# Les données
varX <- seq(-pi, pi, 0.1)
varY <- sin(varX)
dt <- data.frame(z = varX, w = varY)11 Les graphiques de base en R
R offre une grande flexibilité pour la création de graphiques, allant des plus simples aux plus élaborés. Plusieurs packages permettent de produire des visualisations adaptées à divers besoins analytiques ou de communication.
Parmi les principaux outils graphiques disponibles, on trouve :
graphics: ce package est chargé automatiquement avec R. Il constitue le système graphique de base et permet de réaliser des visualisations classiques telles que les histogrammes, les diagrammes en barres, les courbes ou les nuages de points. Il est au cœur de ce chapitre.ggplot2: ce package propose une approche plus moderne fondée sur la “Grammar of Graphics”. Il permet de produire des graphiques complexes et est largement utilisé pour des visualisations de qualité professionnelle. Il sera abordé en détail dans le chapitre suivant.
D’autres packages, notamment lattice, offrent également des fonctionnalités avancées, mais ne seront pas traités ici.
11.1 Types de fonctions graphiques
En R de base, les fonctions graphiques se répartissent en trois grandes catégories :
Fonctions de niveau supérieur : elles permettent de créer un nouveau graphique à partir de données. Ce sont les fonctions les plus couramment utilisées pour produire des visualisations de base. Exemples :
stripchart(),dotchart(),plot(),boxplot(),barplot(),hist(),curve().Fonctions de niveau inférieur : elles ajoutent des éléments à un graphique déjà existant, comme des points, des lignes, du texte ou une légende. Elles sont utiles pour enrichir ou annoter une figure. Exemples :
legend(),title(),points(),lines(),text().Fonctions de paramétrage graphique : elles permettent de définir ou modifier des paramètres globaux du système graphique, tels que la disposition des figures, les marges, les axes ou les polices. Exemples :
par(),layout(). Ce type de fonction ne sera pas abordé dans ce chapitre.
Voici une illustration combinant les deux premiers types de fonctions :
# Graphique principal (nuage de points)
plot(x = varX, y = varY)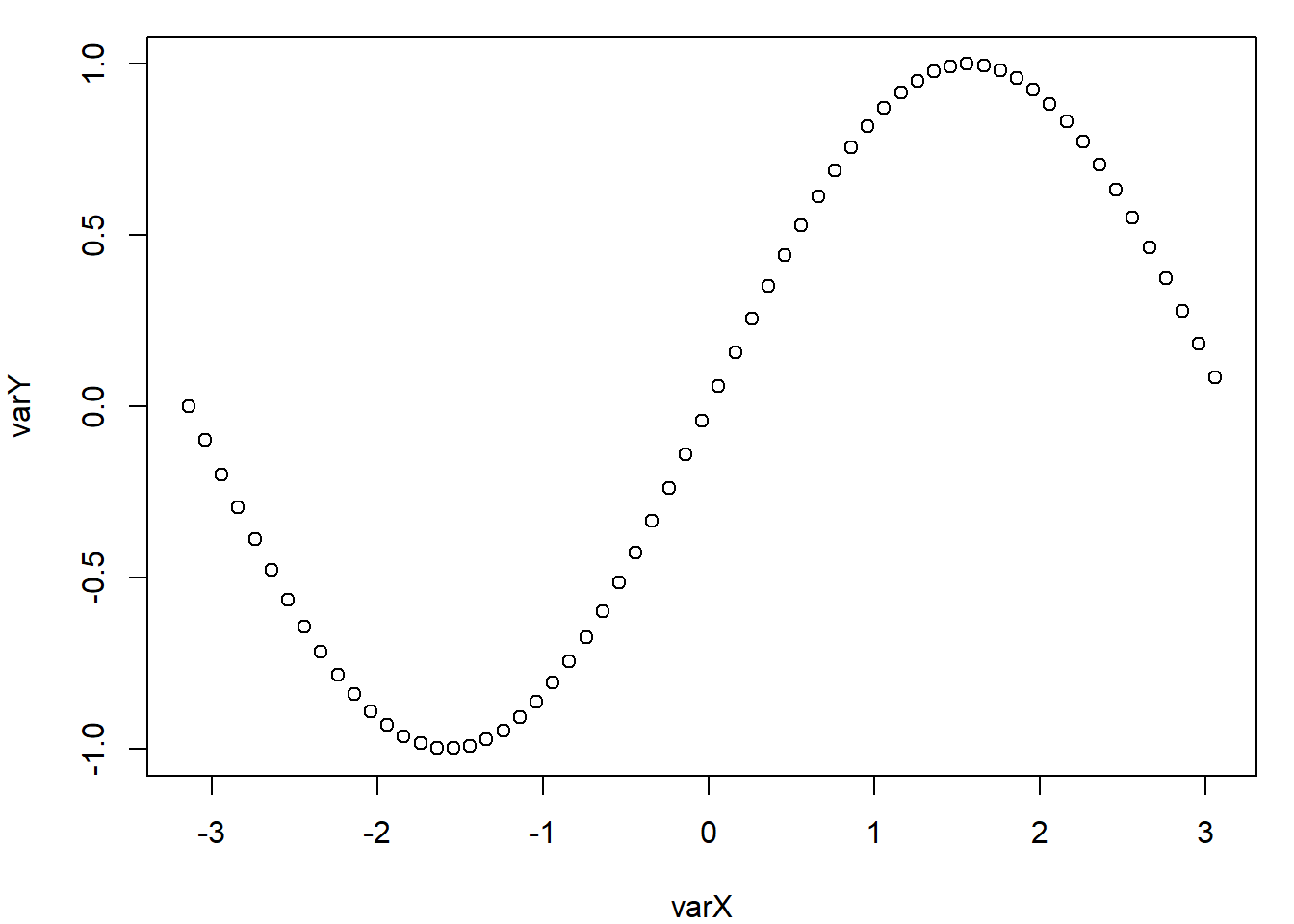
