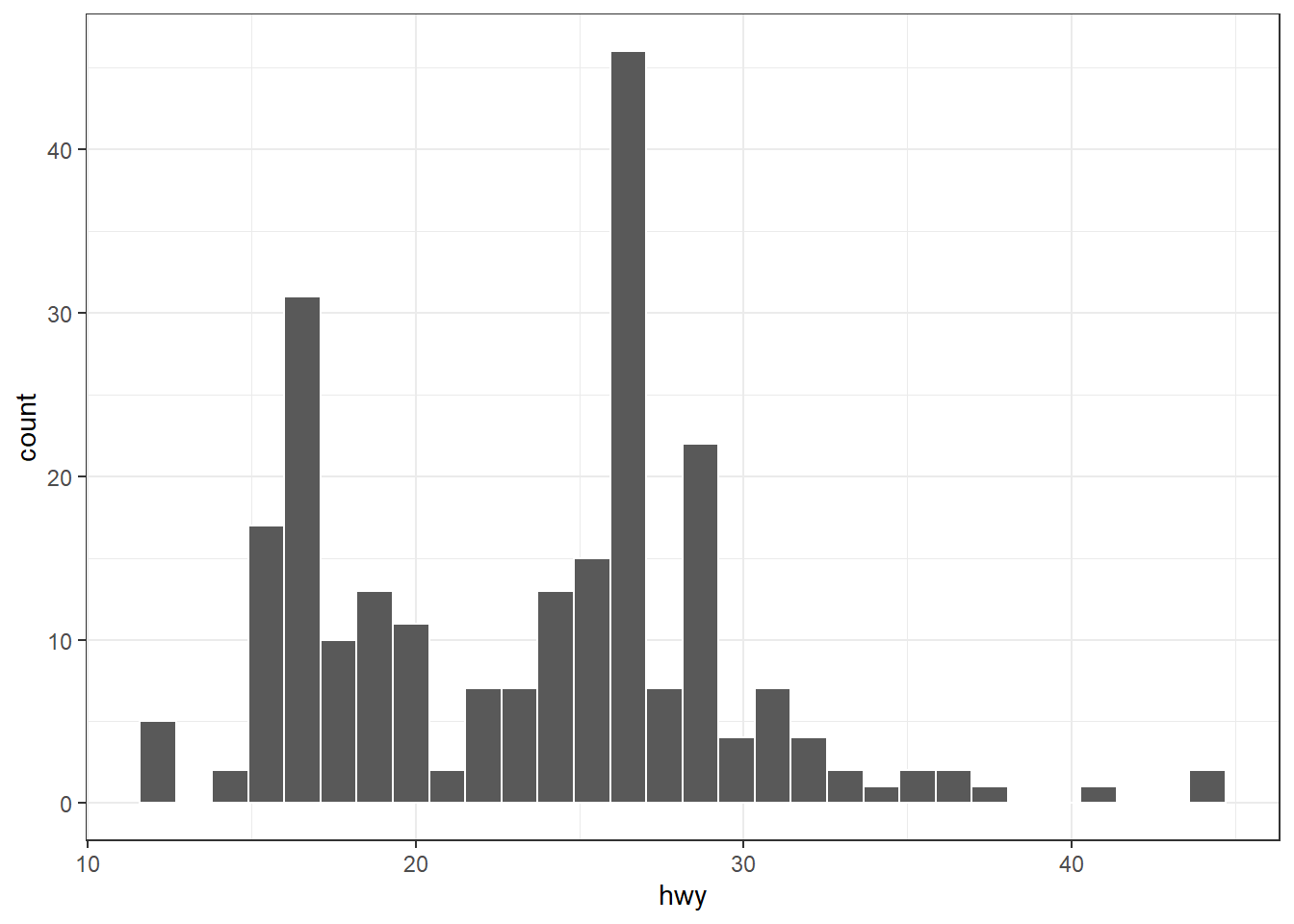
geom_histogram()
geom_histogram() est utilisée pour représenter la distribution d’une variable numérique sous forme d’histogramme. Elle découpe l’intervalle des valeurs en classes (ou bins) et compte le nombre d’observations dans chaque classe.
ggplot(mpg, aes(x = hwy)) + geom_histogram(color = "white")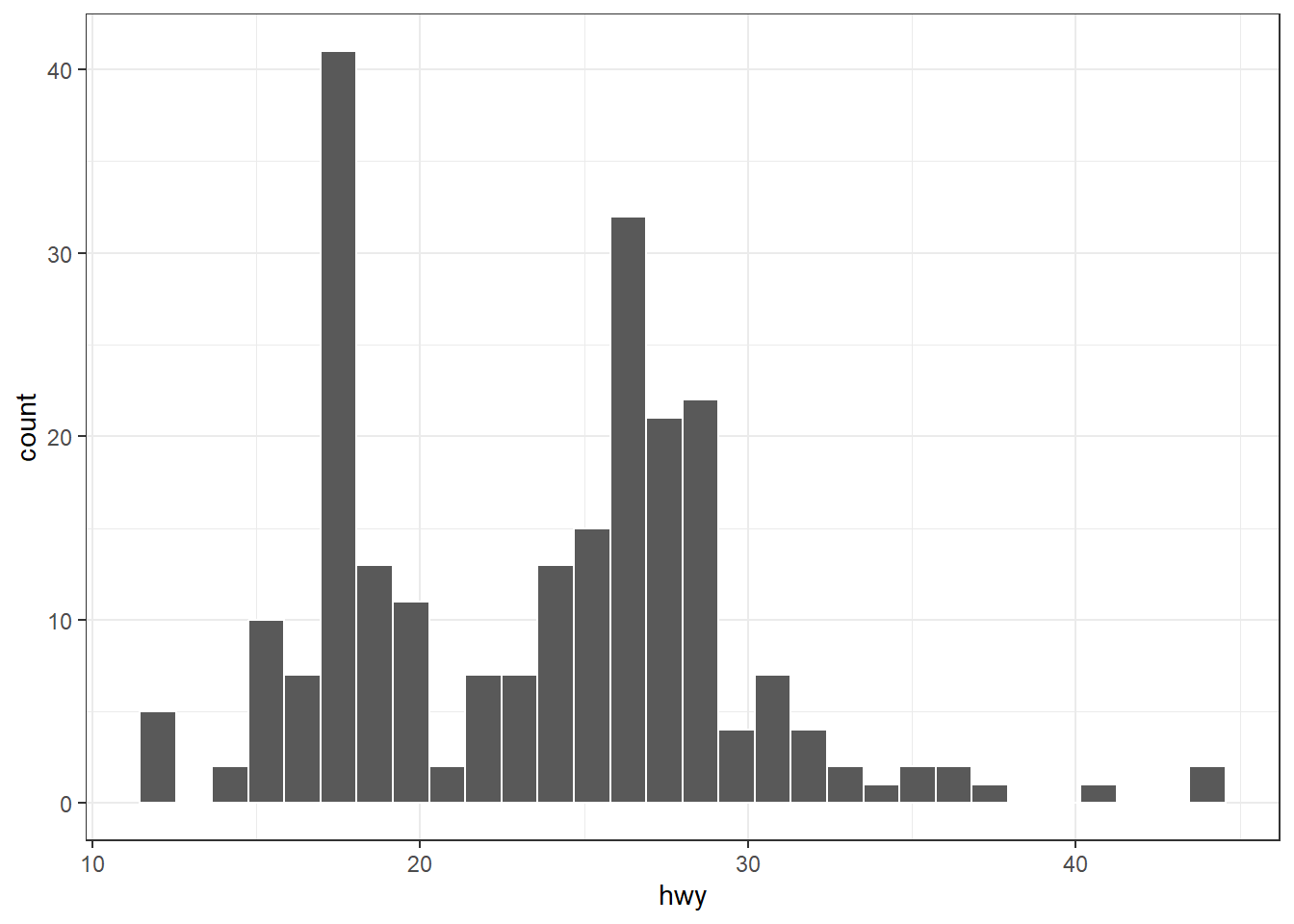
Par défaut, le nombre de classes est fixé à 30. Le découpage peut être contrôlé à l’aide des arguments bins (nombre de classes), binwidth (largeur des classes) ou breaks (bornes des classes). Plusieurs règles existent pour déterminer un découpage optimale. Parmi les plus utilisées figure la règle de Sturge, dont le calcul peut être effectué grâce à la fonction de base nclass.Sturges().
nclass.Sturges(mpg$hwy)[1] 9ggplot(mpg, aes(x = hwy)) +
geom_histogram(bins = 9, color = "black", fill = "lightgray") +
labs(title = "Histogramme des fréquences")
ggplot(mpg, aes(x = hwy, y = after_stat(density))) +
geom_histogram(bins = 9, color = "black", fill = "lightgray") +
labs(title = "Histogramme des densités")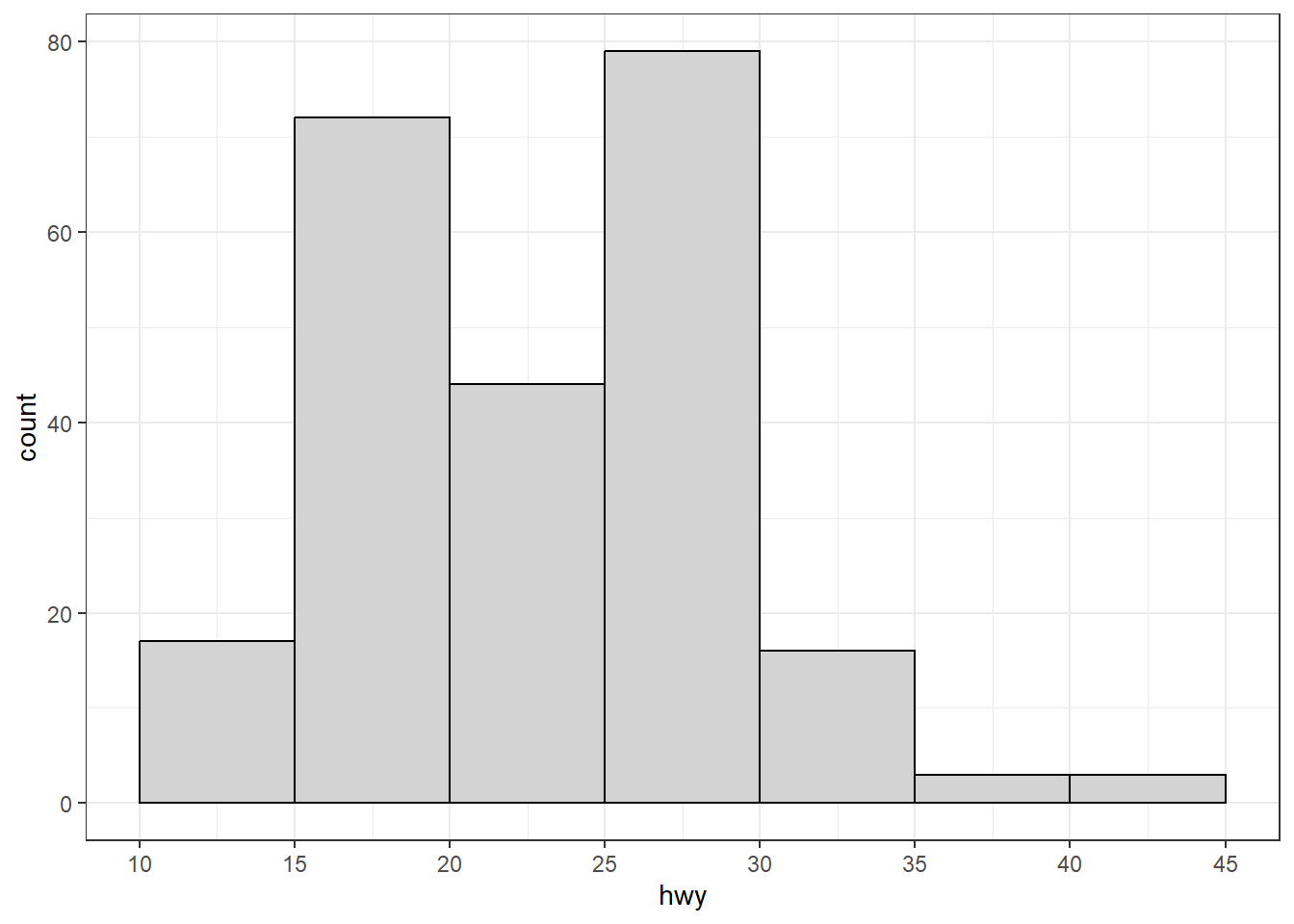
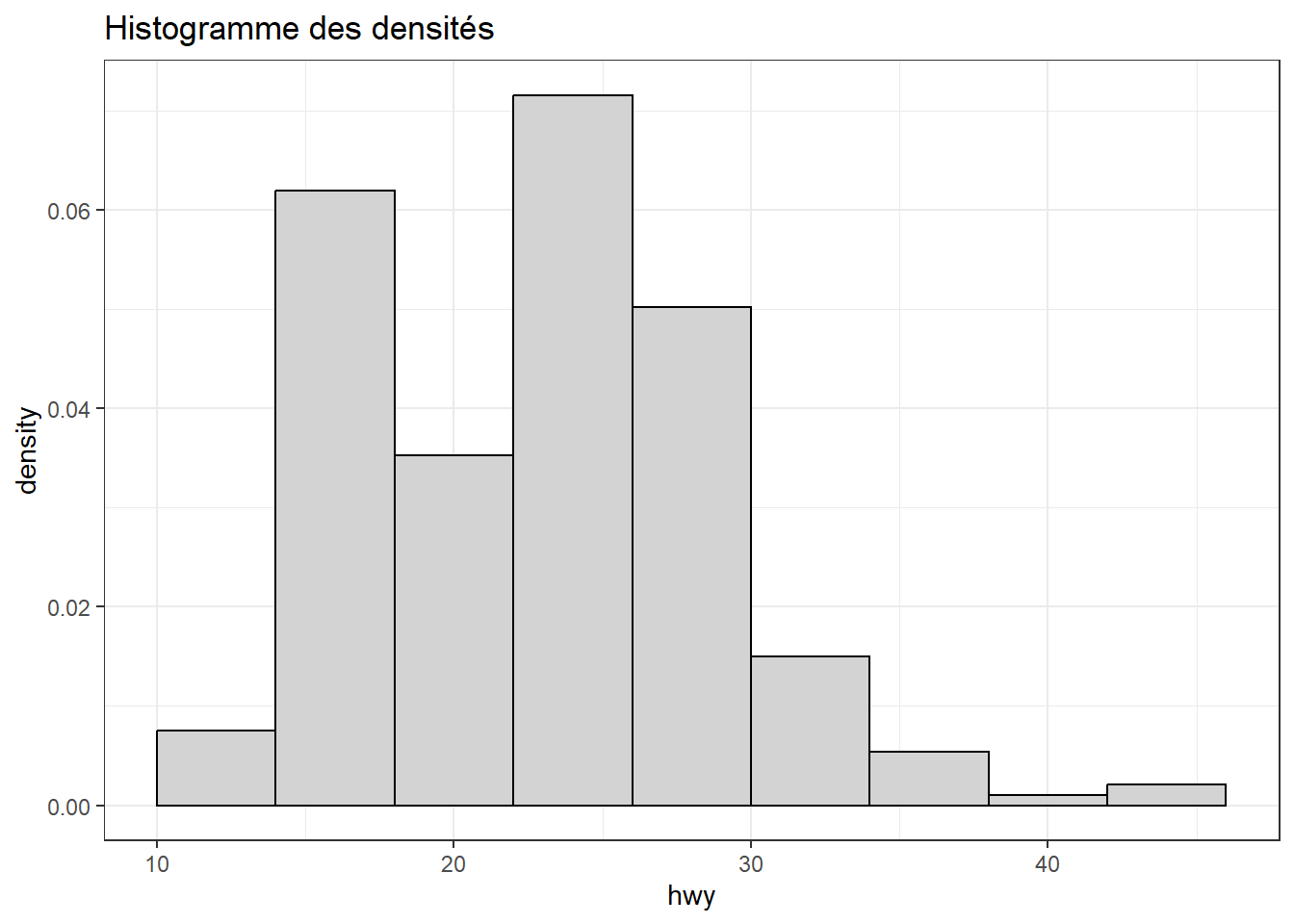
Dans l’exemple ci‑dessus, le graphique de droite montre un histogramme des densités (également appelé histogramme normalisé), où la hauteur de chaque barre correspond à la fréquence relative divisée par la largeur de la classe. Ainsi, l’aire totale de l’histogramme est égale à 1. Cette normalisation permet de l’interpréter comme une estimation empirique d’une densité de probabilité et de le comparer directement à une fonction de densité théorique, telle qu’une loi normale.
Dans le code associé, l’argument after_stat(density) permet d’accéder à la variable density calculée automatiquement par la statistique sous‑jacente stat_bin() de geom_histogram(). density n’est rien d’autre que count / (n \times binwidth), où count est le nombre d’observations dans chaque classe, n=234 est le nombre total d’observations, et binwidth = 4 est la largeur des classes utilisée ici.
De façon générale, dans ggplot, la fonction after_stat() permet d’accéder aux variables internes produites lors de la phase dite “stat”. Au cours de cette étape, les données sont transformées par la fonction statistique sous‑jacente associée à chaque fonction geom, afin de générer des valeurs intermédiaires (par exemple count, density, ncount, etc) directement exploitables pour la visualisation.
Pour affiner le découpage en classes d’un histogramme, on peut utiliser l’argument breaks, qui permet de définir explicitement les bornes des intervalles. Dans l’exemple ci‑dessous, on utilise aussi la fonction pretty() (issue de R de base), qui génère une suite de valeurs arrondies et régulièrement espacées qui couvrent l’étendue de hwy (range(mpg$hwy) = 12, 44), ce qui rend le graphique plus facile à lire. Exemple :
breaks <- pretty(range(mpg$hwy), n = 9)
ggplot(mpg, aes(x = hwy)) + geom_histogram(breaks = breaks, color = "black", fill = "lightgray") +
scale_x_continuous(breaks = breaks)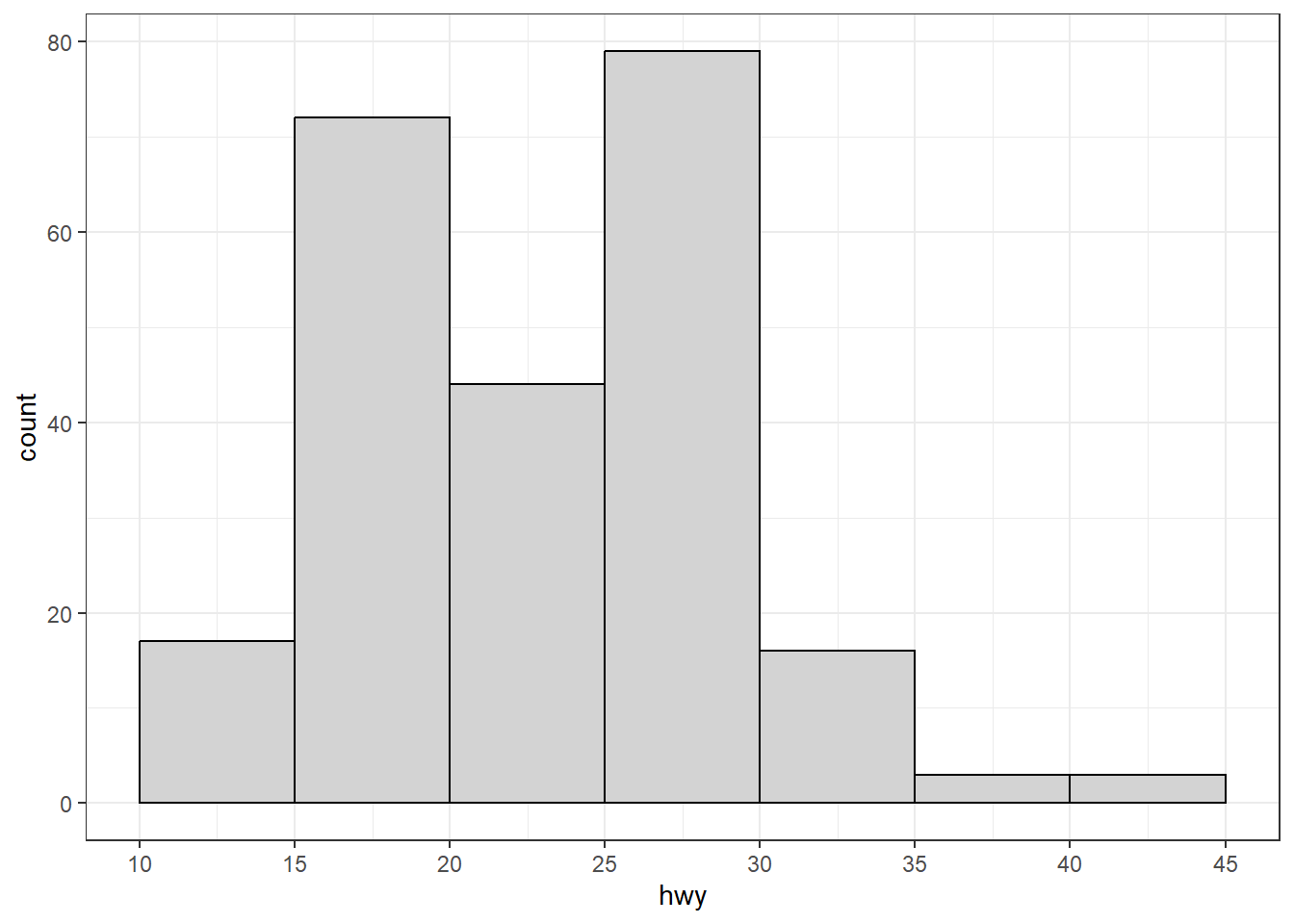
geom_density()
geom_density() permet de tracer une courbe de densité estimée par noyau (kernel density estimation). Elle fournit une représentation lissée de la distribution, complémentaire à l’histogramme, et facilite la comparaison entre groupes.
Dans geom_density(), l’argument bw (bandwidth) contrôle le degré de lissage de la courbe de densité en fixant l’amplitude de la fenêtre de calcul utilisée pour l’estimation. Par défaut, bw = "nrd0", ce qui signifie que le bandwidth est calculé via la fonction de base bw.nrd0().
bw.nrd0(mpg$displ)[1] 0.3905243Les autres méthodes disponibles incluent “nrd”, “ucv”, “bcv” , et “sj”; voir ?bw.nrd0. On peut aussi fixer manuellement le bandwidth, exemple : geom_density(bw = 0.4), ou l’ajuster de manière relative à l’aide de l’argument adjust : adjust = 1 correspond à la valeur standard, adjust = 0.5 la réduit de la moitié (courbe plus détaillée), tandis que adjust = 2 la double (courbe plus lissée).
# Graphe de base : une simple courbe de densité de la variable hwy
ggplot(mpg, aes(x = hwy)) + geom_density()
# Superposer un histogramme "normalisé" et une densité :
ggplot(mpg, aes(x = hwy)) +
geom_histogram(aes(y = after_stat(density)), bins = 9, alpha = 0.5, color = "white") +
geom_density(linewidth = 1)
# Plusieurs densités dans un même graphe
ggplot(mpg, aes(x = hwy, color = trans, fill = trans)) +
geom_density(linewidth = 1, alpha = 0.05) +
labs(color = "Transmission", fill = "Transmission")
# Effet du bandwidth (paramètre adjust)
ggplot(mpg, aes(x = hwy)) +
geom_density(aes(color = "nrd0", linetype = "nrd0")) +
geom_density(aes(color = "nrd", linetype = "nrd"), bw = "nrd") +
geom_density(aes(color = "sj", linetype = "sj"), bw = "sj") +
labs(color = "Bandwidth", linetype = "Bandwidth")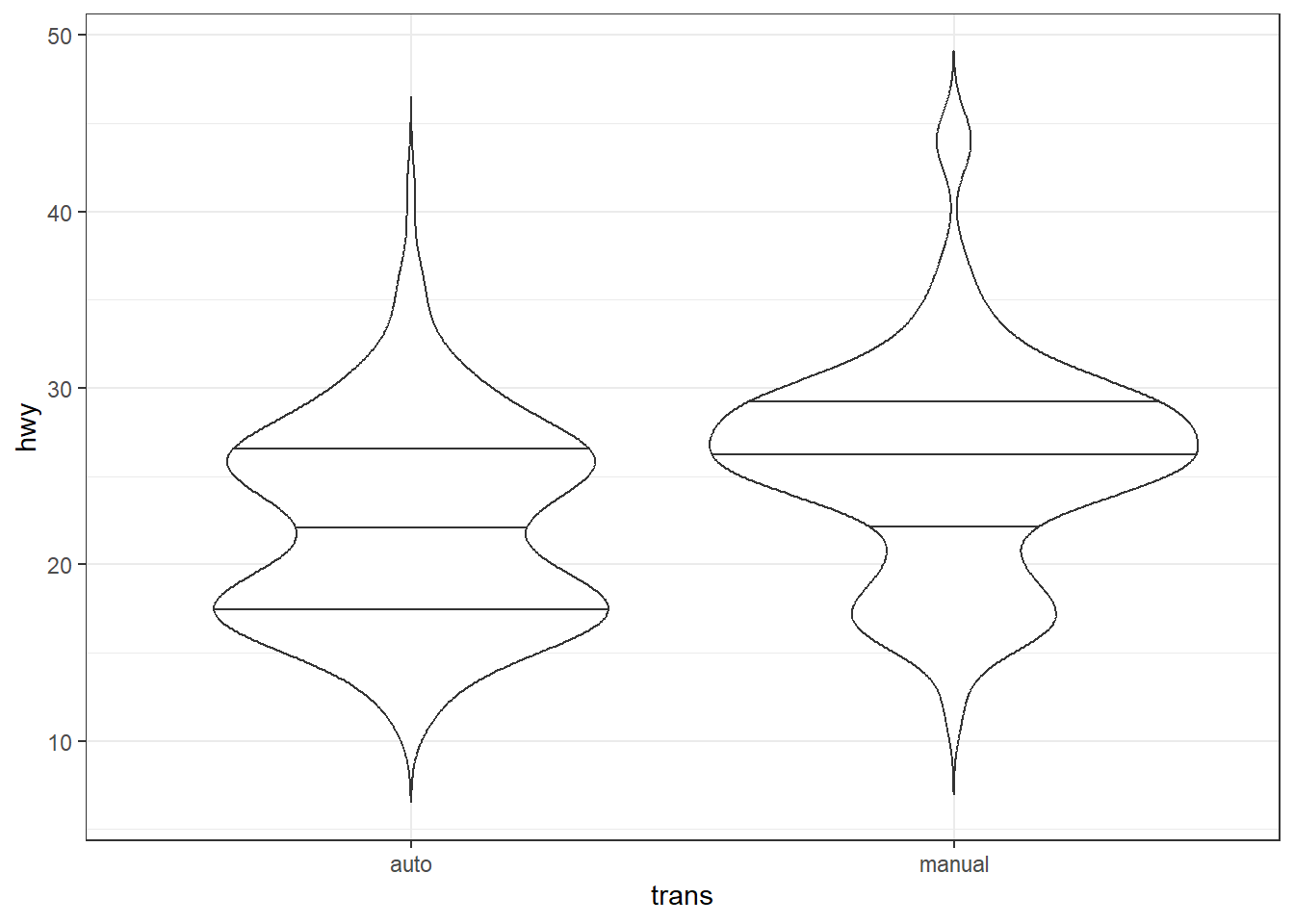
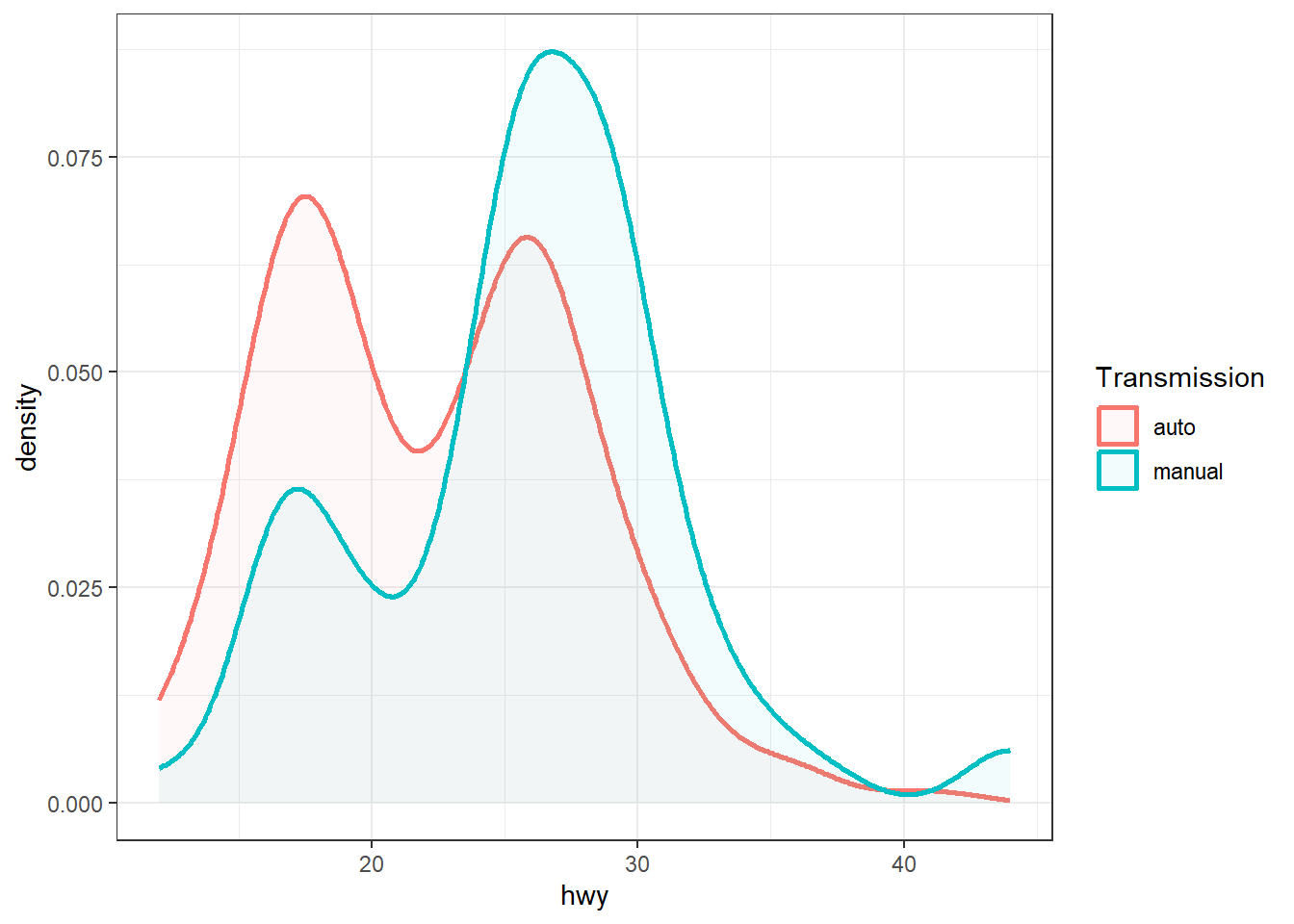
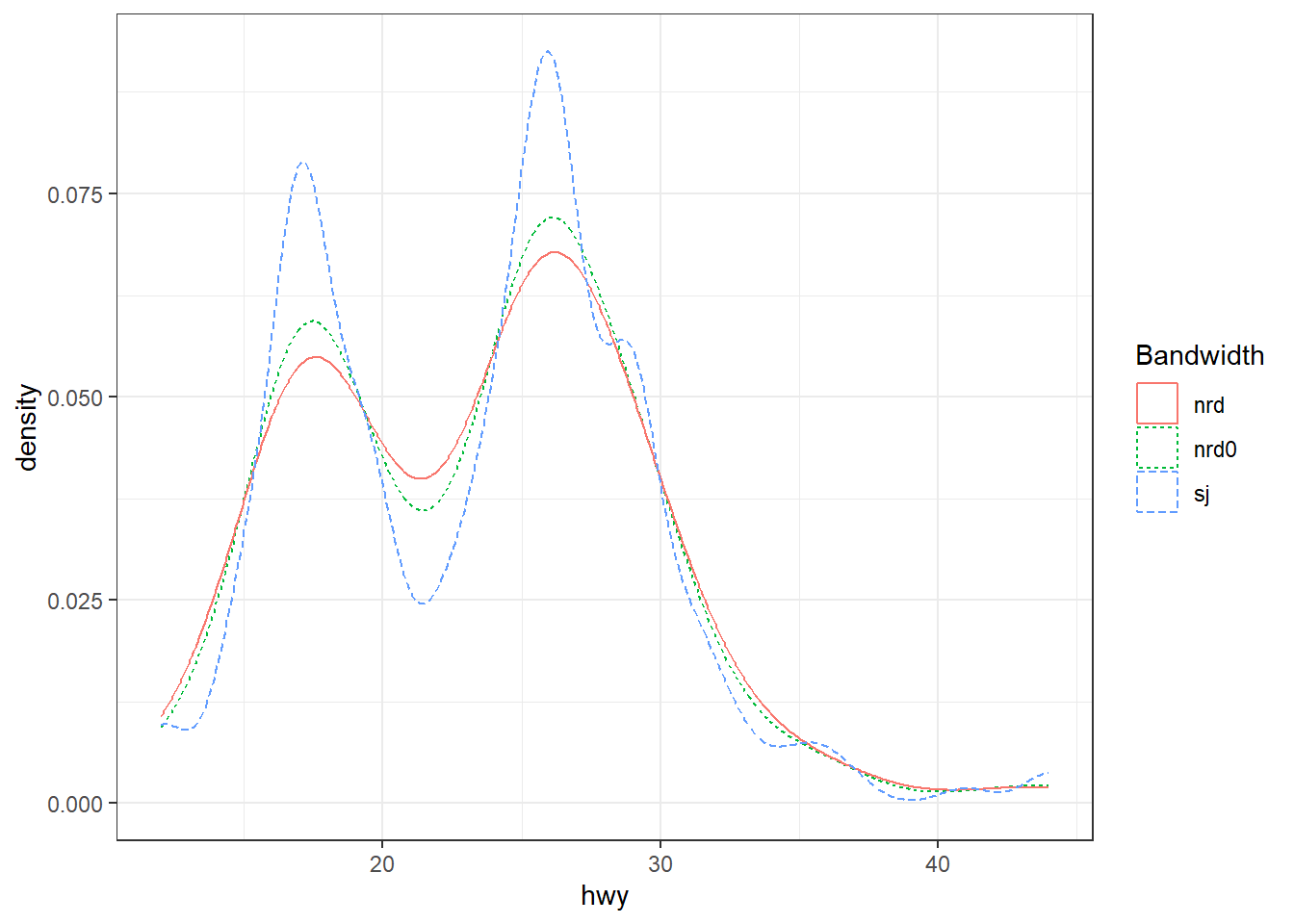
Le dernier graphique met en évidence l’effet du bandwidth sur la courbe de densité estimée. Dans ce code, le fait de mapper une constante dans aes() (voir la Section 12.2.1) conduit ggplot à considérer cette valeur comme une catégorie et à l’afficher dans la légende. Ainsi, même si la valeur ne provient pas d’une variable du jeu de données, elle est interprétée comme un niveau distinct et reçoit une couleur ou un type de trait spécifique. Ce procédé permet d’annoter facilement les courbes avec les paramètres utilisés (ici les différentes valeurs de bw).
geom_violin()
geom_violin() trace un violon plot (graphique en violon), formé de deux courbes de densité identiques affichées en miroir l’une en face de l’autre. En plus des arguments bw et adjust, geom_violin() accepte les arguments quantile.linetype et trim. Le premier permet d’ajouter des lignes horizontales indiquant les quantiles. Le second contrôle si les violons sont tronqués aux valeurs extrêmes observées (trim = TRUE, par défaut) ou prolongés (trim = FALSE).
ggplot(mpg, aes(x = trans, y = hwy)) + geom_violin(trim = FALSE, quantile.linetype = 1)
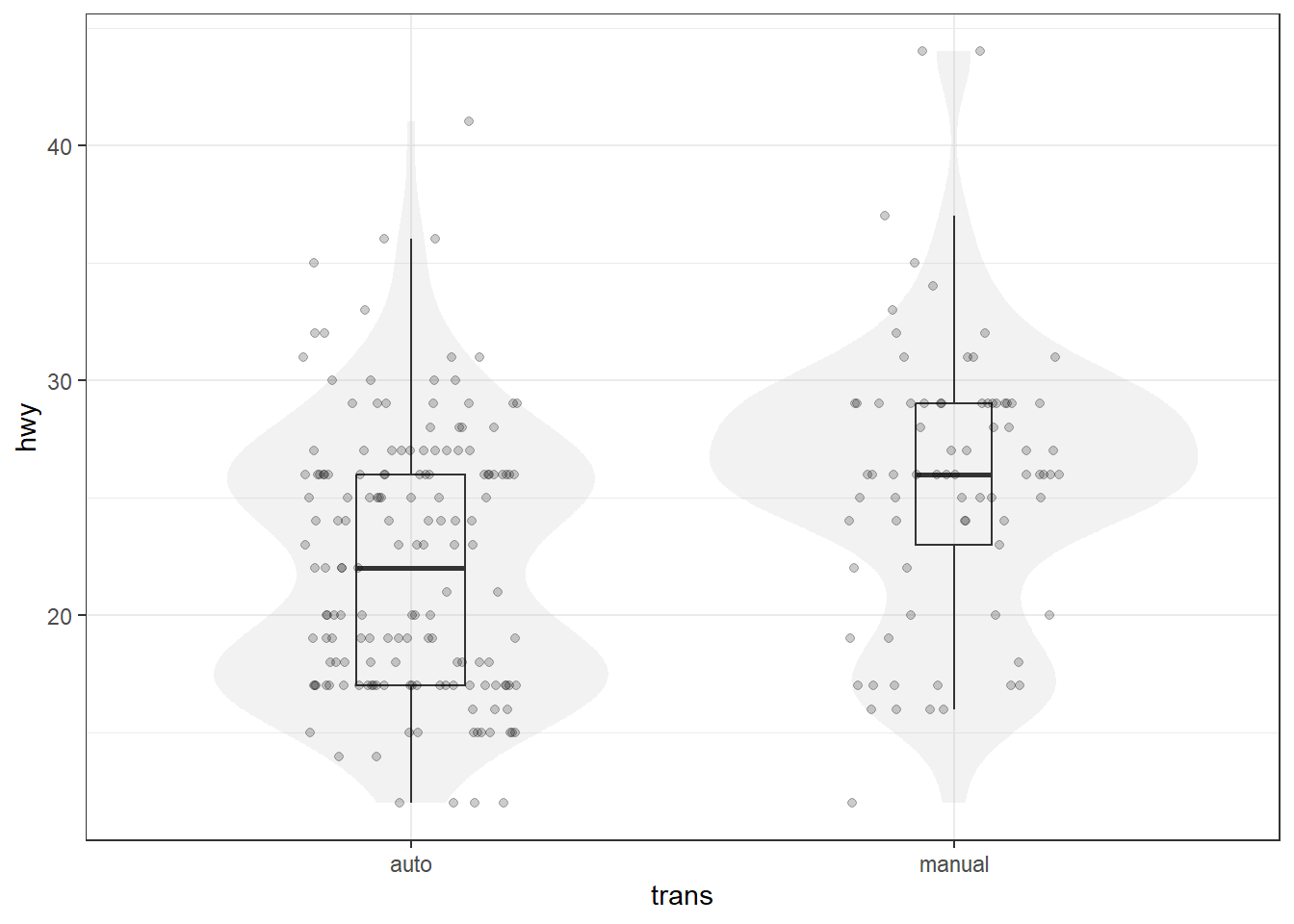
ggplot(mpg, aes(x = trans, y = hwy)) +
geom_violin(color = NA, fill = "gray", alpha = 0.2) +
geom_boxplot(width = 0.2, varwidth = TRUE, outliers = FALSE, fill = NA) +
geom_jitter(width = 0.2, height = 0, alpha = 0.2)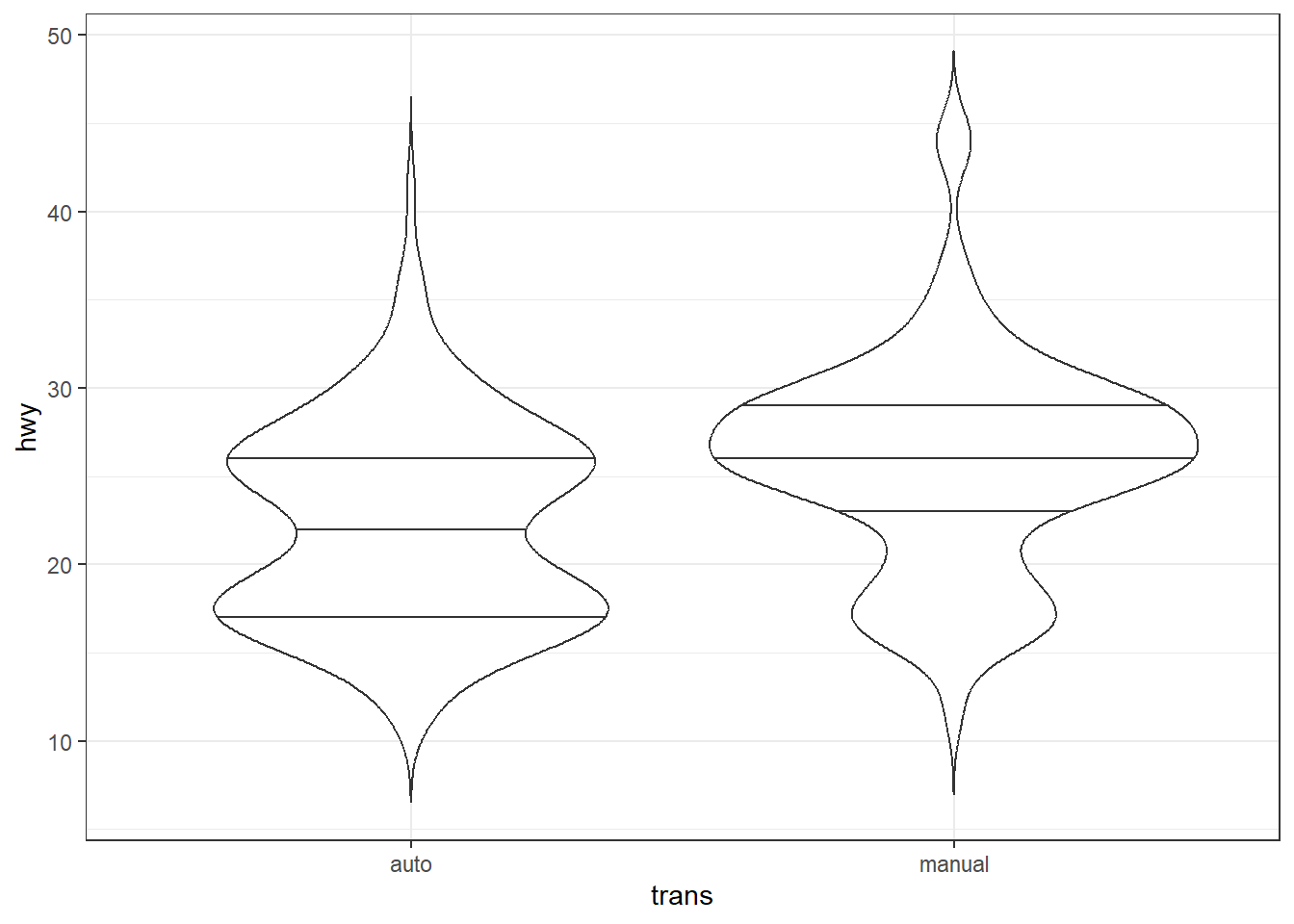
geom_bar() et geom_col()
Lorsqu’on souhaite représenter des données sous forme de barres avec ggplot, deux fonctions sont disponibles : geom_bar() et geom_col(). Le choix entre les deux repose sur une convention pratique :
-
geom_bar()est pensé pour les données brutes : par défaut, elle utilisestat = "count"pour compter le nombre d’observations dans chaque catégorie et construit les barres à partir de ces effectifs. -
geom_col()est destiné aux données déjà résumées ou agrégées : elle ne fait aucun calcul et trace directement les valeurs fournies.geom_col(...)est équivalente àgeom_bar(..., stat = "identity").