# Ajouter des étiquettes textuelles
text(x = c(-1, 1), y = c(-0.5, 0.5), labels = c("a", "b"), col = "blue")
# Ajouter deux points supplémentaires
points(x = c(-1.5, 1.5), y = c(-0.5, 0.5), pch = "+")
# Ajouter une ligne reliant des points spécifiques
lines(x = 0:3, y = c(0, -0.3, 0.7, 1))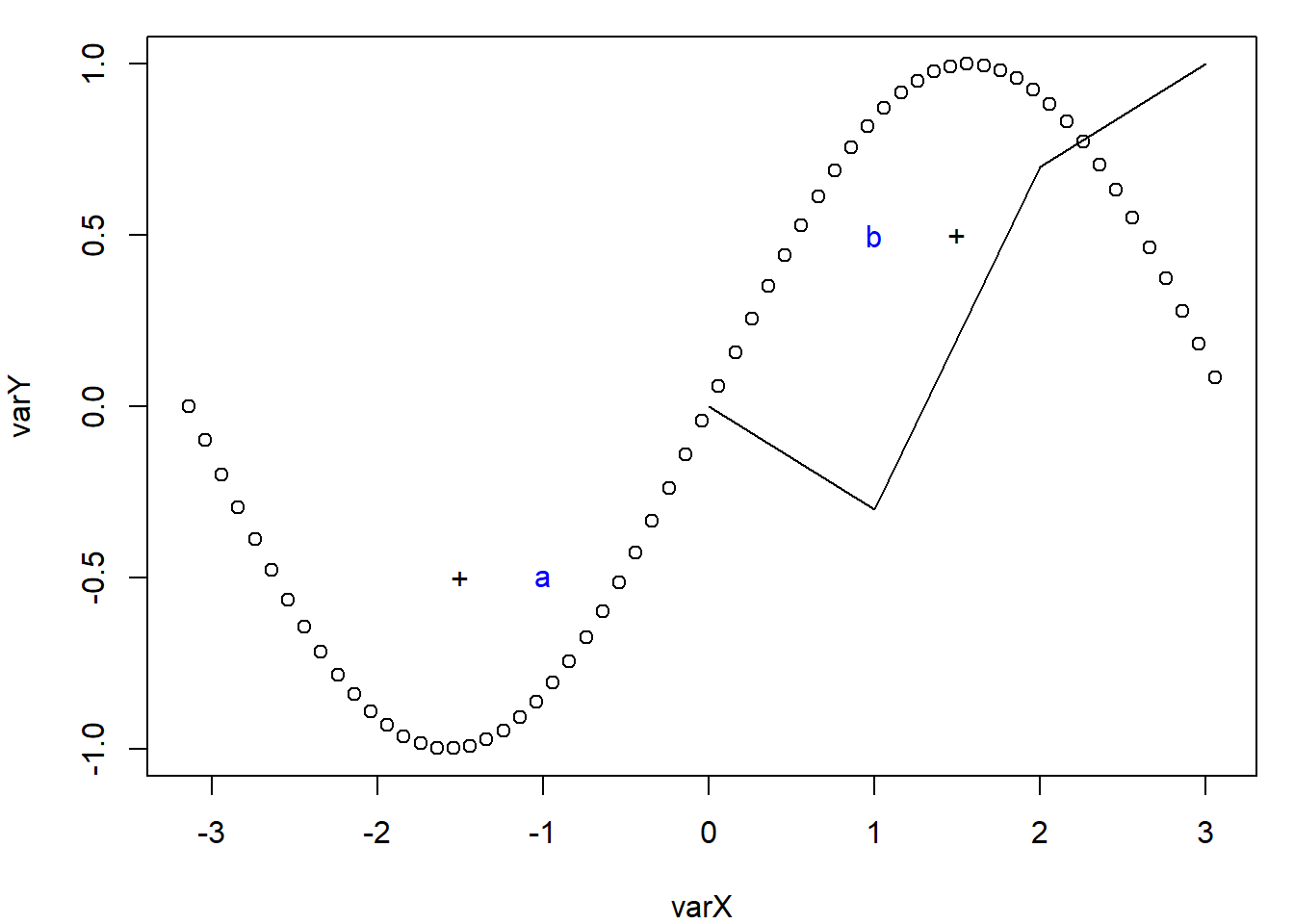
Cette illustration combine les deux premiers types de fonctions graphiques en R : la création d’un graphique principal avec plot(), et l’ajout d’éléments graphiques supplémentaires à l’aide de fonctions comme points(), lines() et text().
Nous ne pouvons pas détailler ici chacune de ces fonctions. Pour en apprendre davantage, il est recommandé de consulter l’aide spécifique à chaque fonction (?<nom_de_la_fonction>). La section suivante est toutefois consacrée à la fonction plot(), qui est de loin la plus importante du système graphique de base.
11.2 La fonction plot()
La fonction plot() est l’une des plus couramment utilisées pour produire des graphiques dans R. Il s’agit d’une fonction générique, ce qui signifie qu’elle accepte différents types d’arguments et adapte automatiquement son comportement à la nature des données fournies. Elle permet de créer une grande variété de visualisations, allant du nuage de points aux courbes, en passant par les graphiques en lignes, en barres ou en boîtes. Grâce à sa flexibilité, plot() constitue un outil fondamental pour l’exploration visuelle des données.
Syntaxe
Il existe deux façons d’utiliser plot() :
Syntaxe classique :
plot(x = varX, y = varY)Syntaxe à base de formule :
plot(varY ~ varX)Lorsque cette syntaxe est utilisée, c’est en réalité la fonction/méthode
plot.formula()qui est appelée en arrière-plan (voirmethods(plot)).
La syntaxe formule permet d’utiliser l’argument data, ce qui simplifie l’écriture lorsque les variables sont contenues dans une dataframe. Ainsi, les deux lignes suivantes sont équivalentes :
plot(dt$w ~ dt$z)
plot(w ~ z, data = dt)Sauvegarder un graphique
Un graphique créé dans RStudio est affiché par défaut dans l’onglet Plots. Vous pouvez utiliser cet onglet pour zoomer sur le graphique en cliquant sur le bouton Zoom, ou pour l’enregistrer en cliquant sur le bouton Export.