Prenons comme point de départ le code suivant :
trans n p.trans
1 auto 157 0.6709402
2 manual 77 0.3290598Réalisons à présent deux barplots : le premier à partir des données brutes mpg, et le second à partir du tableau résumé tb :
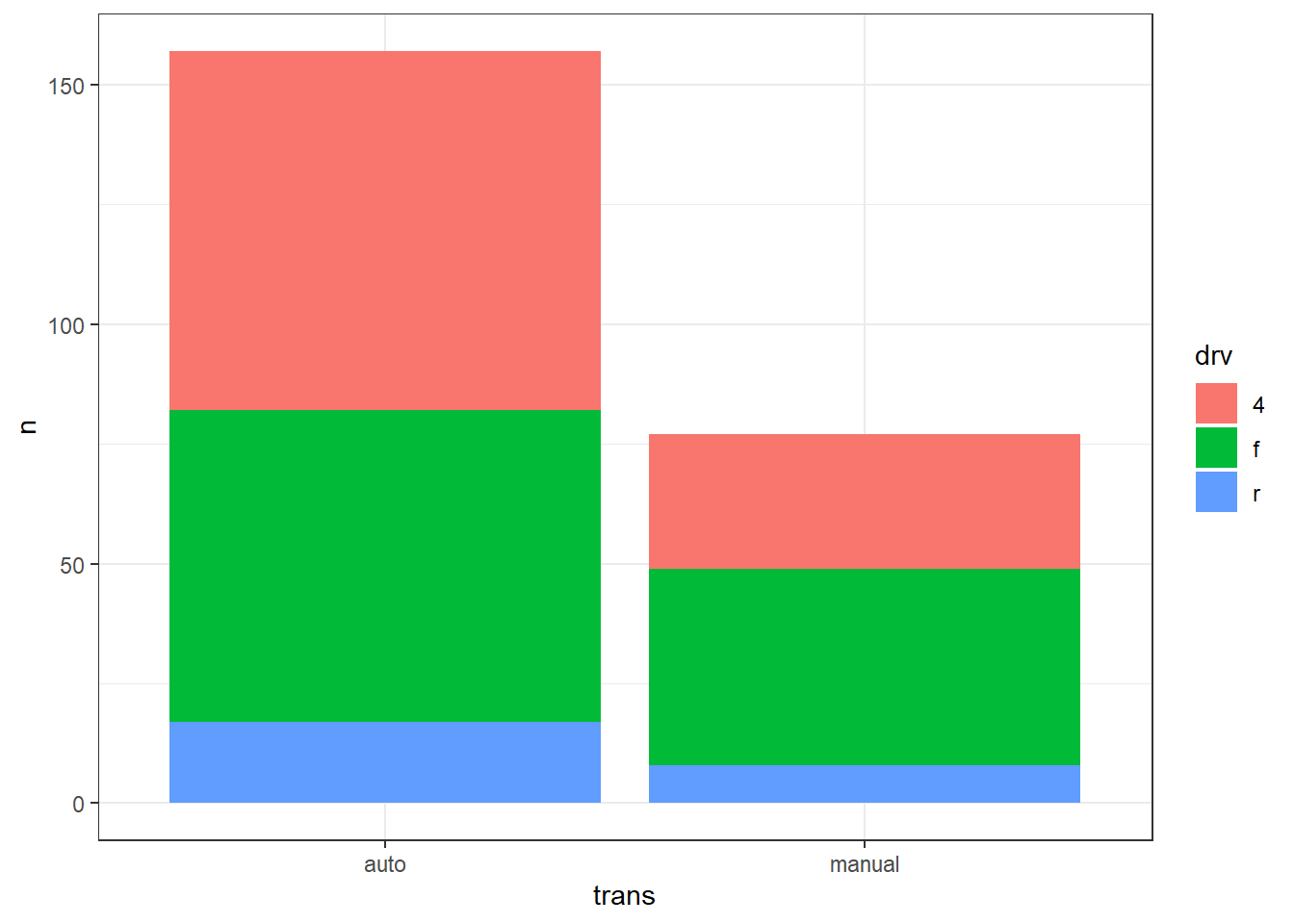
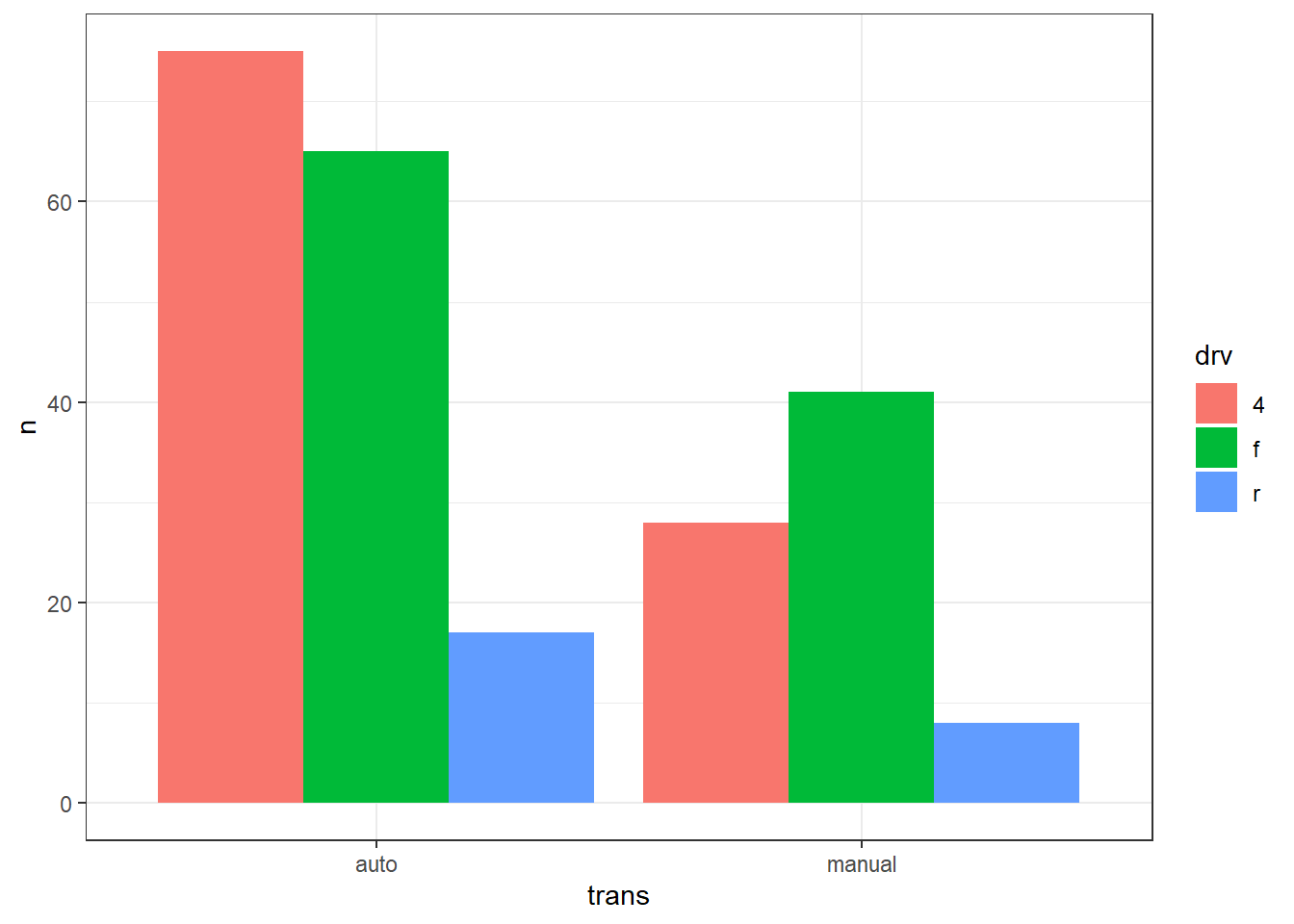
Dans un barplot, l’argument fill peut être utiliser pour ajouter une deuxième variable catégorielle. Chaque modalité (càd chaque valeur possible de cette variable) reçoit une couleur distincte. Par exemple, si l’on utilise fill = drv, alors les barres seront segmentées et colorées selon le type de traction (“f” = avant, “r” = arrière, et 4 = intégrale). Le paramètre position permet ensuite de choisir la disposition des bars. Il y a trois possibilités :
-
position = "stack"(par défaut) → barres empilées en effectifs; -
position = "dodge"→ barres côte à côte en effectifs; et -
position = "fill"→ barres empilées des proportions conditionnelles (chaque barre = 100 %). Exemple :
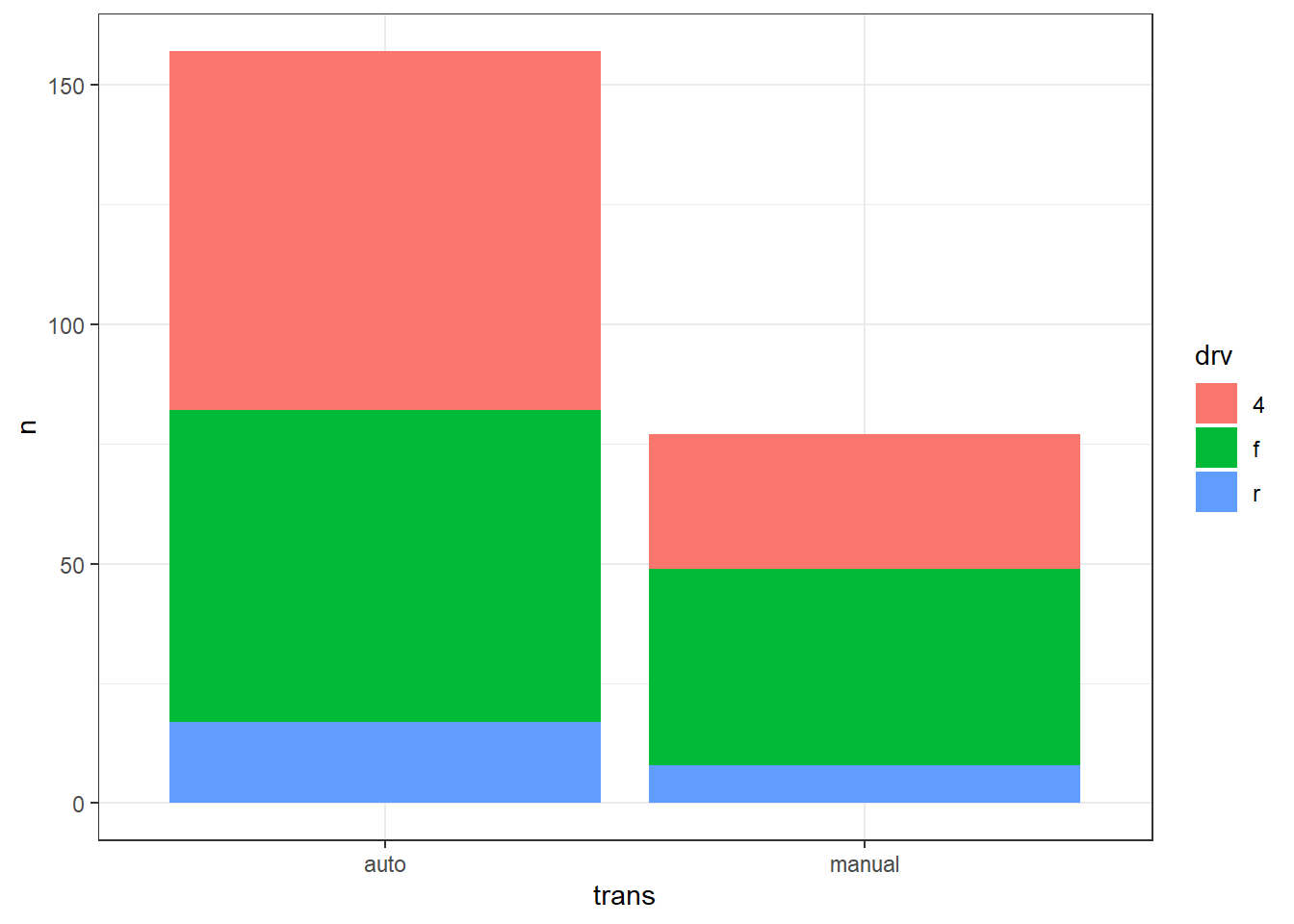
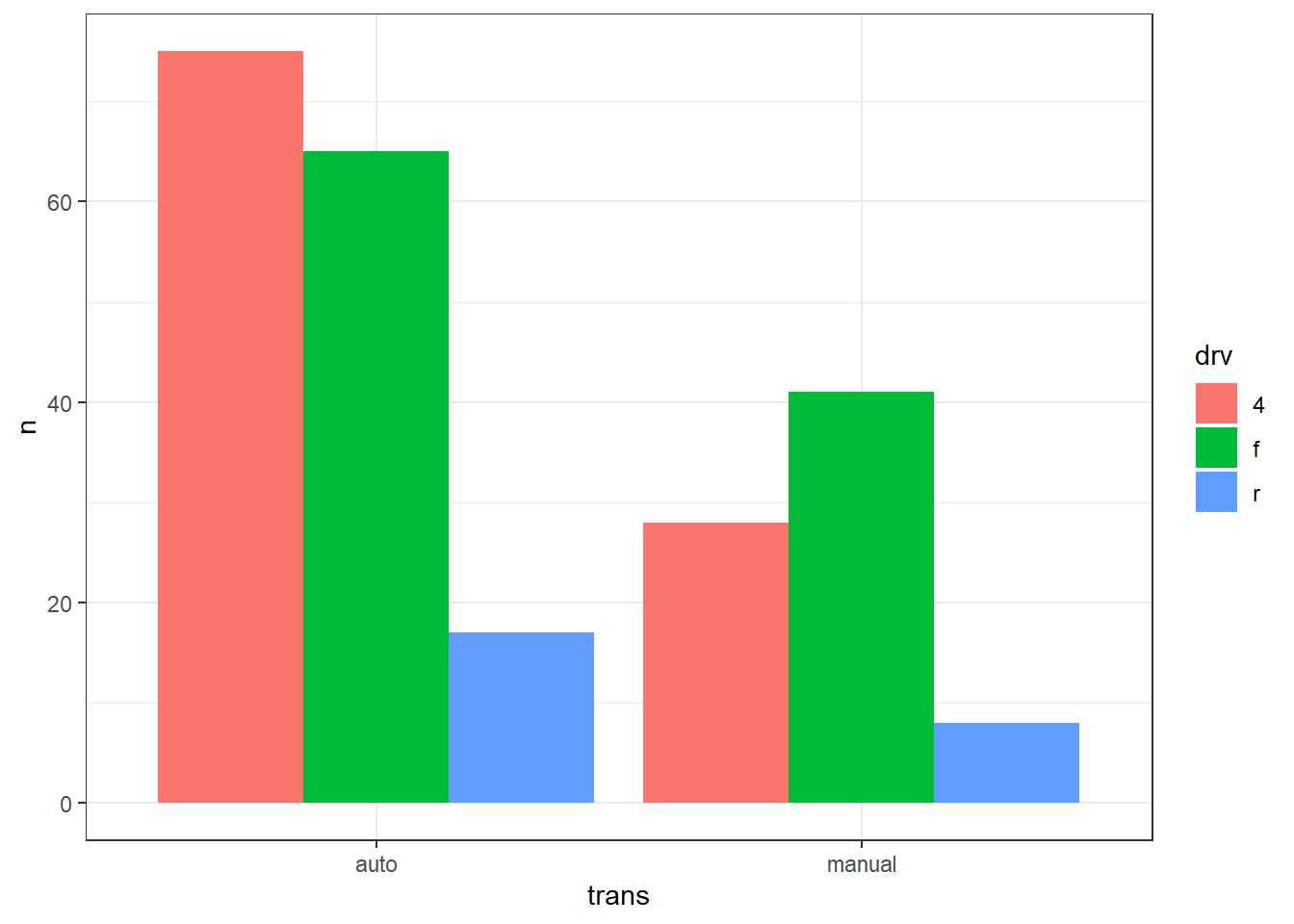
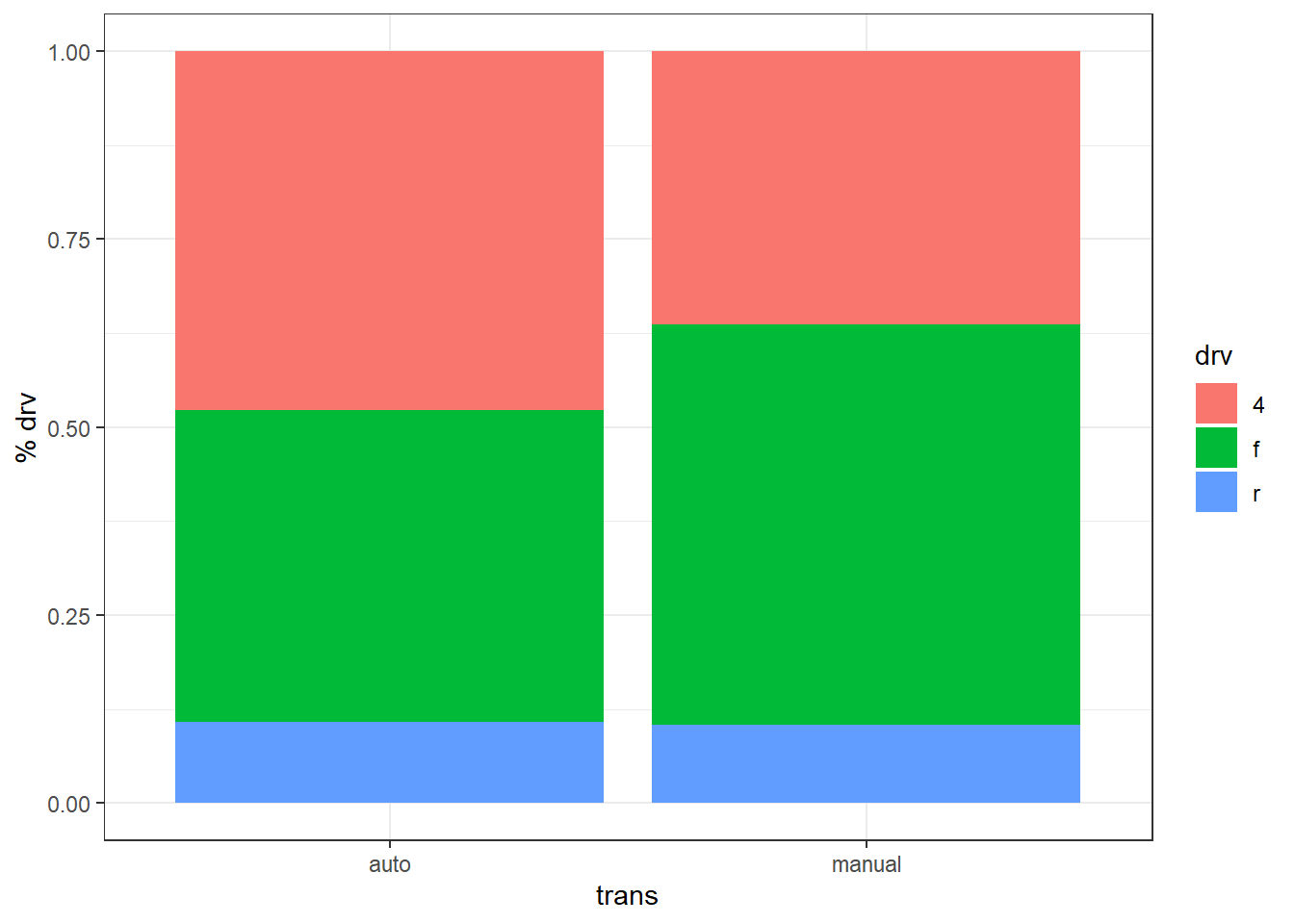
Ces trois graphiques sont simplement des représentations visuelles des chiffres calculés dans le tableau suivant
tb.trans.drv <- mpg |>
dplyr::count(trans, drv) |> # Compter les observations pour chaque (trans, drv)
dplyr::mutate(
.by = trans, # calcul fait séparément pour chaque trans
n.trans = sum(n), # total des observations (par trans)
p.drv.by.trans = n / n.trans) |> # proportion de drv (conditionnelle à trans)
print() trans drv n n.trans p.drv.by.trans
1 auto 4 75 157 0.4777070
2 auto f 65 157 0.4140127
3 auto r 17 157 0.1082803
4 manual 4 28 77 0.3636364
5 manual f 41 77 0.5324675
6 manual r 8 77 0.1038961Et voici un code alternatif pour réaliser ce type de graphiques :
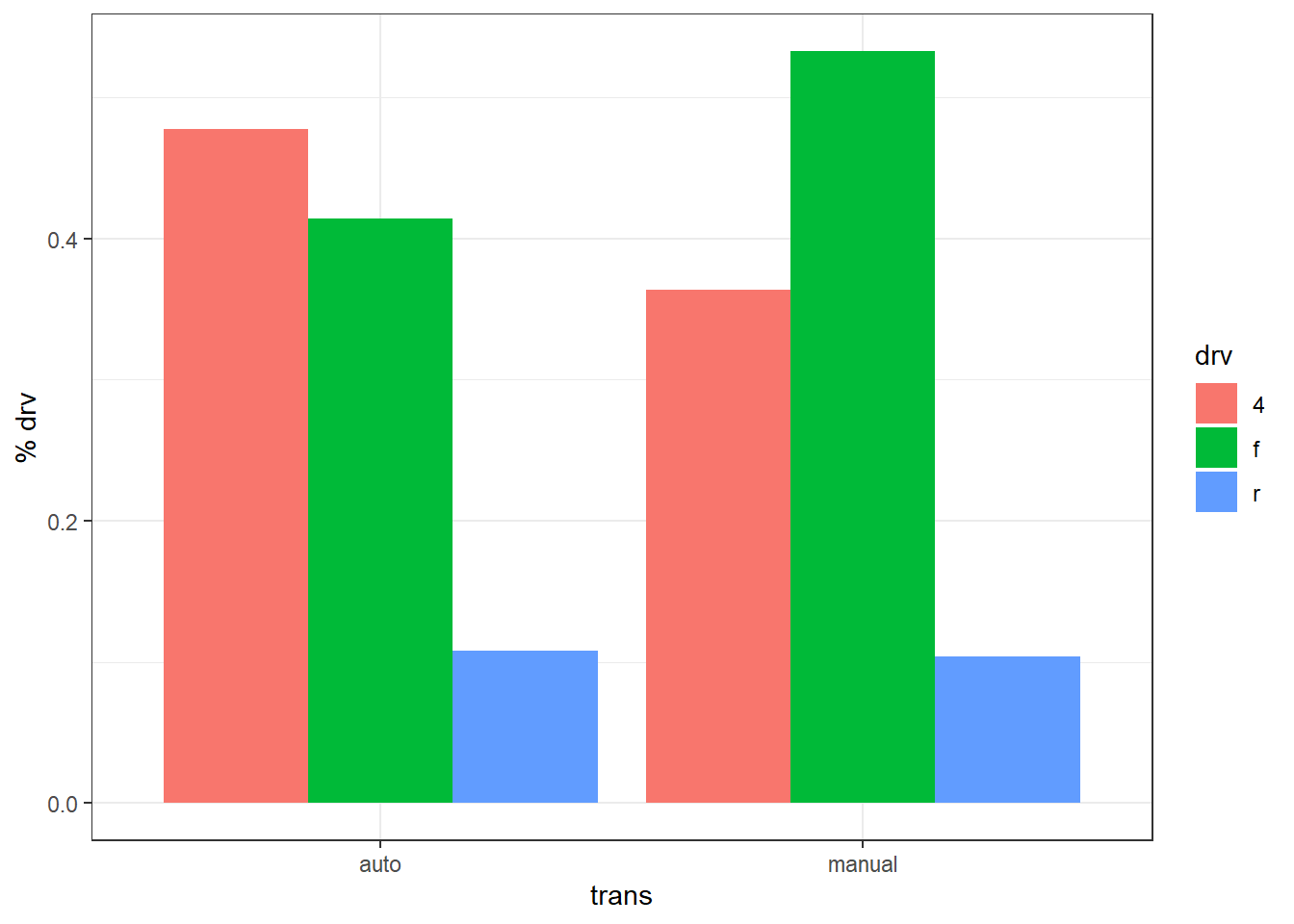
geom_text()
La fonction geom_text() permet d’ajouter des annotations textuelles directement sur un graphique. Elle est particulièrement utile pour rendre les visualisations plus lisibles en affichant des valeurs numériques, des étiquettes ou des commentaires.
En plus de x et y, qui contrôlent la position du texte, l’argument principal et obligatoire de la fonction geom_text() est label, qui précise le contenu à afficher. Autres arguments utiles incluent vjust et hjust, qui permettent d’ajuster la position verticale et horizontale du texte, lequel est par défaut centré sur la position définie par (x, y). vjust et hjust peuvent être soit un nombre, typiquement compris entre 0 (droite/bas) et 1 (haut/gauche), soit une chaîne de caractères (“left”, “middle”, “right”, “bottom”, “center”, “top”).
L’option check_overlap = TRUE permet quant à elle de supprimer automatiquement les textes qui se chevauchent, ce qui rend le graphique plus lisible.
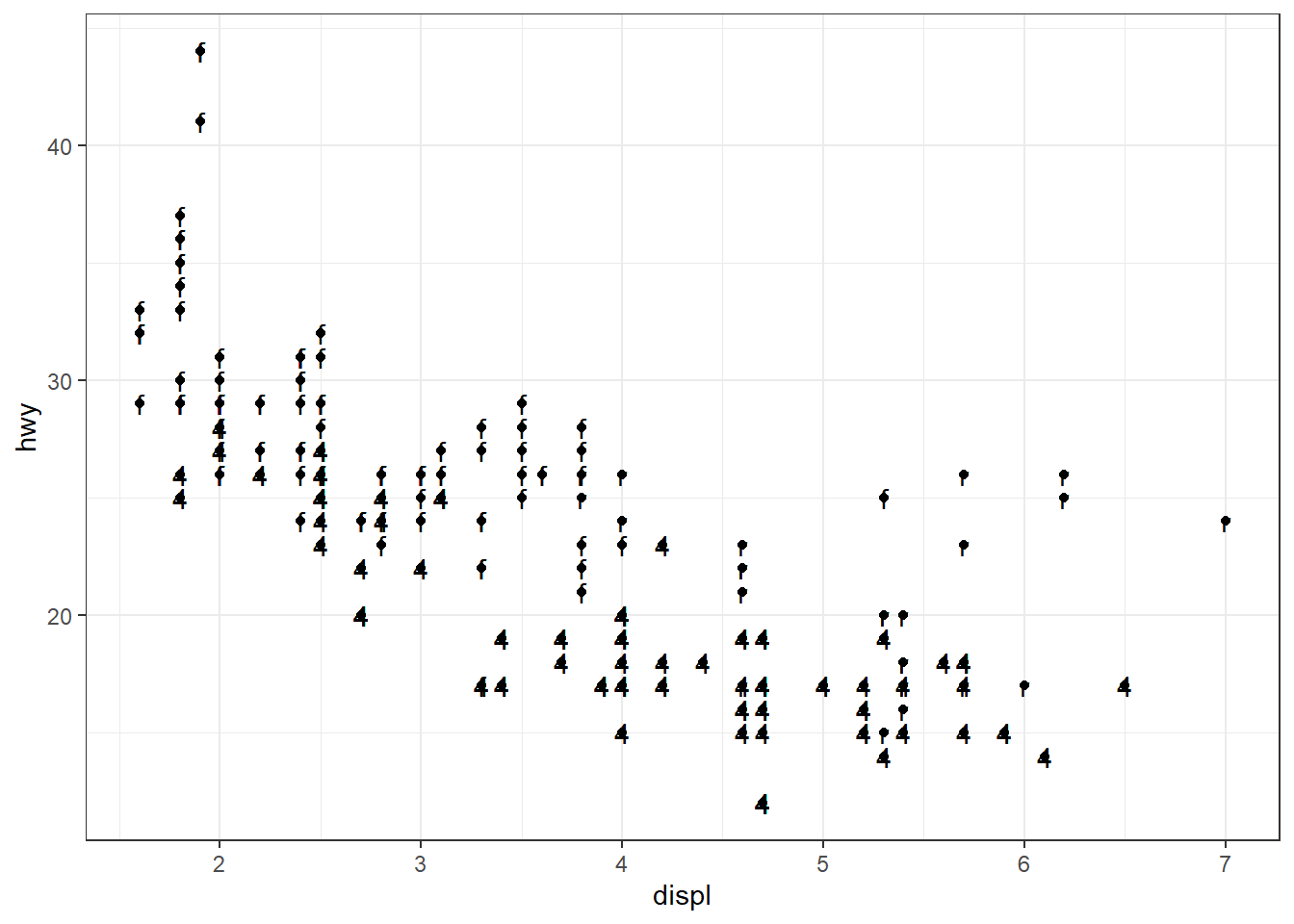
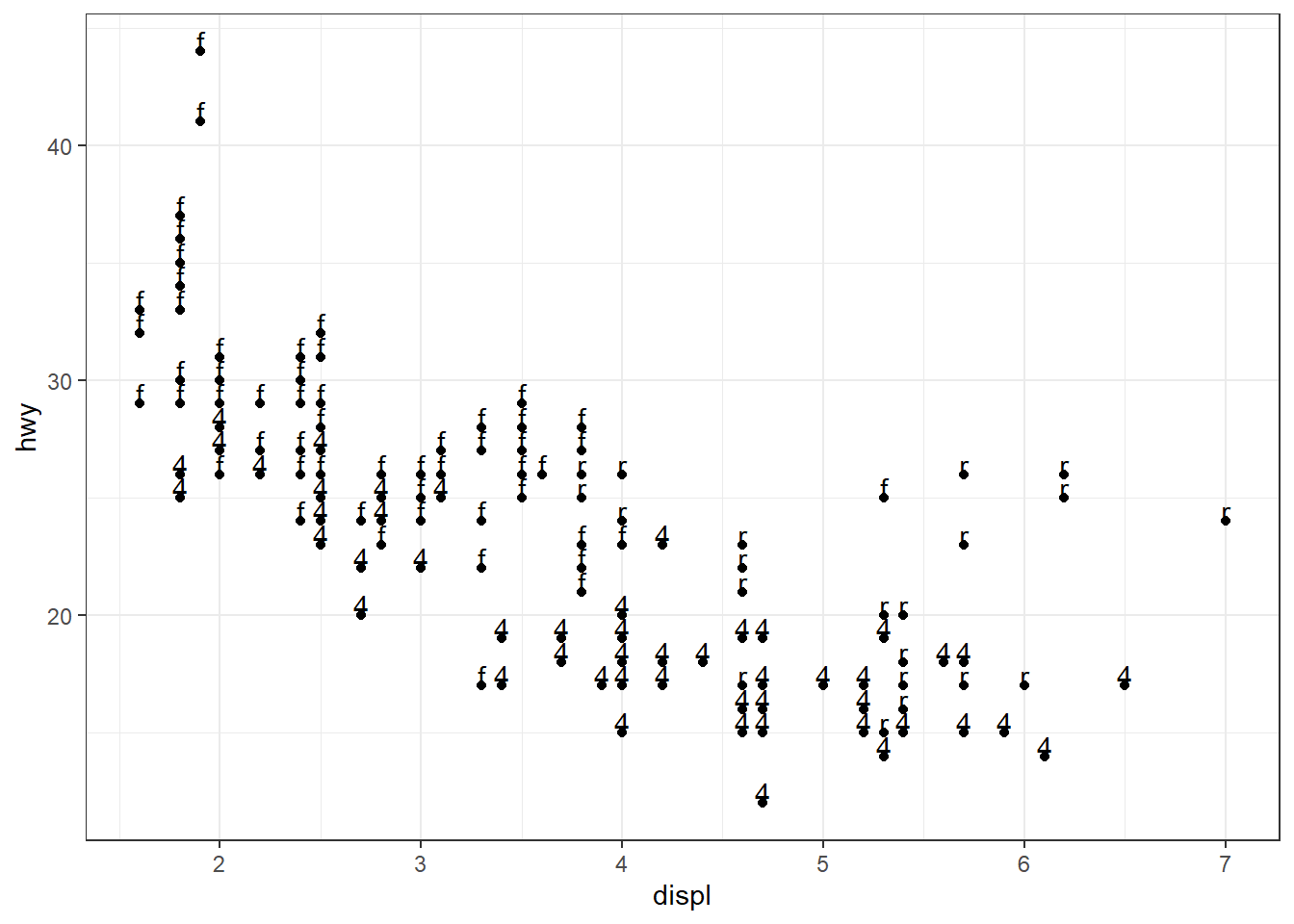
ggplot(mpg, aes(x = displ, y = hwy, label = drv)) + geom_point() +
geom_text()
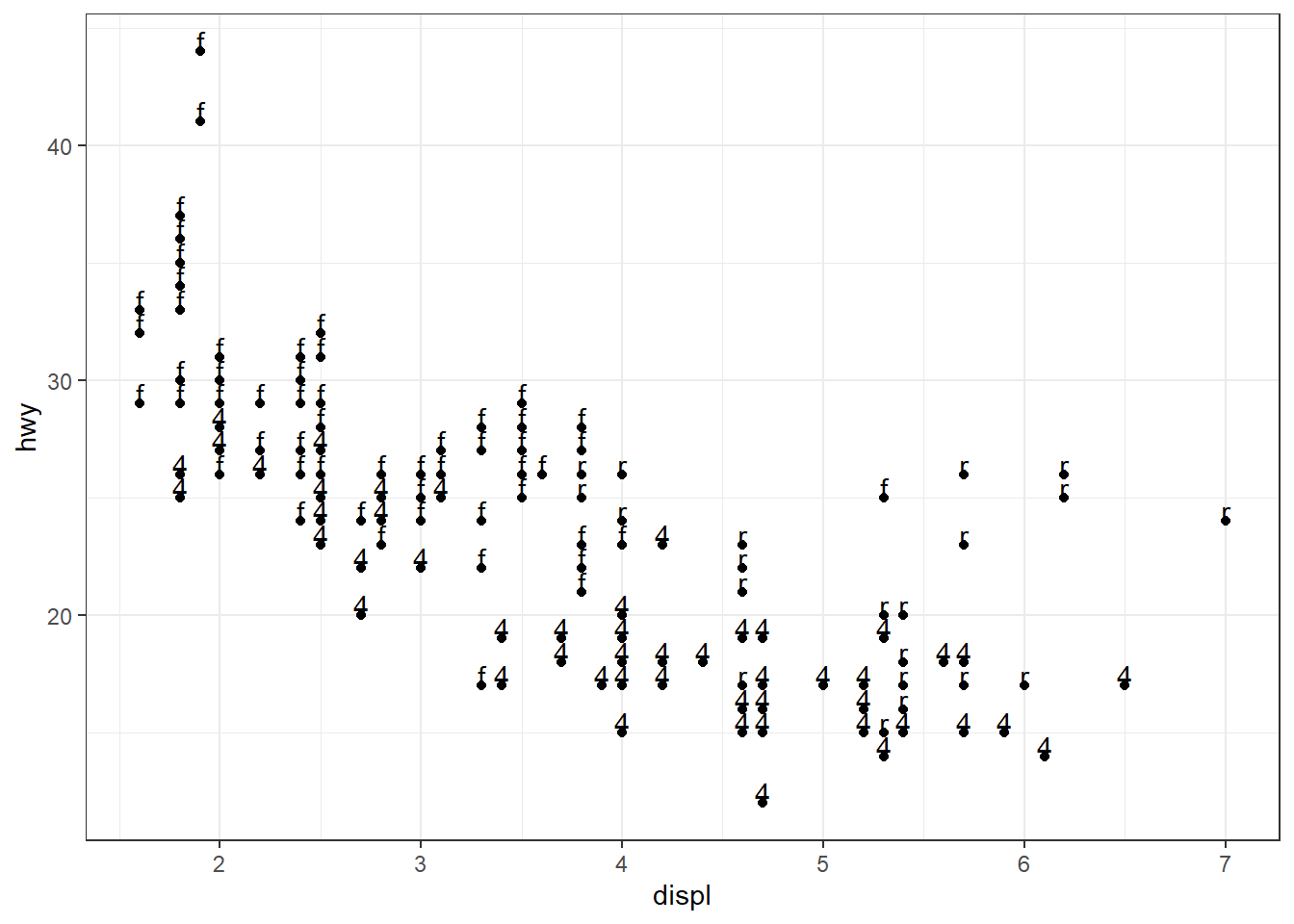
ggplot(mpg, aes(x = displ, y = hwy, label = drv)) + geom_point() +
geom_text(vjust = 0, check_overlap = TRUE)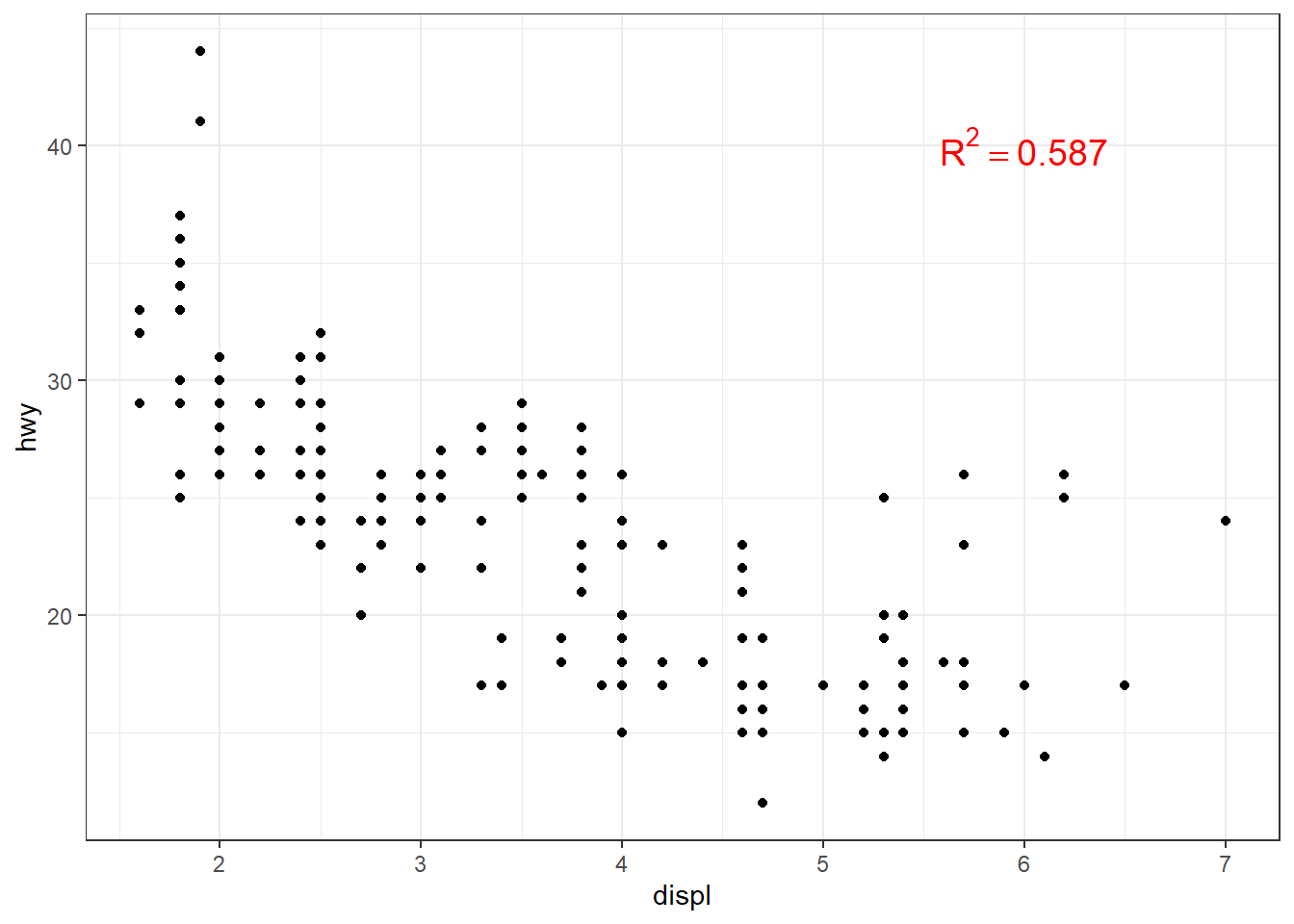
Une autre fonction utile pour ajouter des annotations de maniére ponctuelle, indépendamment des données, est annotate(). Exemple :
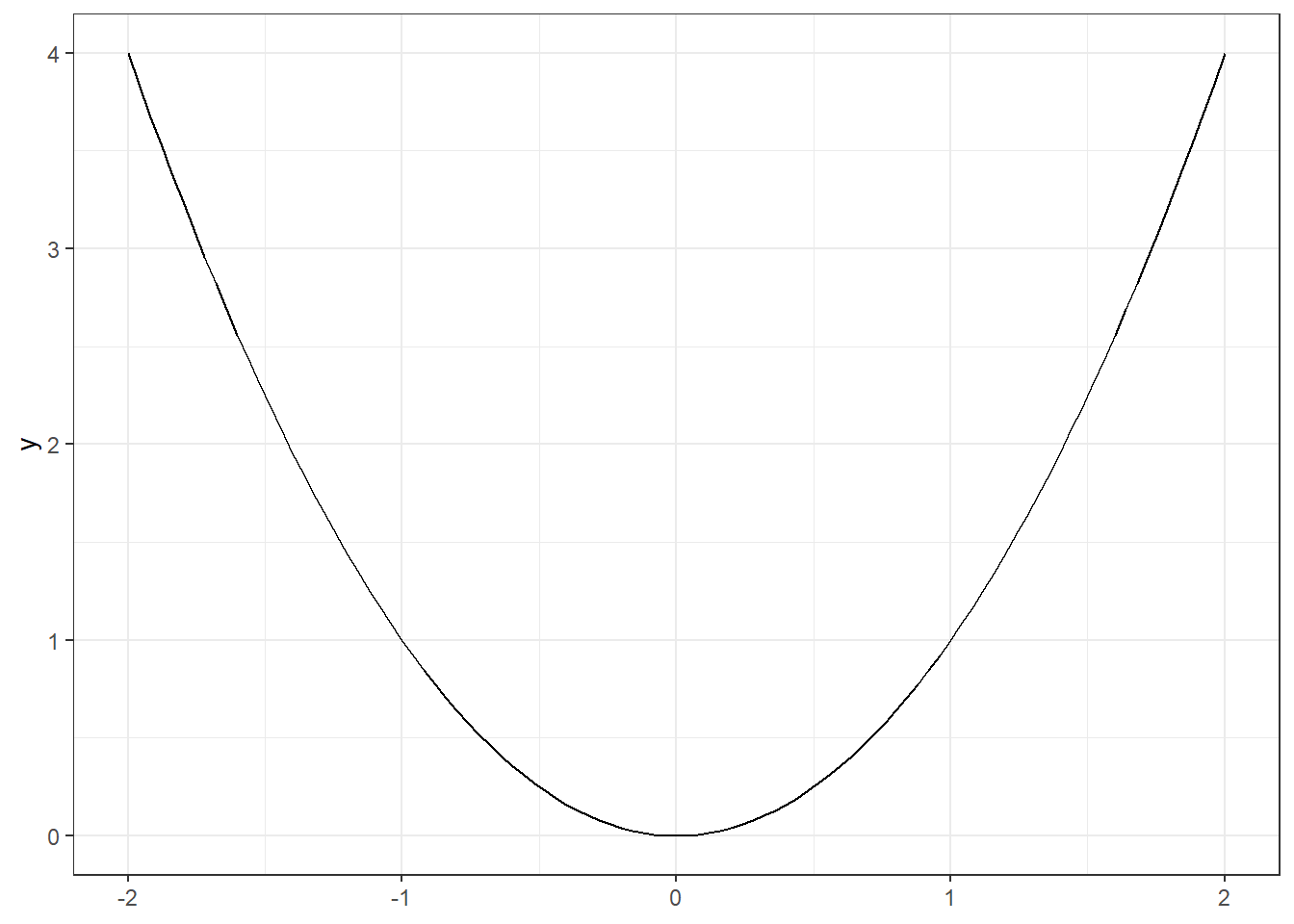
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point() +
annotate(geom = "text", # Ajout d'une annotation de type texte
x = 6, y = 40, # Position du texte sur le graphique
label = "R^2 == 0.587", # Contenu du texte : ici une formule
parse = TRUE, # Interpréter le texte comme une expression mathématique, voir ?plotmath
colour = "red", size = 5 # Style du texte,
)
Voir ?annotate pour plus d’exemples.