Vous pouvez également sauvegarder la fenetre graphique courante directement depuis la console R en utilisant la fonction dev.print(). Le fichier sera enregistré dans votre répertoire de travail (voir getwd() pour le localiser). Exemple :
# Enregistre le graphique courant dans un fichier PDF :
# Remplacez "nom_du_fichier" par le nom souhaité, en veillant à conserver l’extension .pdf.
dev.print(pdf, "nom_du_fichier.pdf")Personnalisation du graphique
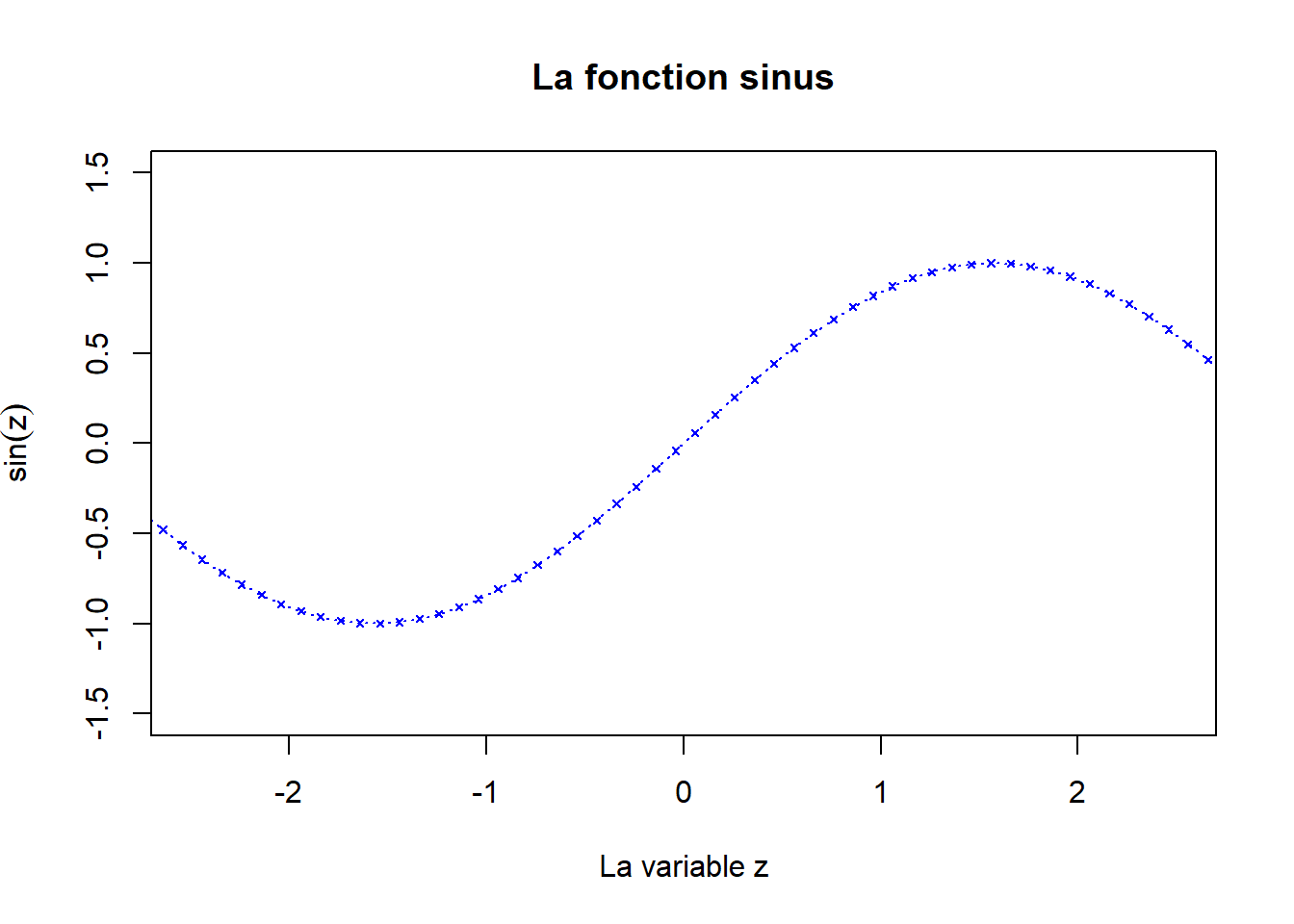
La fonction plot() accepte de nombreux arguments pour personnaliser l’apparence d’un graphique. Ces options permettent de contrôler le type de tracé, les couleurs, les symboles, les axes, les titres, et bien plus encore. Voici un exemple illustrant les options les plus importantes. Pour une liste complète, consultez l’aide de la fonction avec ?plot.
plot(w ~ z, data = dt,
type = "o", # type de tracé : points ("p"), lignes ("l"), ...
col = "blue", # couleur
pch = 4, # plotting character = Forme des points (voir ?points)
cex = 0.5, # character expansion = taille relative des symboles (défaut = 1)
lty = 3, # line type = type de ligne (voir ?par)
lwd = 1.2, # line width = épaisseur des lignes (défaut = 1)
xlim = c(-2.5, 2.5), # limites de l’axe des x
ylim = c(-1.5, 1.5), # limites de l’axe des y
xlab = "La variable z", # titre de l’axe des x
ylab = expression(sin(z)), # affiche "sin(z)" comme une expression mathématique; voir ?plotmath
main = "La fonction sinus" # titre principal du graphique
)
Les options graphiques — telles que col, pch, cex, lty et lwd — s’appliquent aussi bien à la fonction plot() qu’à d’autres fonctions comme points(), lines() et text(). Cette cohérence permet de manipuler plus facilement ces paramètres.
Voici des graphiques illustrant les principaux paramètres graphiques de R : type, pch, lty et col. Le type de ligne (lty) peut être spécifié par un entier (de 1 à 6) ou par une chaîne de caractères décrivant le motif (par exemple "solid", "dashed"). De même pour pch, qui peut être défini soit par un entier (de 0 à 25), correspondant à différents symboles prédéfinis, soit par un caractère unique (par exemple "+", "*", "o"), qui sera alors utilisé comme symbole de point. Pour les couleurs, sachez que R reconnaît plus de 650 noms de couleurs prédéfinis; vous pouvez afficher la liste complète en tapant colors().
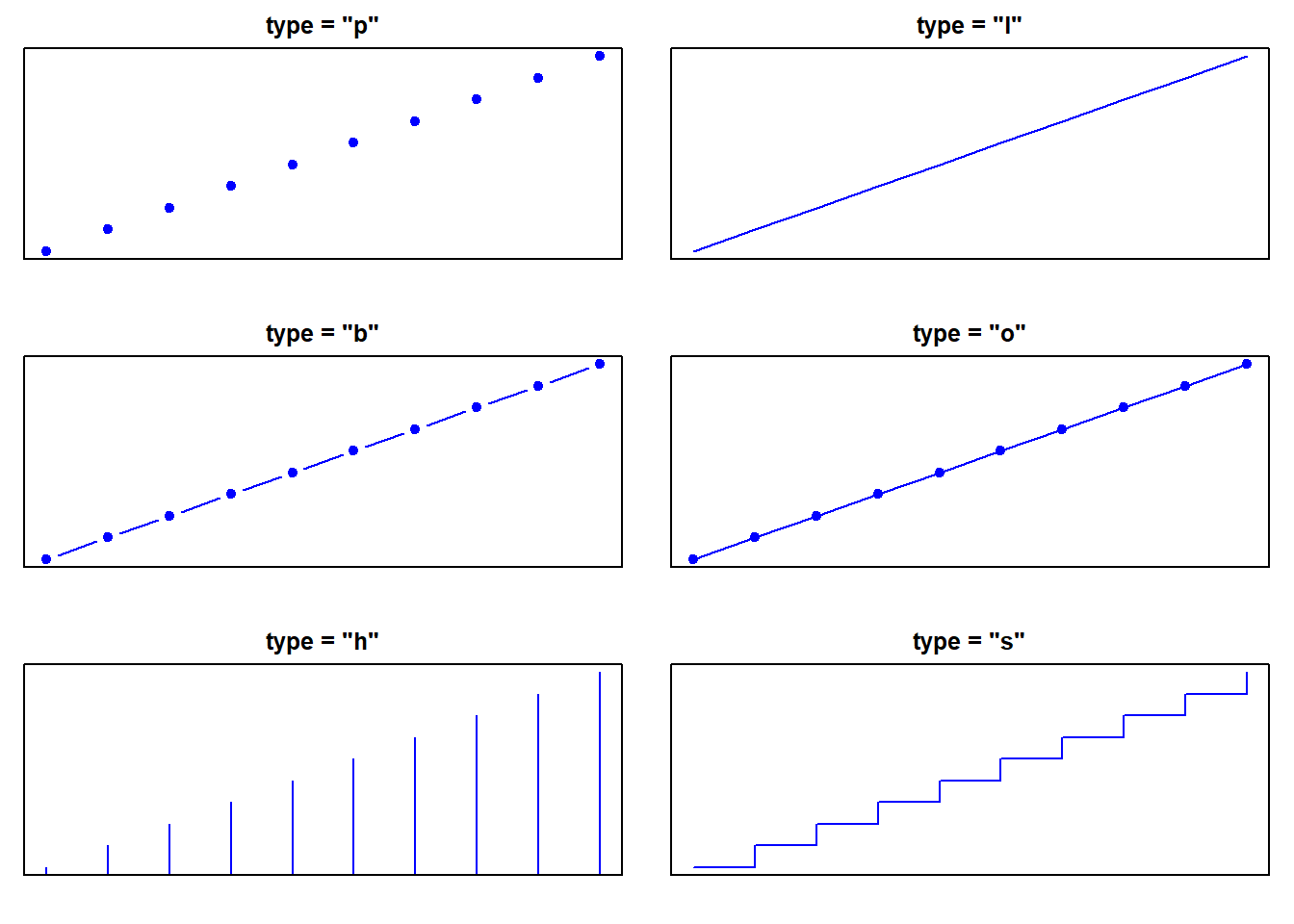
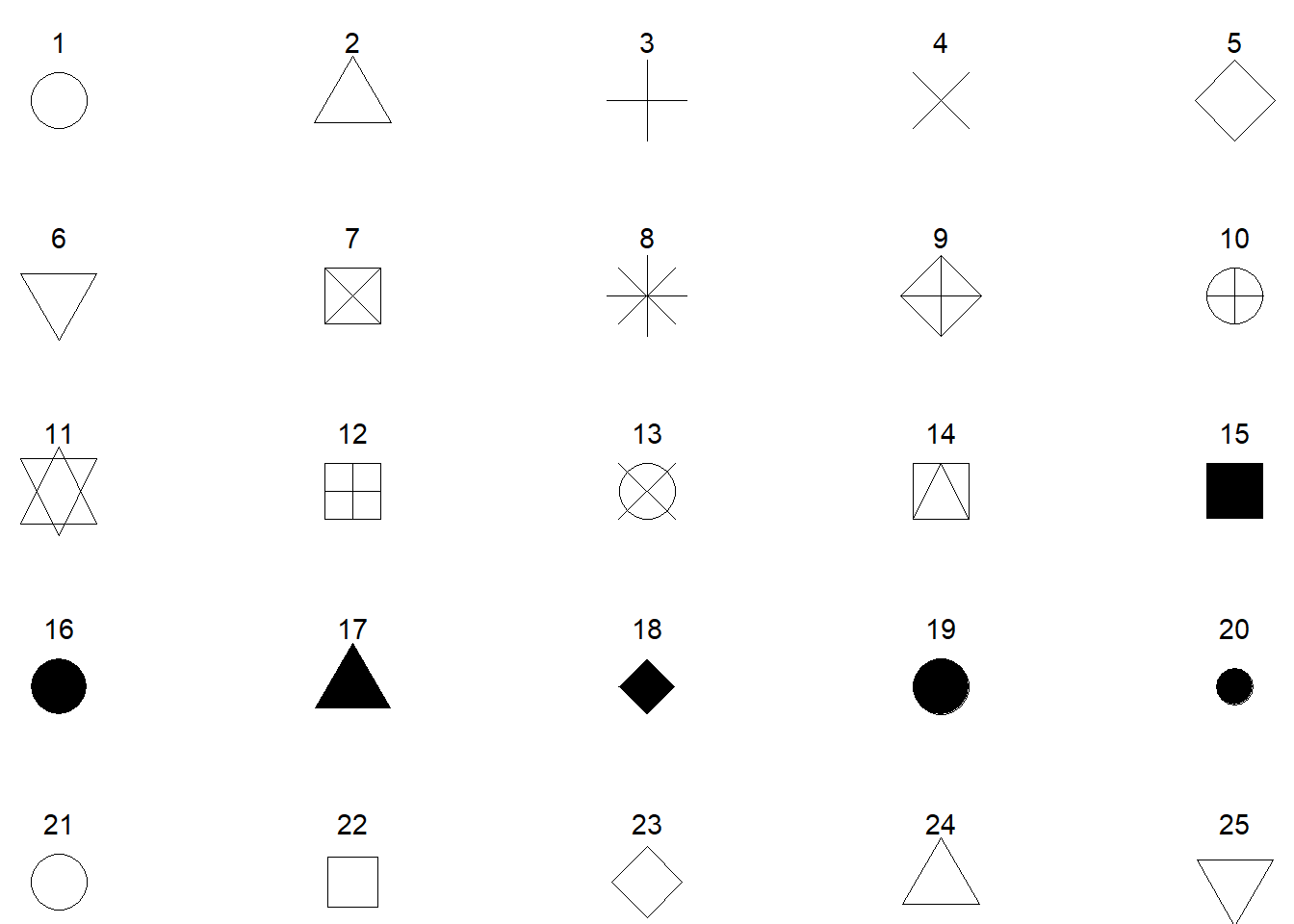
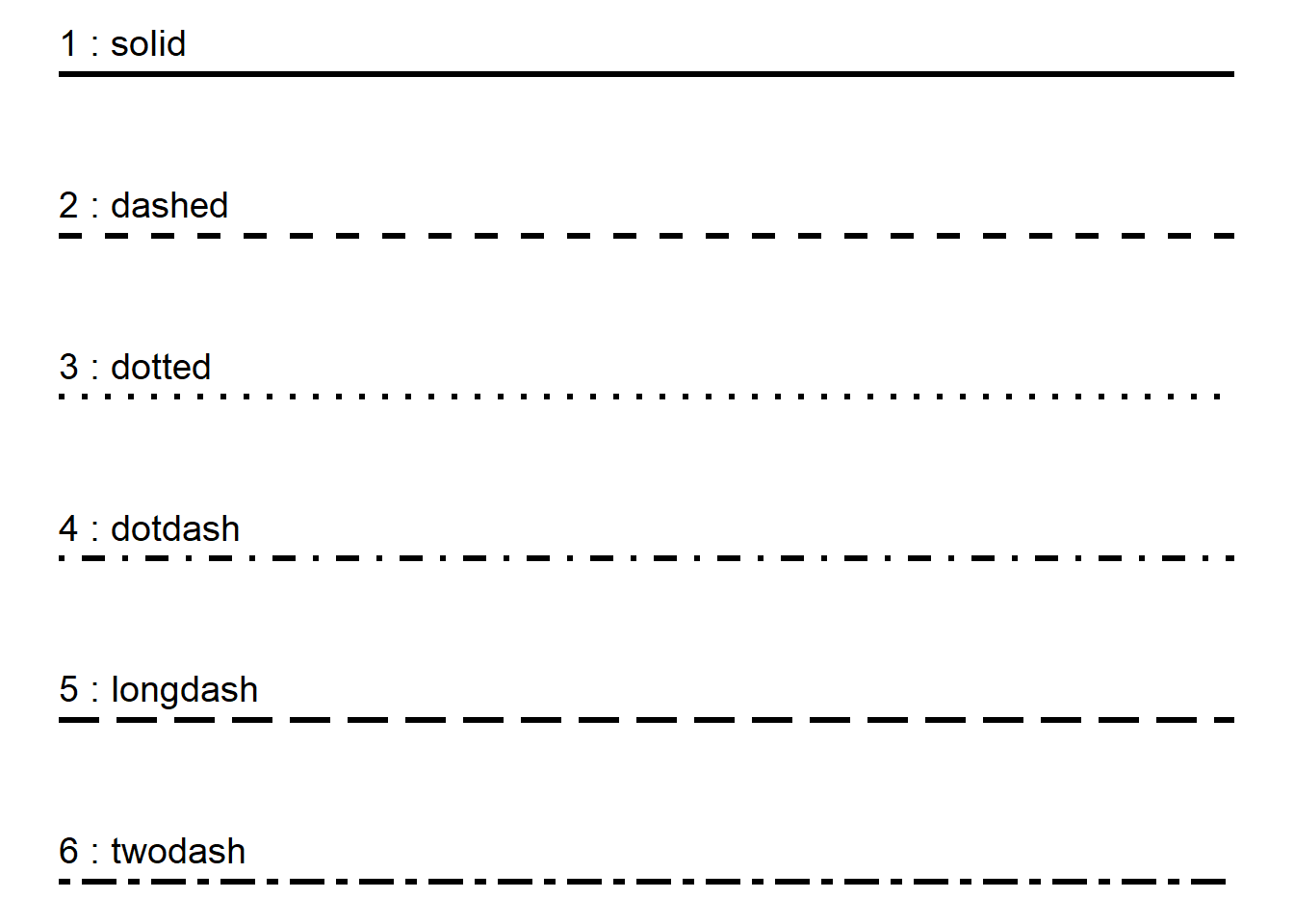
Dans la suite, nous allons passer en revue les principaux types de graphiques que l’on peut réaliser avec R, en utilisant plot() ainsi que d’autres fonctions graphiques spécifiques. Le choix de la représentation dépend étroitement de la nature des données à visualiser : qu’elles soient quantitatives, catégorielles, temporelles ou spatiales, R offre une grande variété d’outils.
Pour les exemples qui suivent, nous utiliserons le jeu de données mpg disponible dans le package ggplot2. Ce dernier est supposé être installé sur votre machine, mais il n’est pas nécessaire de le charger.
data(mpg, package = "ggplot2")
mpg
str(mpg)# A tibble: 234 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto… f 18 29 p comp…
2 audi a4 1.8 1999 4 manu… f 21 29 p comp…
3 audi a4 2 2008 4 manu… f 20 31 p comp…
4 audi a4 2 2008 4 auto… f 21 30 p comp…
5 audi a4 2.8 1999 6 auto… f 16 26 p comp…
6 audi a4 2.8 1999 6 manu… f 18 26 p comp…
7 audi a4 3.1 2008 6 auto… f 18 27 p comp…
8 audi a4 quattro 1.8 1999 4 manu… 4 18 26 p comp…
9 audi a4 quattro 1.8 1999 4 auto… 4 16 25 p comp…
10 audi a4 quattro 2 2008 4 manu… 4 20 28 p comp…
# ℹ 224 more rows
tibble [234 × 11] (S3: tbl_df/tbl/data.frame)
$ manufacturer: chr [1:234] "audi" "audi" "audi" "audi" ...
$ model : chr [1:234] "a4" "a4" "a4" "a4" ...
$ displ : num [1:234] 1.8 1.8 2 2 2.8 2.8 3.1 1.8 1.8 2 ...
$ year : int [1:234] 1999 1999 2008 2008 1999 1999 2008 1999 1999 2008 ...