geom_function()
geom_function() est une fonction geom particulière, dont le rôle est de tracer la courbe d’une fonction mathématique donnée sur l’intervalle défini par l’axe des abscisses. Pour cela, geom_function() fait appel à stat_function(), qui réalise l’essentiel du travail : évaluer la fonction spécifiée via l’argument fun et générer les coordonnées nécessaires au tracé. Comme toutes les fonctions statistiques, stat_function() peut être associée à différentes géométries grâce à l’argument geom. Par défaut, elle utilise geom = "line", mais il est possible de modifier ce comportement, par exemple en choisissant geom = "point" pour afficher des points au lieu d’une courbe. Enfin, l’argument args permet de transmettre des paramètres supplémentaires à la fonction, sous la forme d’une liste nommée. Exemple :
ggplot() + geom_function(fun = \(x) x^2, xlim = c(-2, 2))
ggplot() + geom_function(fun = dnorm, args = list(mean = 0, sd = 2), xlim = c(-5, 5))
ggplot() + xlim(-5, 5) +
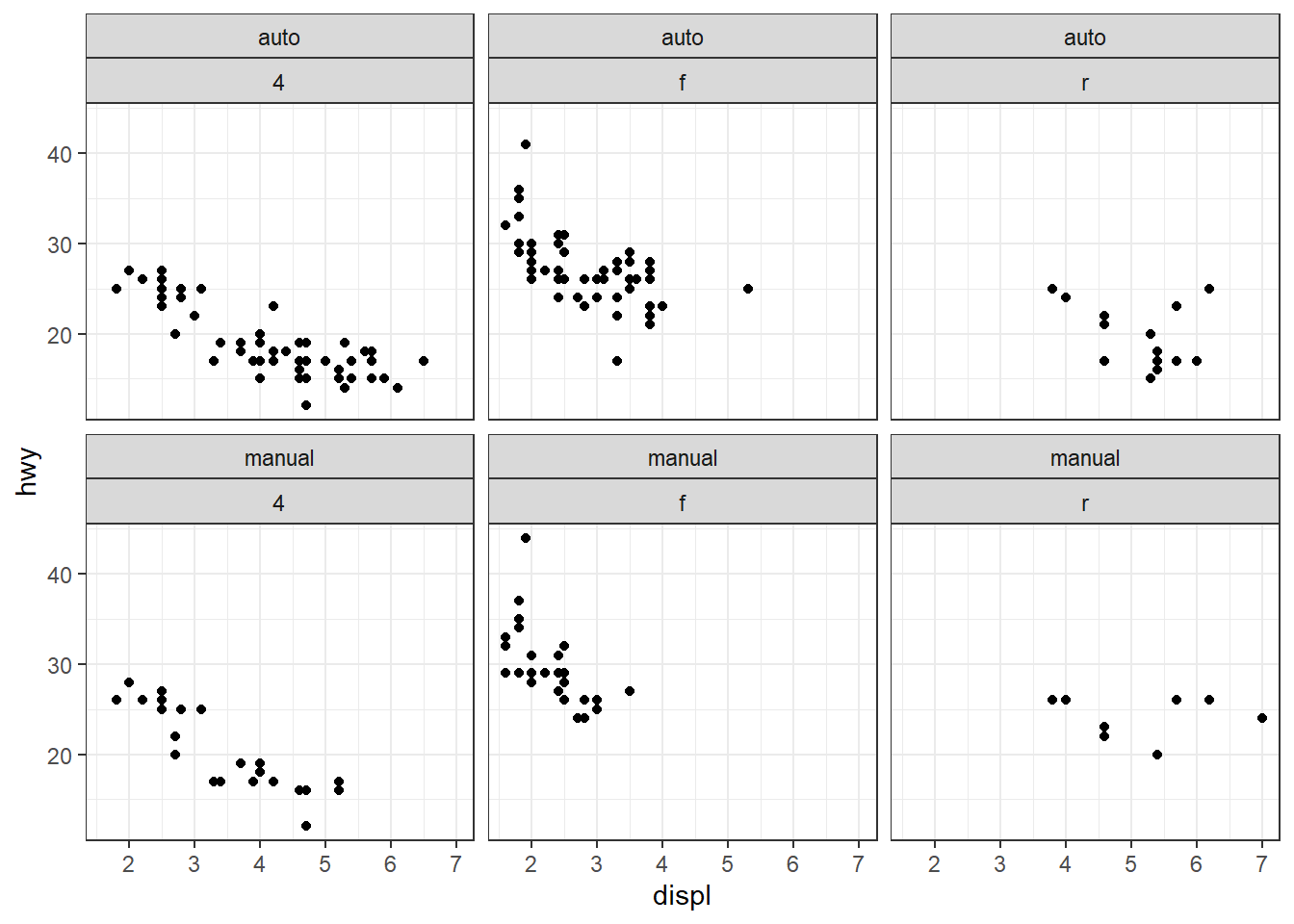
geom_function(fun = dnorm, linewidth = 1.2, mapping = aes(color = "N(0,1)")) +
stat_function(fun = dnorm, args = list(mean = 0, sd = 2), geom = "point", mapping = aes(color = "N(0,4)")) +
labs(y = "densité", color = "Distribution")
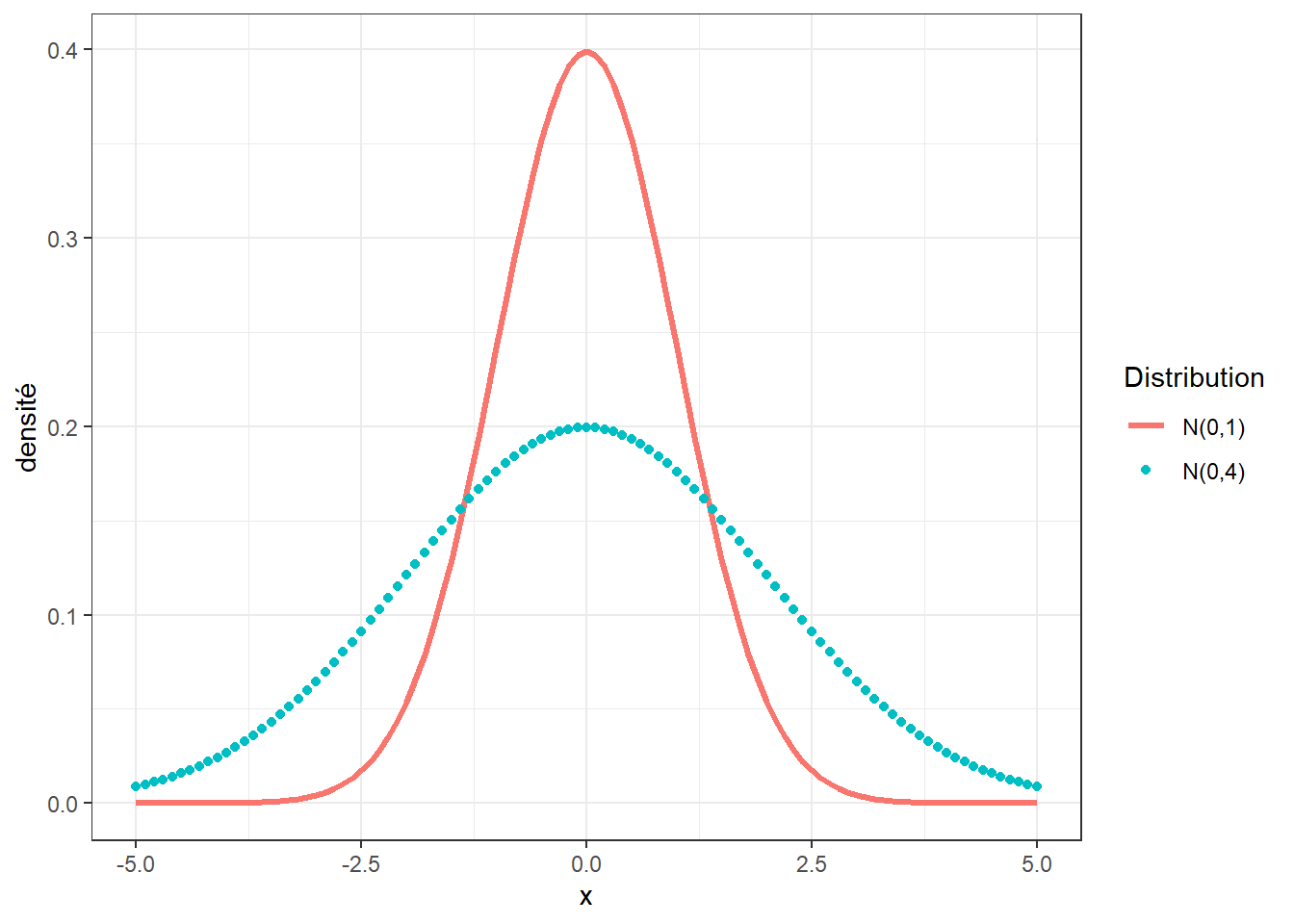
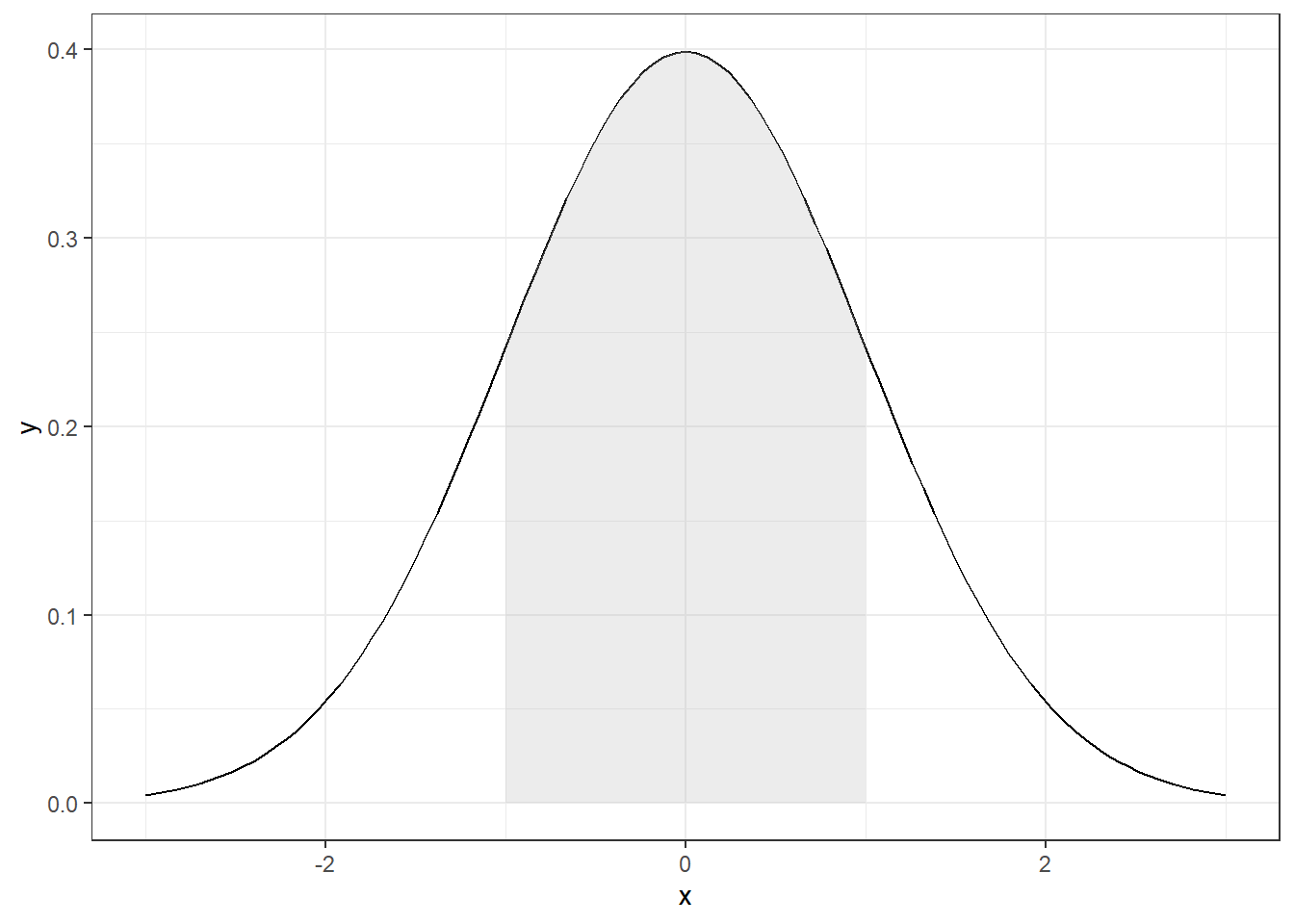
ggplot() + xlim(-3, 3) +
stat_function(fun = dnorm) +
stat_function(fun = dnorm, xlim = c(-1, 1), geom = "area", fill = "gray", alpha = .3)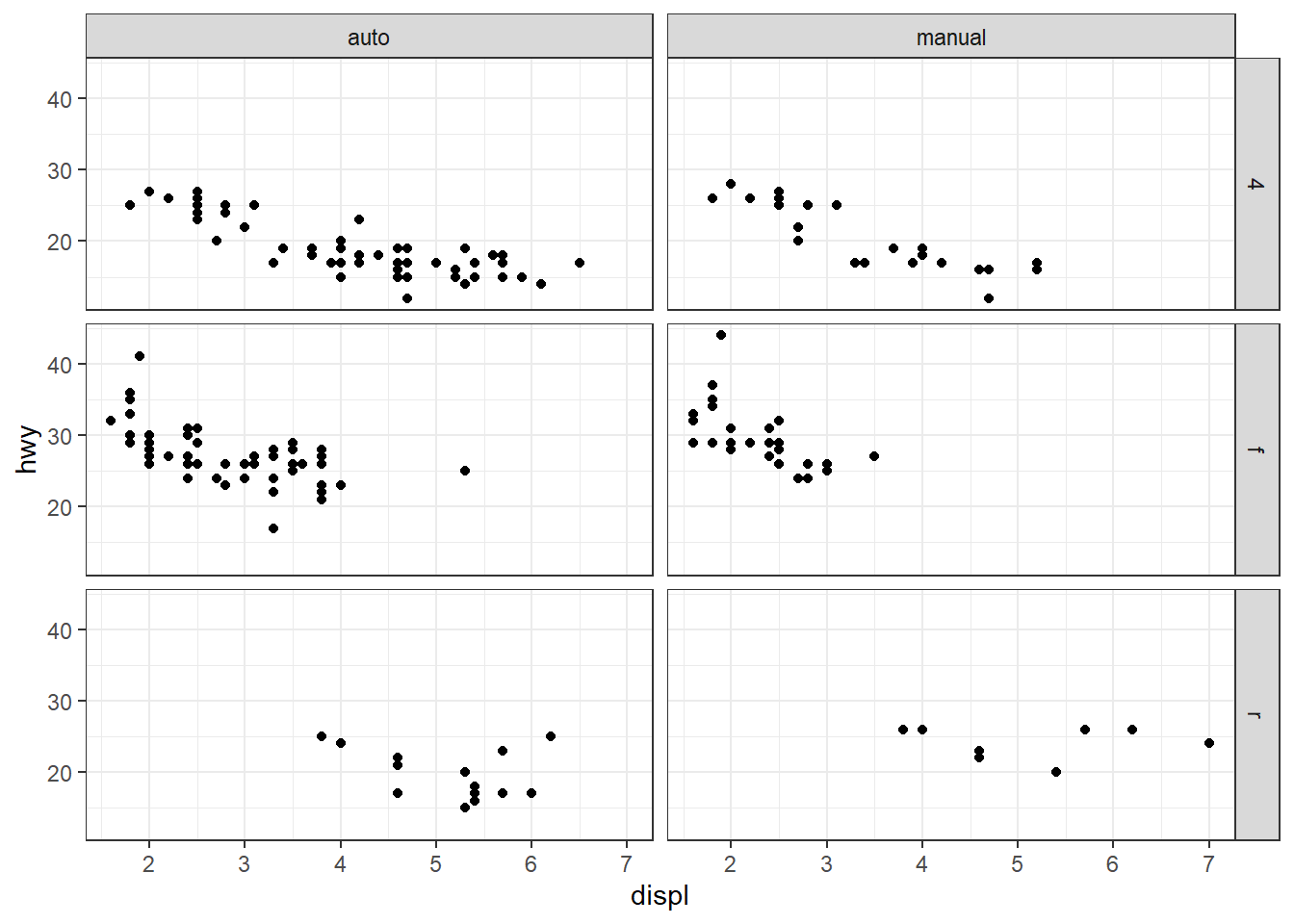
12.4 Faceting
Le faceting sert à découper un graphique en une figure composée de plusieurs panneaux, chacun (appelé facette) correspondant à un sous‑ensemble des données. Dans ggplot, deux fonctions permettent de réaliser ce découpage : facet_grid() et facet_wrap().