$ cyl : int [1:234] 4 4 4 4 6 6 6 4 4 4 ...
$ trans : chr [1:234] "auto(l5)" "manual(m5)" "manual(m6)" "auto(av)" ...
$ drv : chr [1:234] "f" "f" "f" "f" ...
$ cty : int [1:234] 18 21 20 21 16 18 18 18 16 20 ...
$ hwy : int [1:234] 29 29 31 30 26 26 27 26 25 28 ...
$ fl : chr [1:234] "p" "p" "p" "p" ...
$ class : chr [1:234] "compact" "compact" "compact" "compact" ...mpg contient des informations sur différents modèles de voitures, notamment leur consommation, leur type de transmission, leur cylindrée, et bien plus encore. Pour plus d’informations sur la structure et les variables de ce jeu de données, vous pouvez consulter la documentation avec ?mpg.
Nous allons transformer plusieurs variables (cyl, trans, drv, fl, class) en facteurs, afin de faciliter leur utilisation dans les graphiques. De plus, nous regroupons les différents types de transmission (trans) en deux catégories : “auto” (automatique) et “manual” (manuelle), en renommant les niveaux existants.
mpg <- transform(mpg, cyl = factor(cyl), trans = factor(trans), drv = factor(drv),
fl = factor(fl), class = factor(class))
levels(mpg$trans) <- c(rep("auto", 8), rep("manual", 2))
summary(mpg) manufacturer model displ year cyl
Length:234 Length:234 Min. :1.600 Min. :1999 4:81
Class :character Class :character 1st Qu.:2.400 1st Qu.:1999 5: 4
Mode :character Mode :character Median :3.300 Median :2004 6:79
Mean :3.472 Mean :2004 8:70
3rd Qu.:4.600 3rd Qu.:2008
Max. :7.000 Max. :2008
trans drv cty hwy fl class
auto :157 4:103 Min. : 9.00 Min. :12.00 c: 1 2seater : 5
manual: 77 f:106 1st Qu.:14.00 1st Qu.:18.00 d: 5 compact :47
r: 25 Median :17.00 Median :24.00 e: 8 midsize :41
Mean :16.86 Mean :23.44 p: 52 minivan :11
3rd Qu.:19.00 3rd Qu.:27.00 r:168 pickup :33
Max. :35.00 Max. :44.00 subcompact:35
suv :62 11.3 Variable numérique
Une seule numérique
# 1. Guche supérieur : tracé simple
stripchart(mpg$displ, xlab = "displ", pch = 16)
# 2. Droite supérieur : method = "stack" -> empile les points lorsque plusieurs valeurs sont identiques
stripchart(mpg$displ, xlab = "displ", pch = 16, method = "stack")