-
facet_grid()organise les facettes sous forme de matrice de graphiques, selon les variables/facteurs spécifiées en lignes (rows) et en colonnes (cols). -
facet_wrap()dispose les facettes sous forme d’une suite (les unes à la suite des autres) répartit automatiquement sur plusieurs lignes ou colonnes en fonction de l’espace disponible. L’argumentfacetssert à indiquer la ou les variables/facteurs selon lesquelles les données doivent être découpées.
ggplot(mpg, aes(displ, hwy)) + geom_point() +
facet_grid(row = vars(drv), cols = vars(trans))
# ou, de façon équivalente : facet_grid(drv ~ trans)
ggplot(mpg, aes(displ, hwy)) + geom_point() +
facet_wrap(vars(trans, drv))
# ou, de façon équivalente : facet_wrap(~ trans + drv)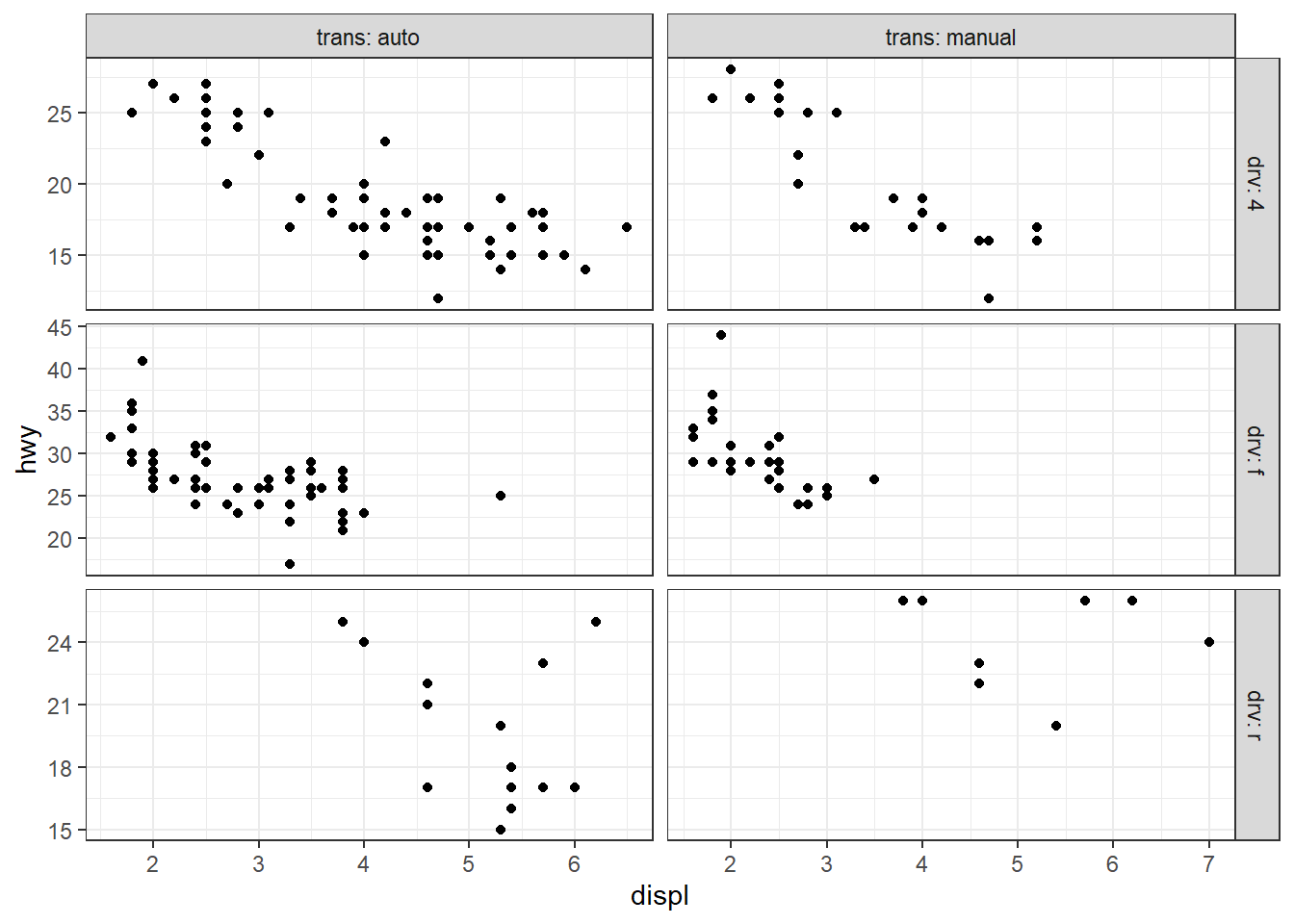
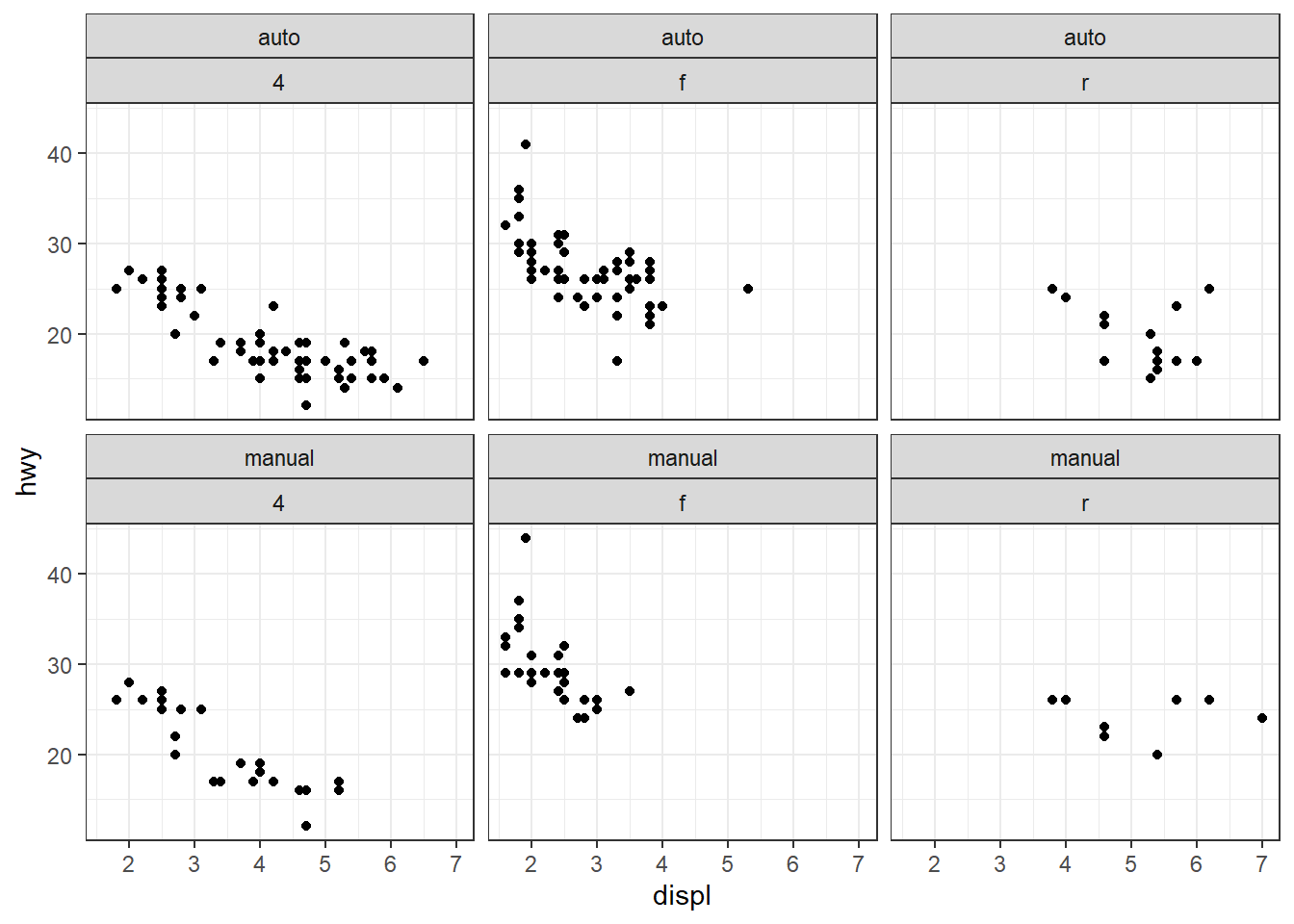
La fonction vars() qui enveloppe les noms des variables joue un rôle similaire à aes() mais appliqué au faceting : elle indique à ggplot d’aller chercher les colonnes correspondantes dans le dataframe fourni. Dans la syntaxe formula (facet_grid(drv ~ trans)), on n’a pas besoin de vars() car la formule est une construction native du langage R : les noms qui y figurent sont automatiquement interprétés comme des variables du dataframe utilisé.
Par défaut, chaque facette est accompagnée d’un label qui indique la valeur du facteur utilisé pour le découpage. Les échelles des axes sont également fixées et identiques pour toutes les facettes. Il est toutefois possible de modifier ces deux éléments grâce aux arguments labeller et scales. Par défaut, scales = fixed → impose des axes identiques, scales = free_x → libèrer l’axe des x, scales = free_y → libèrer l’axe des y, et scales = free → libèrer les deux axes. Par défaut, labeller = label_value → affiche uniqument la valeur du facteur , et labeller = label_both → afficher à la fois le nom et la valeur du facteur; voir ?labeller et ?label_both pour plus d’exemples et de détails.
ggplot(mpg, aes(displ, hwy)) + geom_point() +
facet_grid(row = vars(drv), cols = vars(trans), labeller = label_both, scales = "free")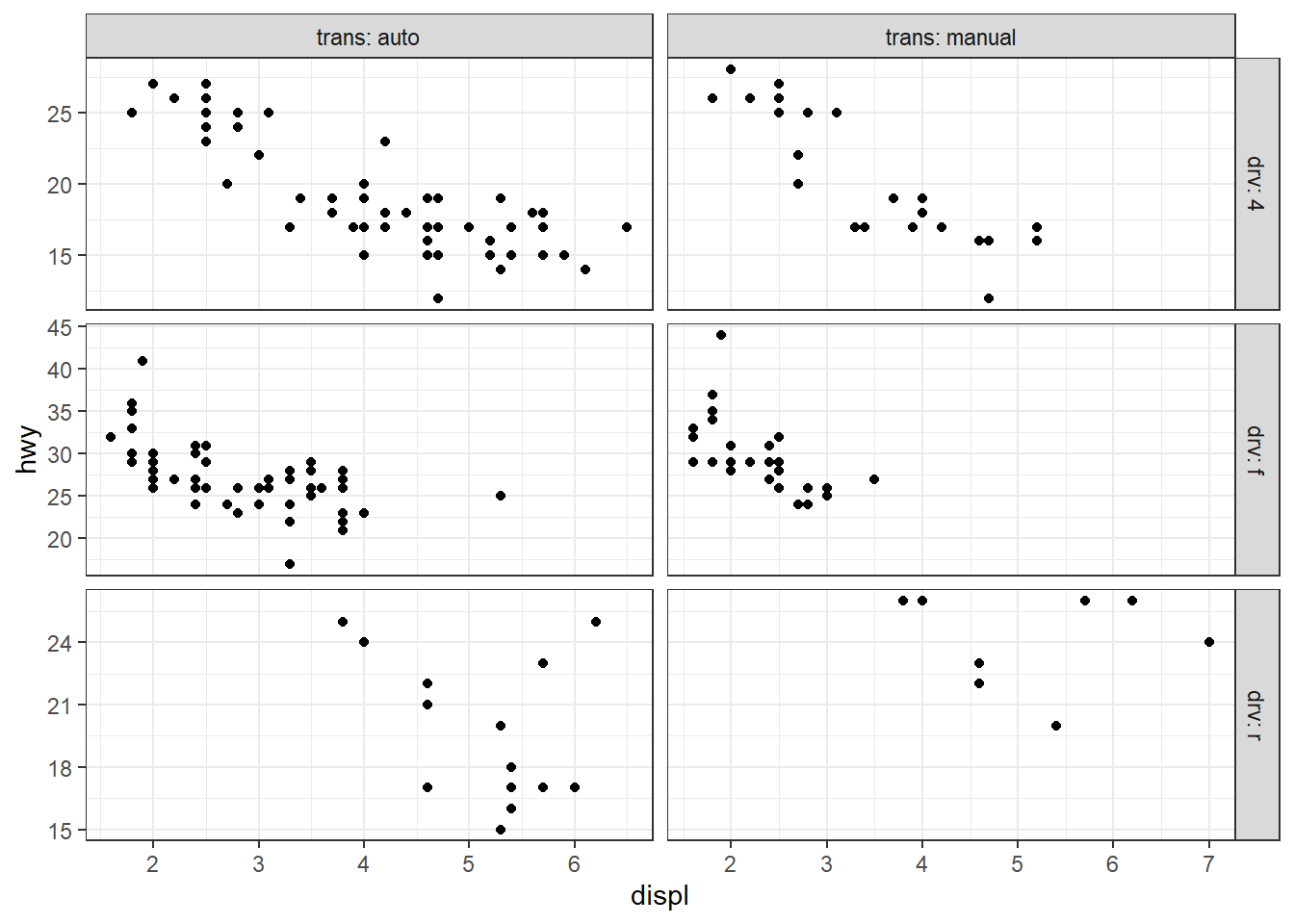
12.5 Extensions ggplot
Il existe un grand nombre d’extensions pour ggplot. Vous pouvez consulter cette galerie afin de découvrir la diversité des possibilités offertes. Dans les sections qui suivent, nous en explorerons quelques-unes plus en détail.
Esquisse : créer des ggplot de manière interactive
Esquisse est un package R qui permet de créer des graphiques ggplot de manière interactive, simple et rapide. Il génère en parallèle le code correspondant. Après chargement :
l’utilisation du package esquisse peut se faire avec la commande :
esquisse::esquisser(<data>, viewer = "browser")où <data> correspond au nom du jeu de données à analyser, par exemple mpg. Il est également possible d’utiliser la commande :
esquisse::esquisser(viewer = "browser")sans préciser de dataframe. Dans ce cas, une fenêtre s’ouvre en superposition et invite à sélectionner la dataframe à explorer. Les données à représenter peuvent aussi être choisies en cliquant sur l’icône en forme de cylindre, placée dans le coin supérieur gauche.
La liste des variables de la dataframe apparaît en haut de la fenêtre d’Esquisse. Elles peuvent être glissées dans les zones « X », « Y », « Fill », « Color », etc., afin d’établir des correspondances (mapping) entre les paramètres aesthetics et les variables sélectionnées. Le graphique réagit automatiquement aux actions effectuées et se met à jour en conséquence.
La vidéo suivante offre un aperçu des différentes possibilités.
Par défaut, esquisse sélectionne le type de graphique le plus adapté à la nature des variables. Il est toutefois possible de choisir un autre type de graphique à l’aide de l’icône « Auto » située dans le coin supérieur gauche.
Les menus situés en bas de l’interface permettent de personnaliser les titres, les thèmes, les couleurs ainsi que d’autres éléments influençant l’aspect global du graphique. Une fois la personnalisation terminée, le code R généré automatiquement peut être conservé en utilisant la rubrique « Code » placée en bas de la fenêtre d’Esquisse. Consulter la page officielle du package pour davantage d’informations.
Patchwork : combiner et organiser des graphiques
Le package patchwork est une extension de R conçue pour faciliter la composition de plusieurs graphiques ggplot dans une seule figure.
Patchwork repose sur une syntaxe simple et expressive : + → asemble les graphiques les uns après les autres sous forme d’une grille; | → place les graphiques côte à côte sur une même ligne; et / → empile les graphiques verticalement. En combinant ces opérateurs, il est possible de construire des agencements complexes, et l’usage de parenthèses permet de préciser la hiérarchie des opérations afin d’obtenir la disposition souhaitée.
Afin de souligner l’intérêt de ce package, nous procéderons, comme à l’accoutumée, par des exemples. Commençons donc par le charger :
On peut assembler deux ggplots facimlement comme suite :
{ggplot(mpg, aes(x = displ, y = hwy)) + geom_point()} +
{ggplot(mpg, aes(x = drv, y = hwy)) + geom_boxplot()}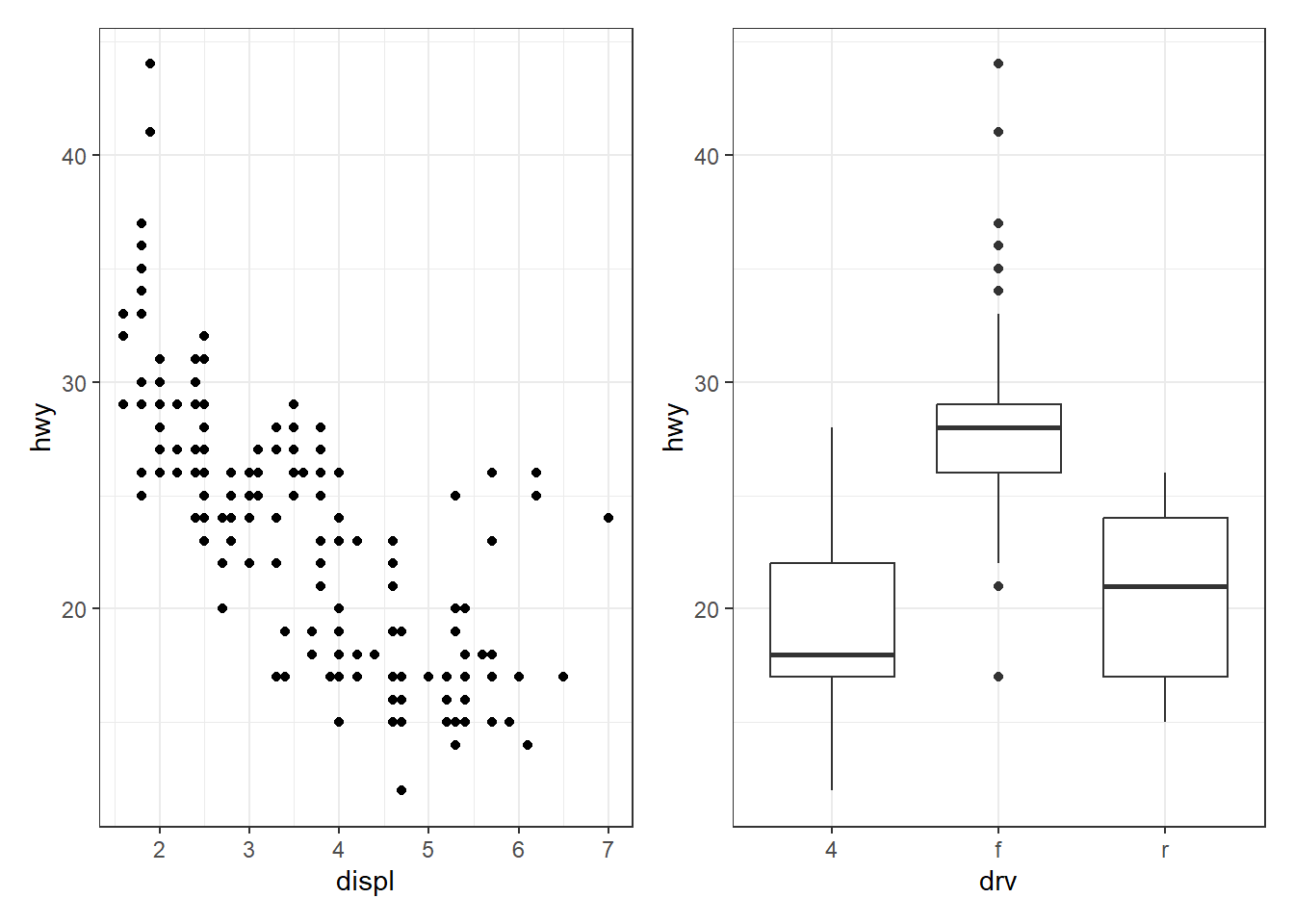
Le plus souvent, les ggplot sont stockés avant d’être combinés, ce qui rend le code plus lisible. Exemple :
p1 <- ggplot(mpg, aes(x = displ, y = hwy, col = drv)) + geom_point()
p2 <- ggplot(mpg, aes(x = drv, y = hwy, col = drv)) + geom_boxplot(show.legend = FALSE)
p3 <- ggplot(mpg, aes(x = hwy)) + geom_histogram(bins = 9, color = "white")
p4 <- ggplot(mpg) + geom_jitter(aes(x = displ, y = ""), width = 0, height = 0.2, alpha = 0.5) + labs(y = NULL)# Empile p1 et p2, et p3 et p4, puis juxtaposer
(p1 / p2) | (p3 / p4)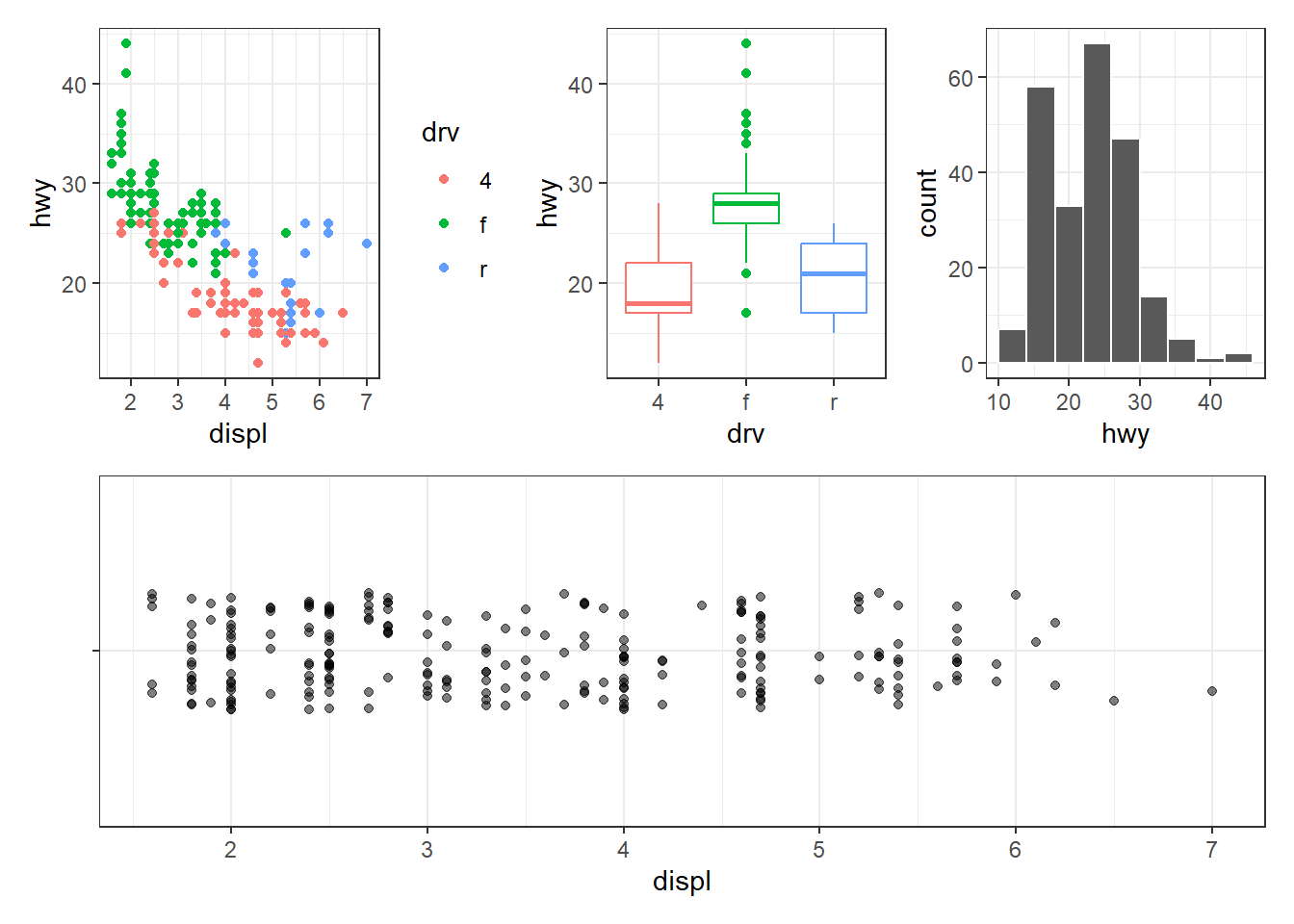
# Place p1, p2 et p3 côte à côte, puis empile ce bloc au-dessus de p4
(p1 | p2 | p3) / p4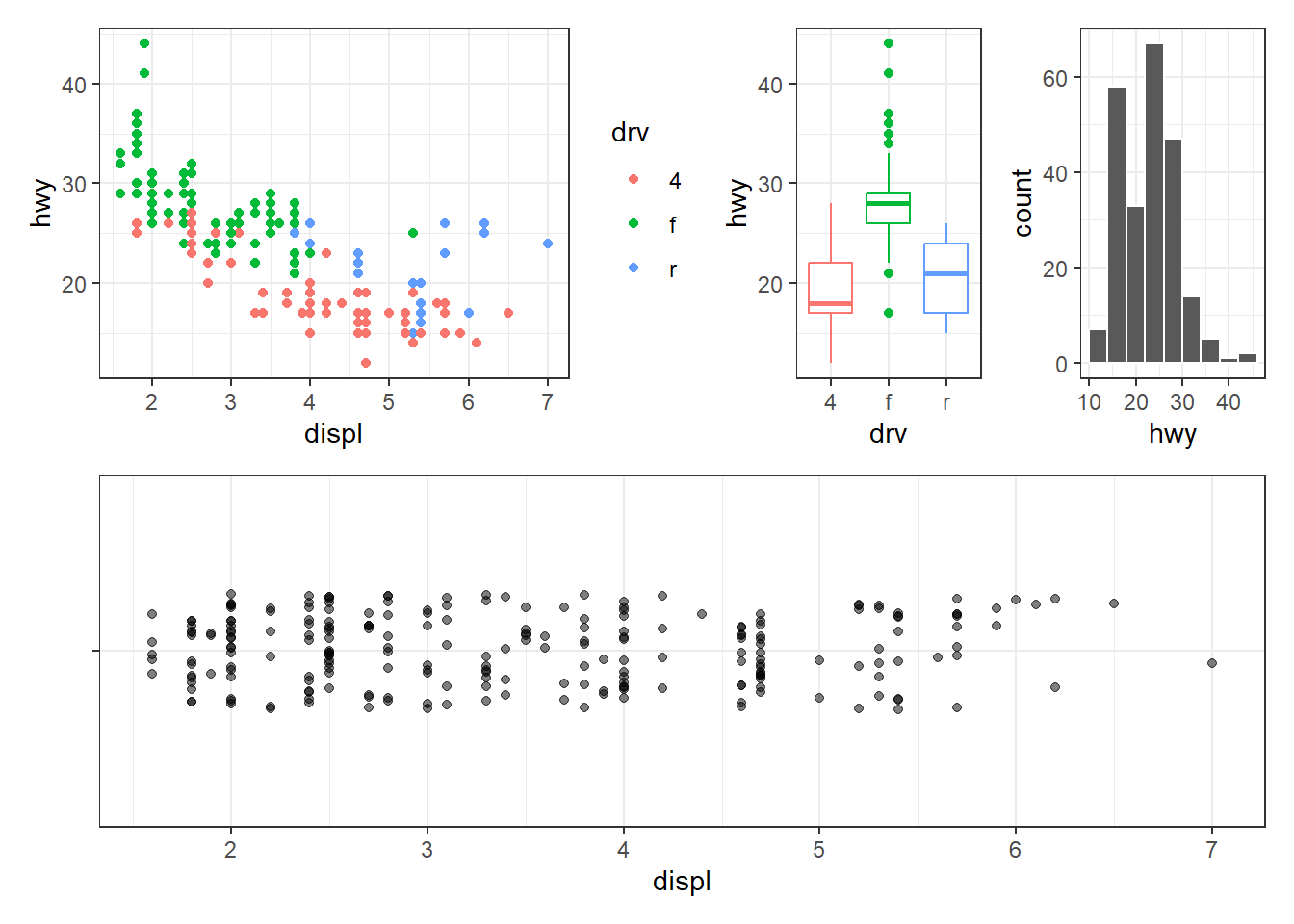
# Place p2 et p3 côte à côte, place ce bloc à droite de p1, puis empile l'ensemble au-dessus de p4
(p1 | (p2 | p3)) / p4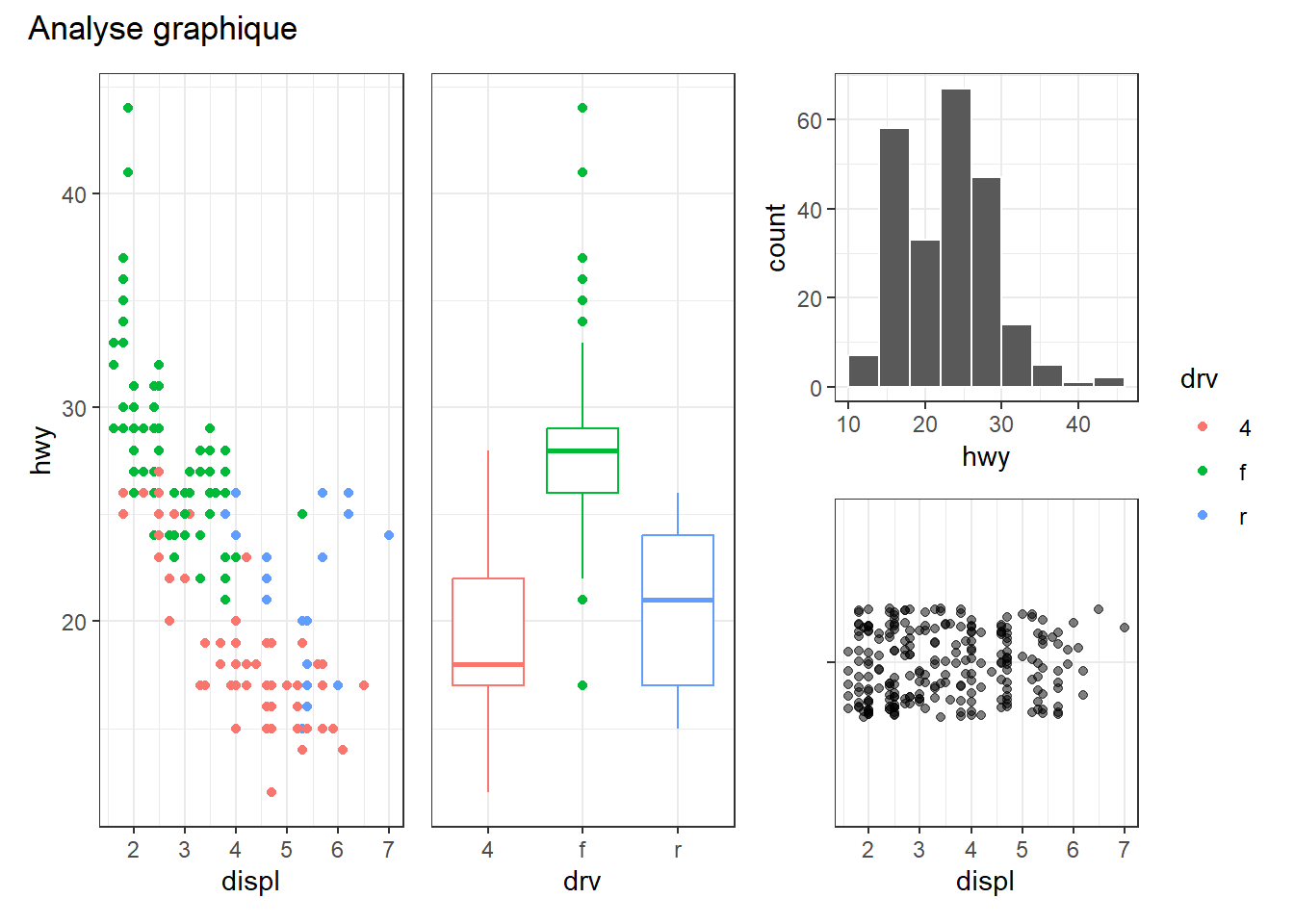
La fonction plot_layout() permet de contrôler plus finement la disposition des graphiques. Elle offre des options comme : ncol et nrow → définir explicitement le nombre de colonnes ou de lignes; guides = "collect" → rassembler les légendes en supprimant les doublons; et axes = "collect" et axis_titles = "collect" → éviter les redondances en mutualisant les axes et leurs titres. La fonction plot_annotation() permet quant à elle d’ajouter des annotations globales. Exemple :
# Place p1, p2 et p3 côte à côte, empile p4 sous p3,
# puis harmonise guides et axes sur l’ensemble
(p1 | p2 | p3 / p4) +
plot_layout(guides = "collect", axes = "collect") +
plot_annotation(title = "Analyse graphique")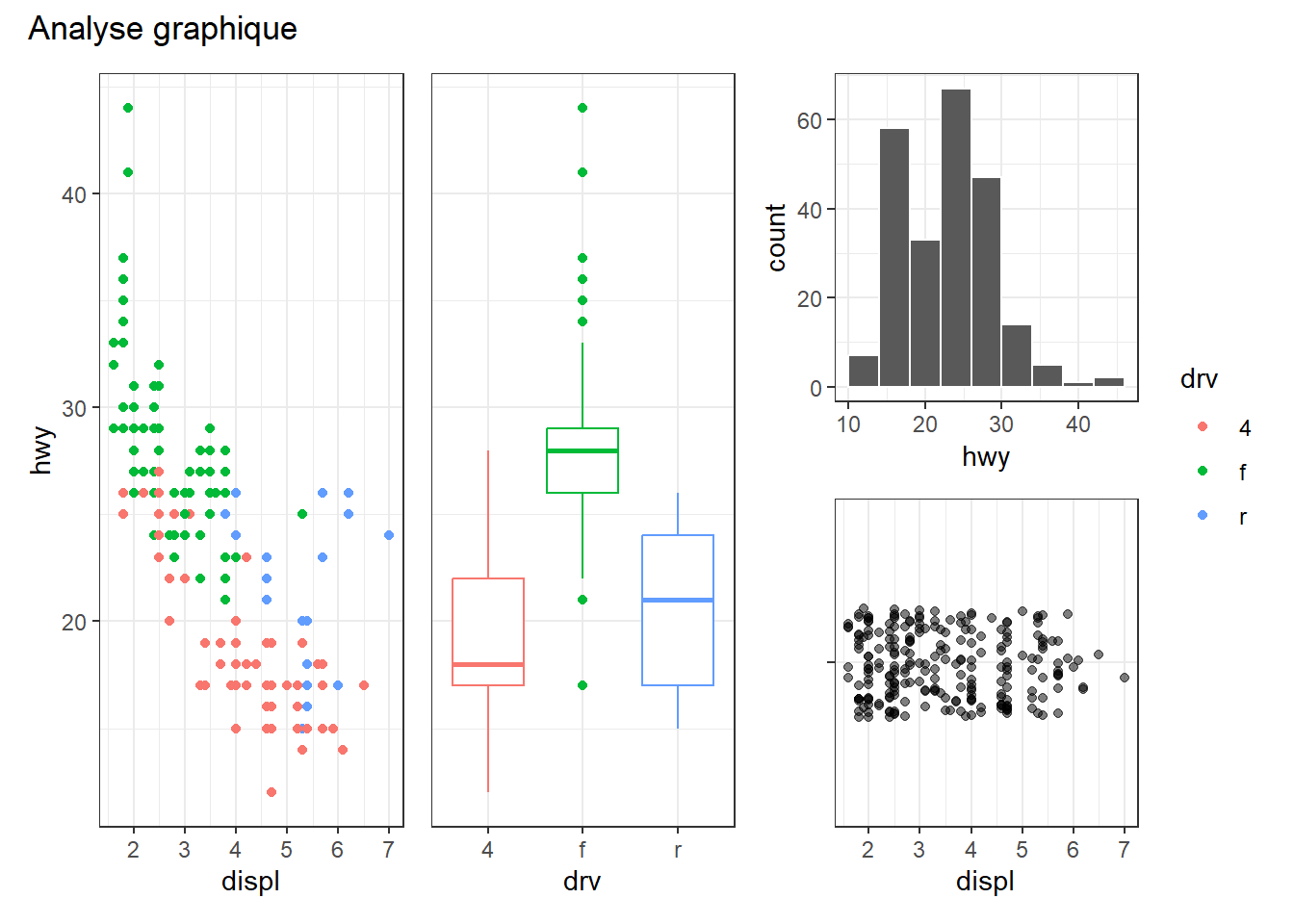
Patchwork offre bien davantage de possibilités de manipulation. Pour en savoir plus, consultez la documentation officielle.
Plotly : graphiques interactifs
Plotly est une bibliothèque JavaScript dédiée aux graphiques interactifs. Le package R plotly agit comme une interface qui permet d’utiliser ce système graphique directement dans R.
La fonction ggplotly() du package plotly peut être utilisée pour transformer certains graphiques ggplot en graphiques plotly interactifs, sans devoir recourir directement à la syntaxe native de plotly. Cette interactivité se traduit par : (i) un graphique qui réagit au passage de la souris, et (ii) une barre d’outils qui apparaît dans le coin supérieur droit, permettant de zoomer et de se déplacer le long des axes, entre autres fonctions. Ce faisant, ggplotly() modifie certains éléments du graphique, tels que la taille des points, l’échelle des axes ou l’emplacement de la légende. Voici quelques exemples.
Il est également possible de créer des animations dites “par trames” avec ggplotly(). Pour cela, on utilise l’esthétique frame, qui permet de définir la variable selon laquelle le graphique évoluera. Chaque modalité de la variable spécifiée dans frame correspond à une étape (ou trame) de l’animation. Le graphique affiche successivement ces trames, et l’utilisateur peut les parcourir grâce à une barre de contrôle qui apparaît sous la figure. Celle‑ci propose un bouton “Play” pour lancer ou arrêter l’animation, ainsi qu’un curseur permettant de naviguer manuellement entre les différentes trames. La fonction animation_opts() complète ce dispositif en offrant la possibilité de régler la durée d’affichage de chaque trame et la vitesse des transitions, exprimées en millisecondes. L’ensemble transforme ainsi un graphique statique en une visualisation dynamique, particulièrement utile pour explorer des données évolutives ou comparer des groupes successifs.
Voici un exemple :
p <- ggplot(mpg, aes(x = displ, y = hwy)) + geom_point()
ggplotly(p + aes(frame = class)) |> # add a frame aesthetic to animate the plot by 'class'
animation_opts(frame = 1500, # duration for each frame (milliseconds)
transition = 500) # transition between frames (milliseconds)Pour plus de détails, consultez la documentation officielle.
12.6 Programmer avec ggplot
Cette section s’adresse aux lecteurs ayant déjà acquis les bases de la programmation en R, en particulier la creation de fonctions personnalisées.
Lorsqu’il est nécessaire d’écrire à plusieurs reprises les mêmes lignes de code ggplot pour produire des graphiques similaires, il peut être utile d’envisager une approche différente. Considérons, à titre d’exemple, le code suivant :
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(color = "blue", size = 2) +
geom_smooth(method = "lm", se = FALSE, linewidth = 1) +
facet_wrap(facets = vars(trans), labeller = label_both) + theme_bw()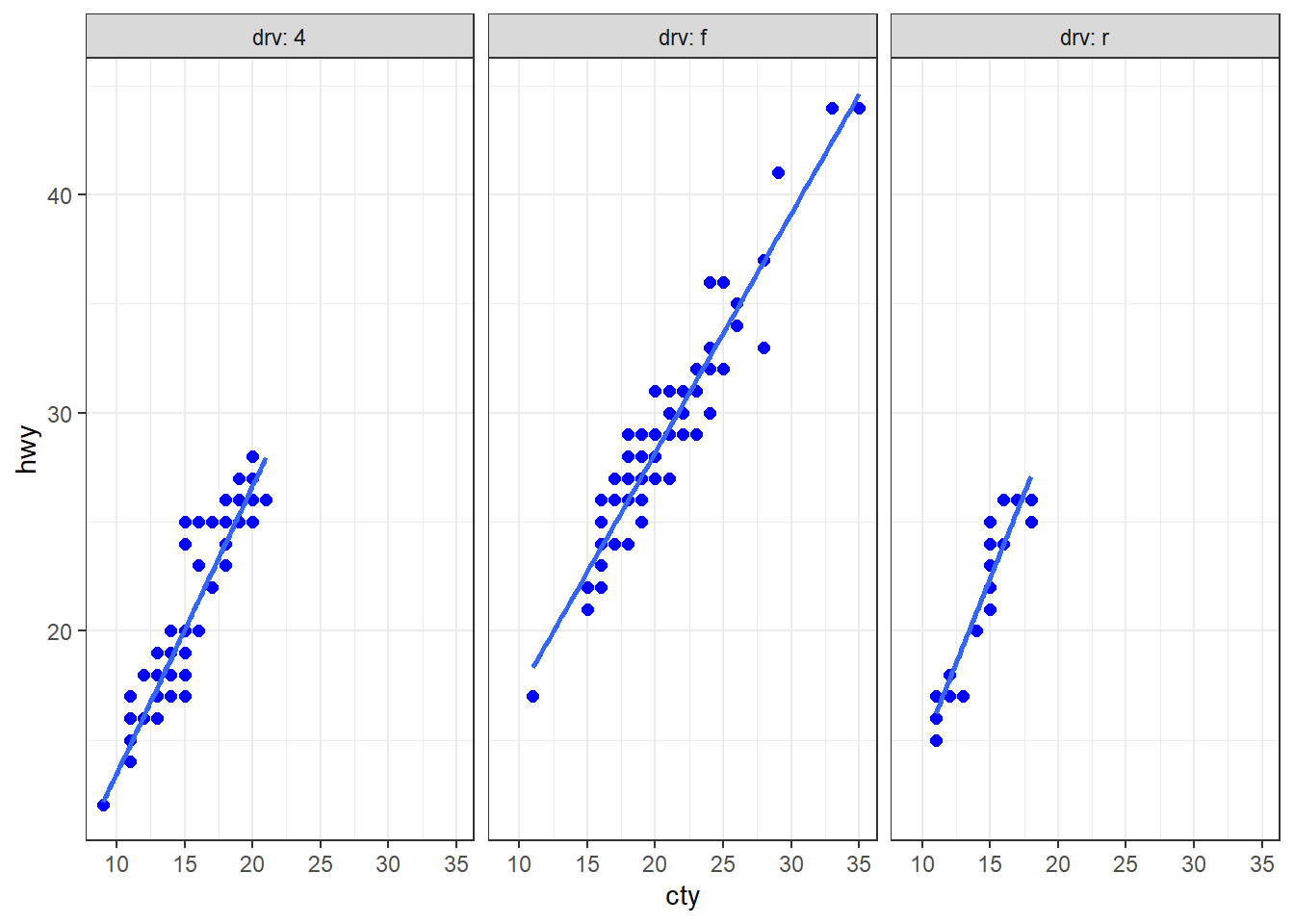
Si des éléments, non-data, tels que geom_point(color = "blue", size = 2) + geom_smooth(linewidth = 1, se = FALSE) + theme_bw() doivent être répétés à plusieurs reprises, il est possible de les sauvegarder dans une liste et de les réutiliser :
mytmp <- list(
geom_point(color = "blue", size = 2),
geom_smooth(method = "lm", se = FALSE, linewidth = 1),
theme_bw()
)
ggplot(mpg, aes(x = cty, y = hwy)) + facet_wrap(facets = vars(drv), labeller = label_both) + mytmp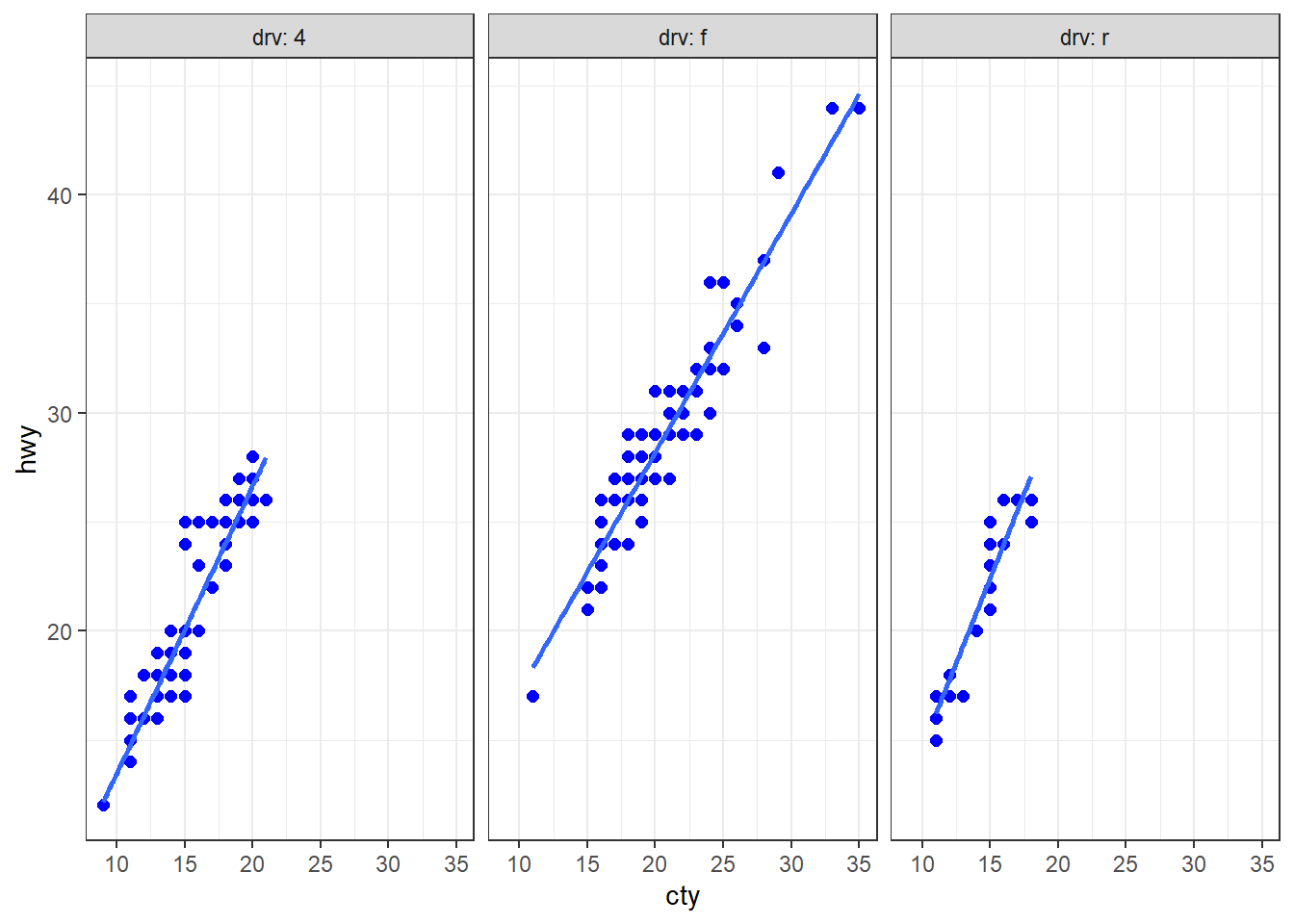
Une autre solution, plus robuste et plus générale, consiste à définir une fonction qui génère le même type de graphique, tout en permettant de modifier certains arguments. Exemple :
mytmp <- function(clr = "blue", sz = 2, ...) {
list(geom_point(color = clr, size = sz),
geom_smooth(method = "lm", se = FALSE, linewidth = 1),
theme_bw(),
facet_wrap(...))
}Notez l’utilisation de l’argument spécial ..., qui est généralement employé pour passer un nombre variable d’arguments à une fonction située à l’intérieur de la fonction que l’on appelle. Dans notre cas, la fonction mytmp() passe ... à la fonction facet_wrap(), ce qui offre une flexibilité supplémentaire.
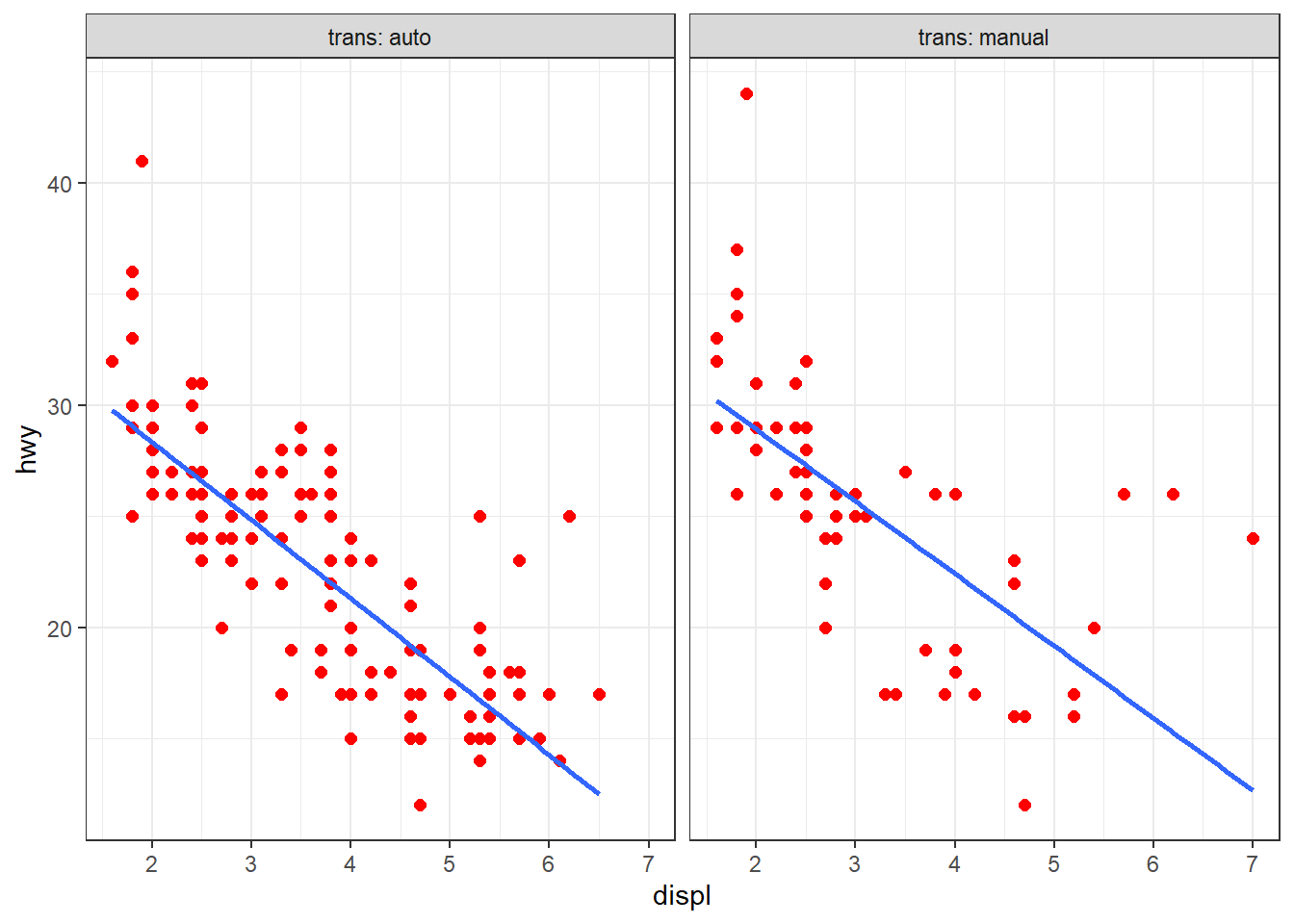
Il est possible d’aller plus loin en donnant à l’utilisateur la liberté de choisir les données et les variables à représenter, càd les objets à placer dans data, aes() et vars(). La syntaxe suivante peut être envisagée :
ggFun <- function(dt, x, y, gr) {
ggplot(dt, aes(x, y)) + geom_point(color = "blue", size = 2) +
geom_smooth(method = "lm", se = FALSE, linewidth = 1) +
facet_wrap(vars(gr), labeller = label_both) + theme_bw()
}Par la suite, écrire ggFun(mpg, displ, hwy, trans) devrait produire le graphique correspondant. Cependant, cette écriture génère des erreurs. La raison est que les fonctions aes() et vars(), comme de nombreuses fonctions du Tidyverse, reposent sur une évaluation non standard appelée tidy-evaluation. Ce mécanisme simplifie la saisie du code, puisqu’il n’est pas nécessaire de répéter systématiquement le nom de la dataframe utilisée. Par exemple, il n’est pas requis d’écrire ggplot(mpg, aes(x = mpg$displ, y = mpg$hwy)) + geom_point(), mais simplement ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(). Cette facilité entraîne cependant des difficultés lors de la programmation avec ces fonctions. En pratique, lorsque l’on saisit ggFun(mpg, displ, hwy, trans), R est conçu pour cherche mpg, displ, hwy et trans dans l’environnement de travail; or, à l’exception de mpg, ces objets n’y figurent pas, ce qui provoque des erreurs.
La façon la plus simple de remédier à ce problème, tout en conservant une écriture concise, consiste à utiliser l’opérateur {{}}. Ce dernier indique à ggplot qu’il doit remplacer les noms passés dans aes() ou vars() par les arguments fournis dans l’appel de la fonction avant de les chercher dans le dataframe. Voici la version corrigée du code ci‑dessous :
ggFun <- function(dt, x, y, gr) {
ggplot(dt, aes({{ x }}, {{ y }})) + geom_point(color = "blue", size = 2) +
geom_smooth(method = "lm", se = FALSE, linewidth = 1) +
facet_wrap(vars({{ gr }}), labeller = label_both) + theme_bw()
}Cette approche permet d’appeler la fonction ggFun() avec les données et variables souhaitées. Exemple :
ggFun(mpg, cty, hwy, drv)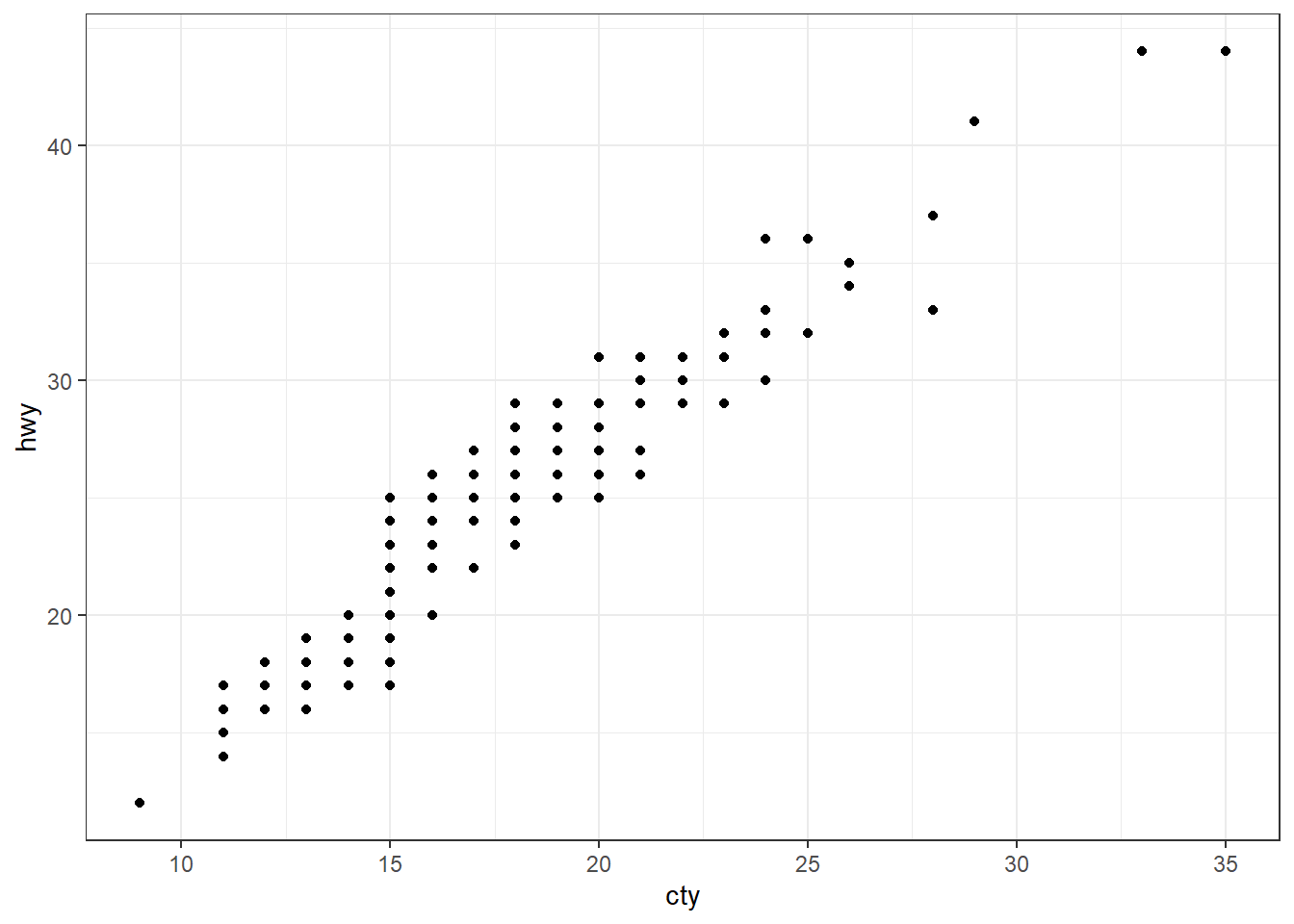
Une autre possibilité consiste à utiliser le pronom spécial .data, qui permet à ggplot d’accéder aux colonnes d’une dataframe lorsque leurs noms sont transmis sous forme de chaînes de caractères et non comme symbole nu (non quoté). Exemple :
ggplot(mpg, aes(x = .data[["cty"]], y = .data[["hwy"]])) + geom_point()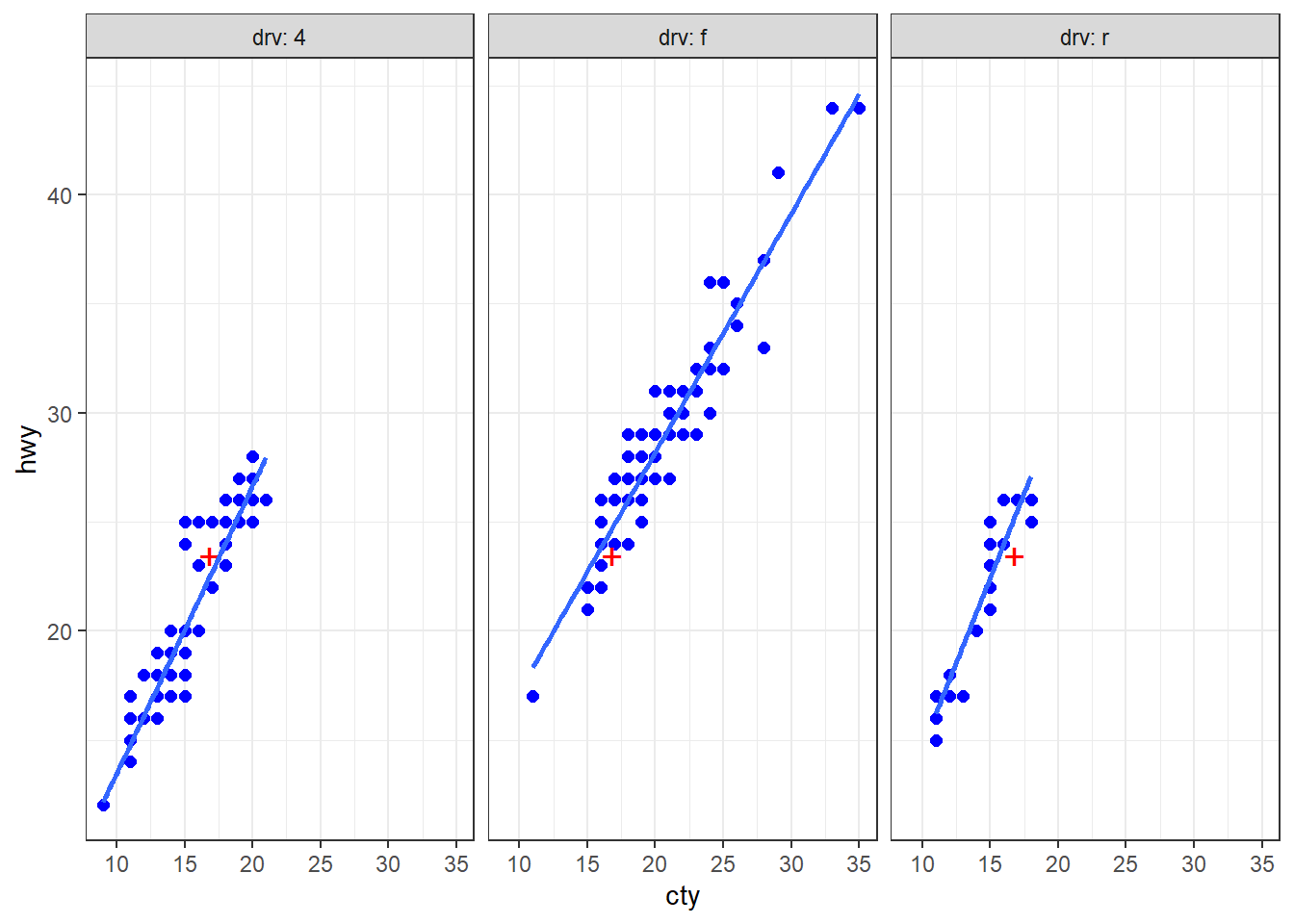
Ce mécanisme peut être exploité pour programmer des fonctions plus complexes, dans lesquelles il est possible, par exemple, de combiner du code R classique avec du code ggplot. Exemple :
ggFun <- function(df, x, y, gr) {
# Code R classique : calcul les moyennes
mx <- mean(df[[x]], na.rm = TRUE)
my <- mean(df[[y]], na.rm = TRUE)
# Code ggplot : création du graphique
p <- ggplot(df, aes(.data[[x]], .data[[y]])) +
geom_point(color = "blue", size = 2) +
annotate(geom = "point", shape = "+", x = mx, y = my, size = 5, color = "red") +
geom_smooth(method = "lm", se = FALSE, linewidth = 1) +
facet_wrap(vars(.data[[gr]]), labeller = label_both) +
theme_bw()
return(p)
}
# Exemple d'appel
ggFun(mpg, "cty", "hwy", "drv")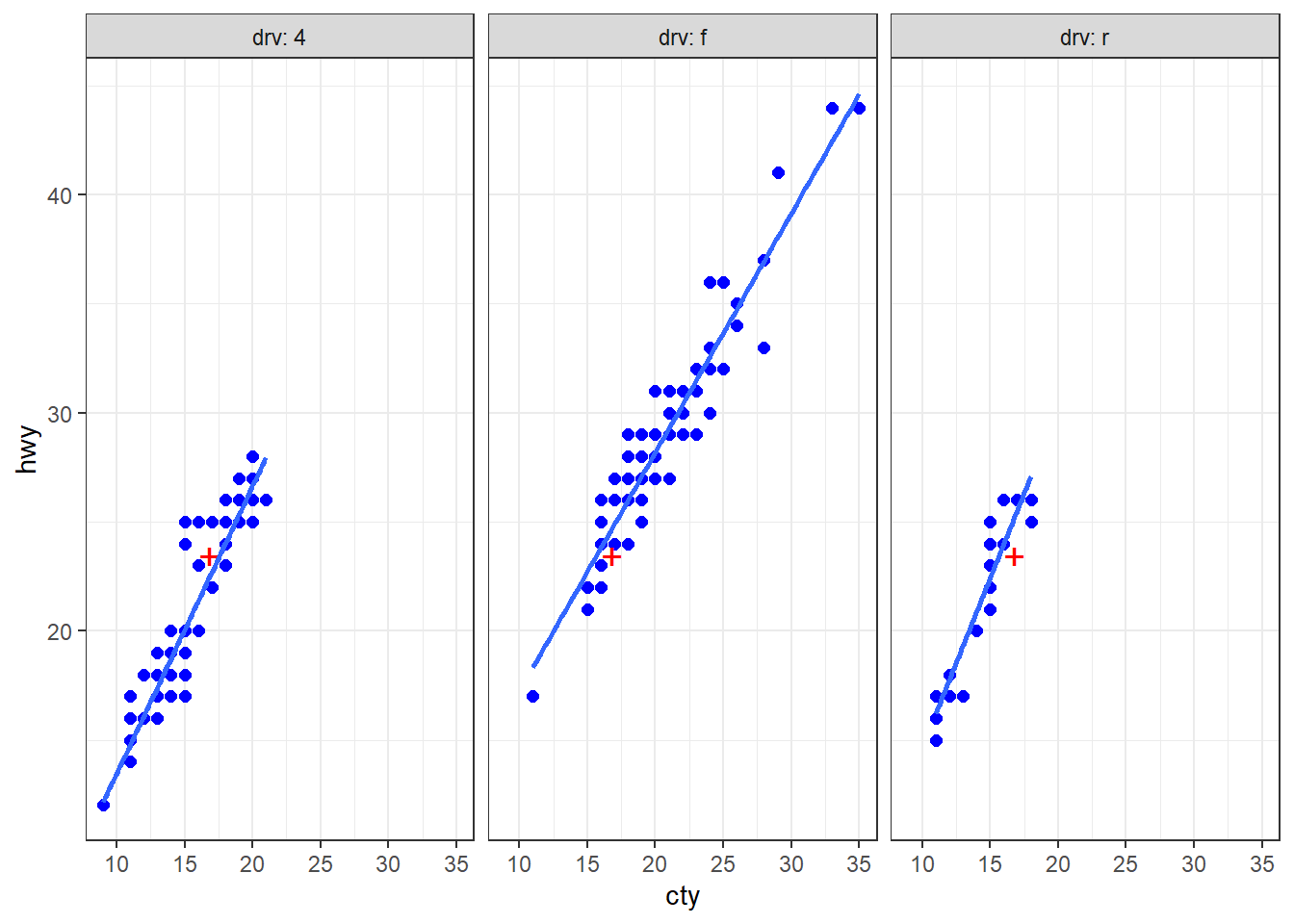
Pour en apprendre davantage sur ce sujet, vous pouvez consulter cette page et celle-ci.
Ressources
Si vous souhaitez en savoir plus sur ggplot, les sources suivantes peuvent vous être utiles.