# 3. Gauche inférieur : method = "jitter" -> ajoute un bruit aléatoire pour éviter la superposition
stripchart(mpg$displ, xlab = "displ", pch = 16, method = "jitter")
# 4. Droite inférieur : dispersion aléatoire verticale
stripchart(mpg$displ, ylab = "displ", pch = 16, method = "jitter", vertical = TRUE)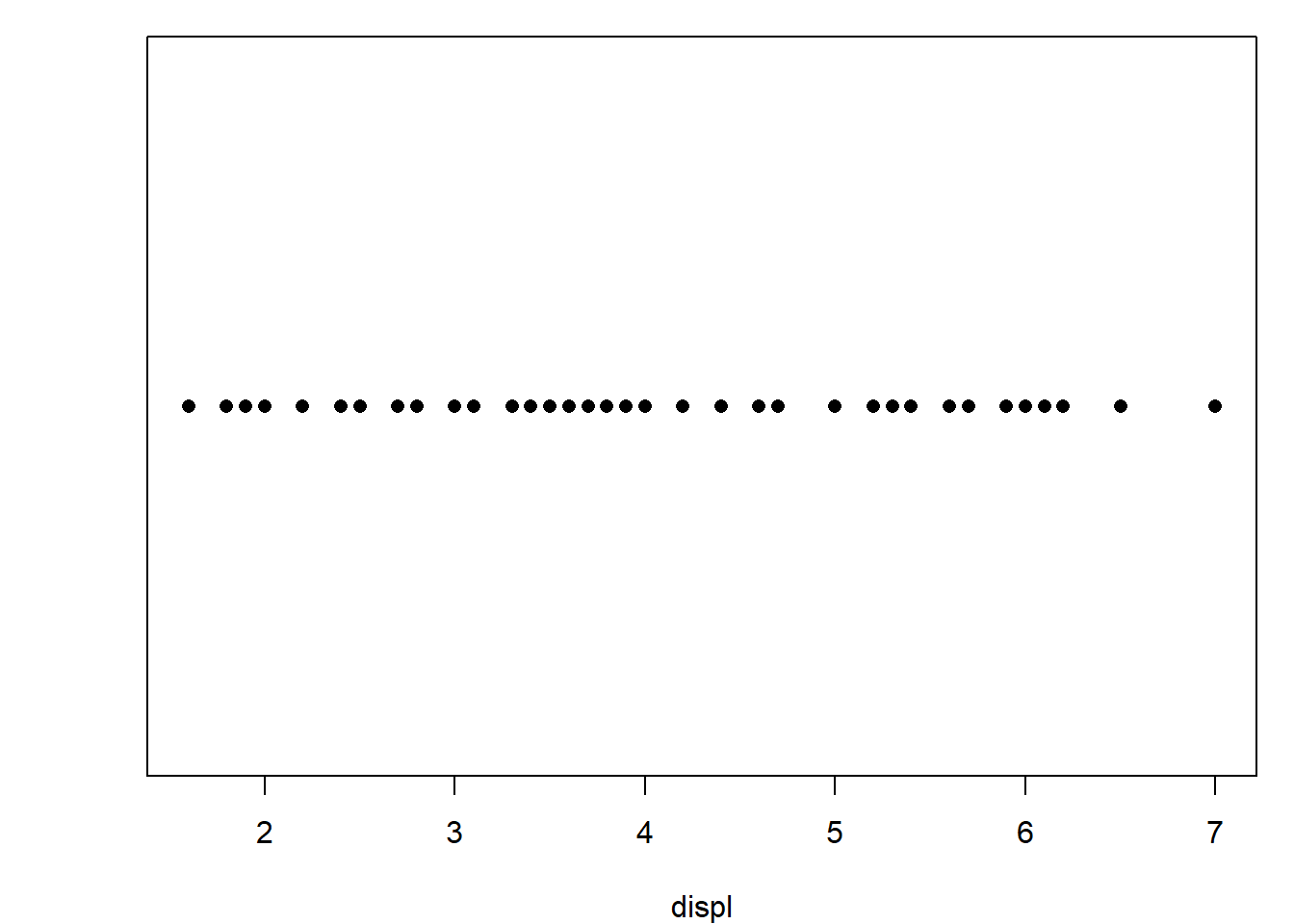
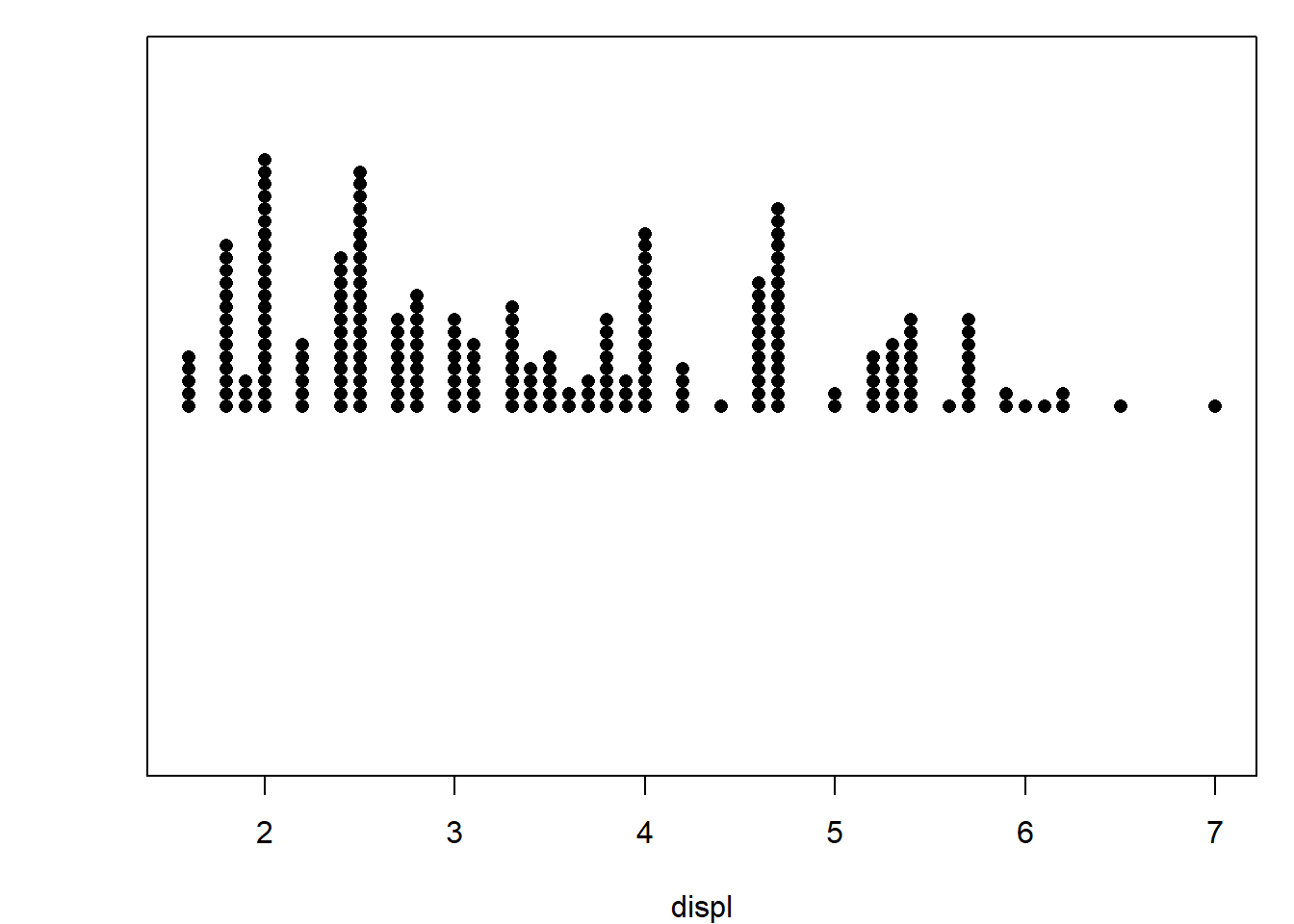
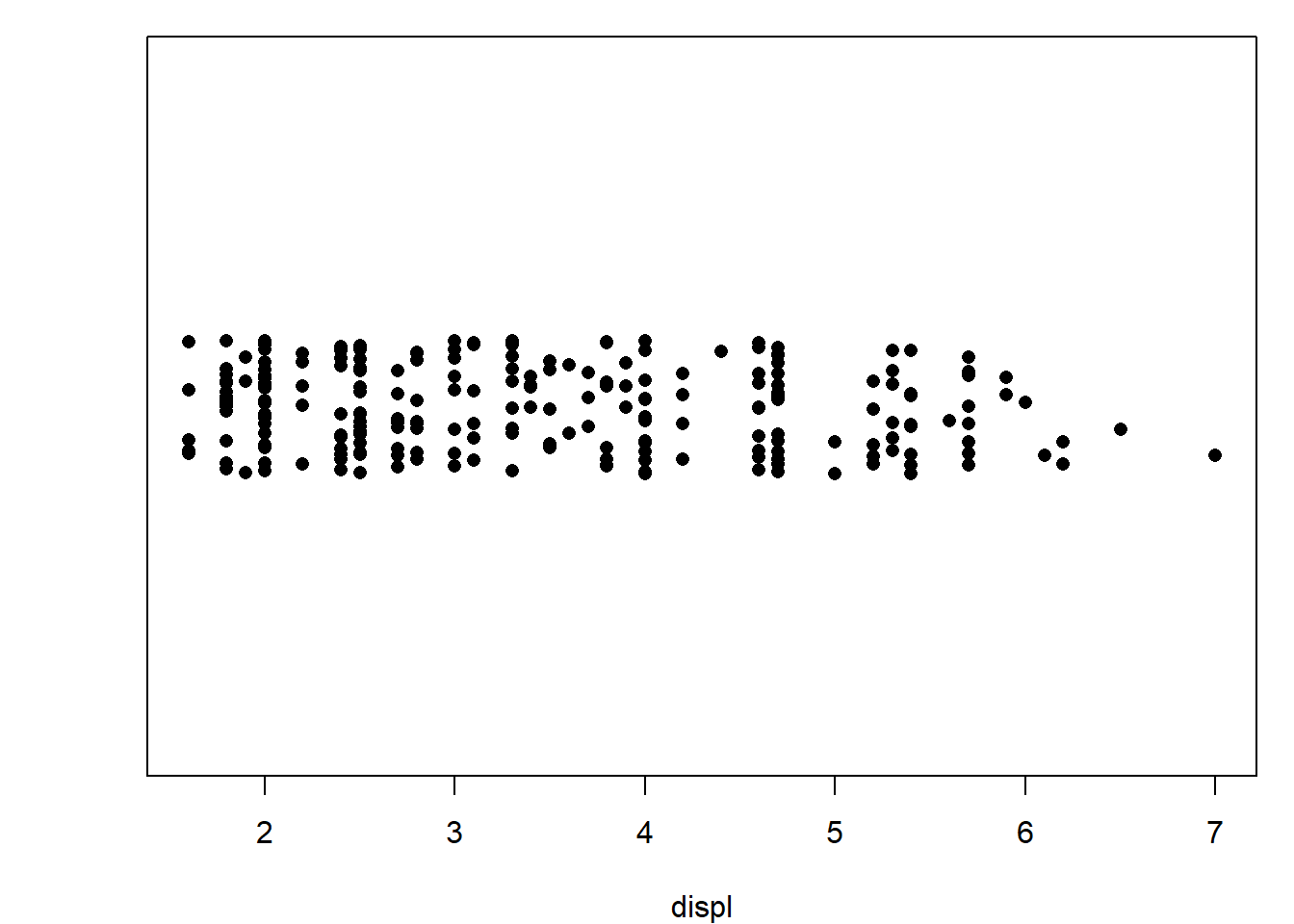
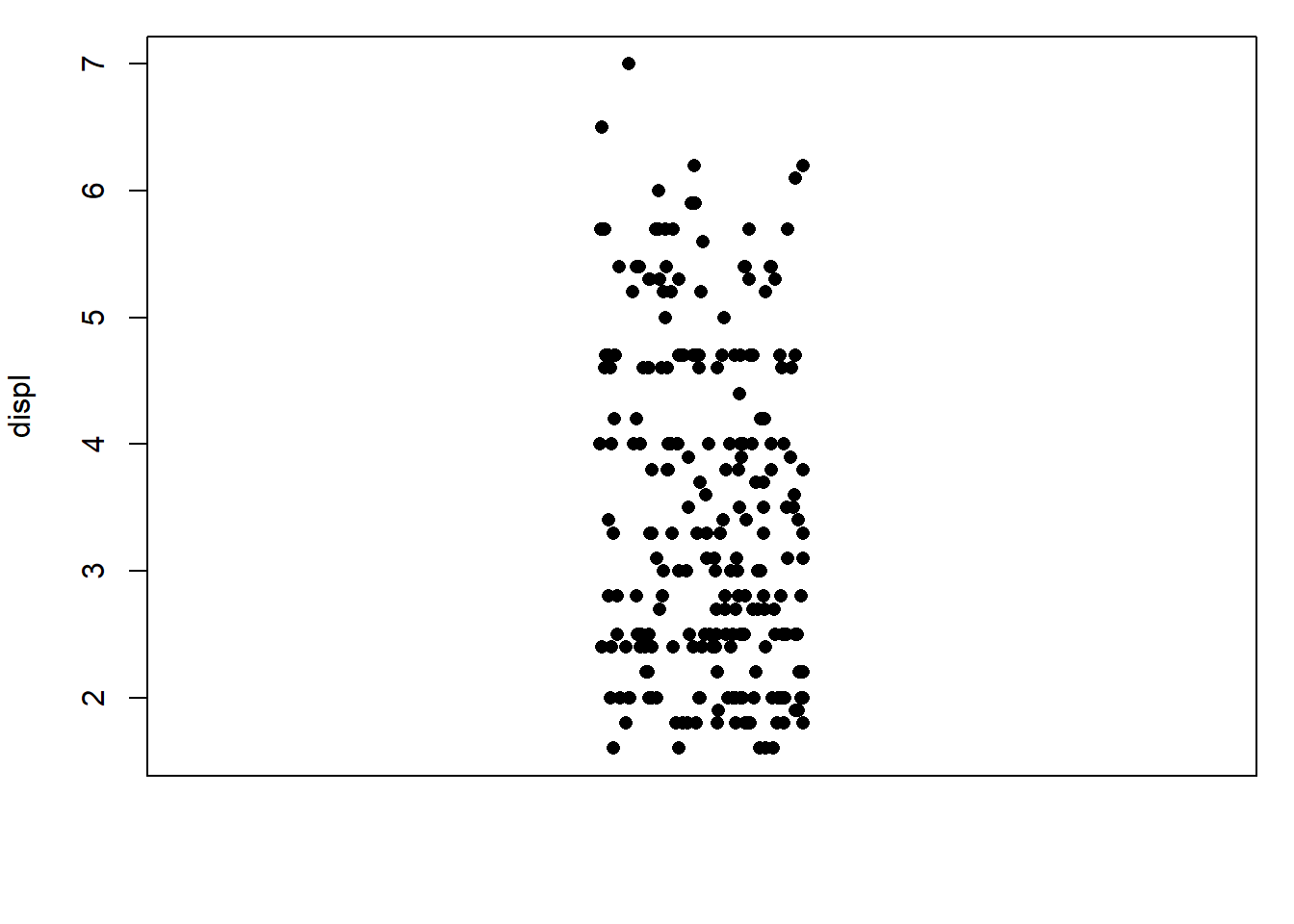
Les options method = "stack" et method = "jitter" dans stripchart() permettent d’améliorer la lisibilité des points lorsque plusieurs observations ont des valeurs proches ou identiques. L’option "stack" empile les points pour représenter leur fréquence. L’option "jitter" ajoute un léger bruit aléatoire pour éviter la superposition. Ces méthodes facilitent la lecture visuelle sans altérer l’information.
Numeric vs Facteur(s)
# 1. Stripchart vertical de hwy (consommation) par trans (transmission)
stripchart(hwy ~ trans, data = mpg, vertical = TRUE, pch = 16, method = "jitter")
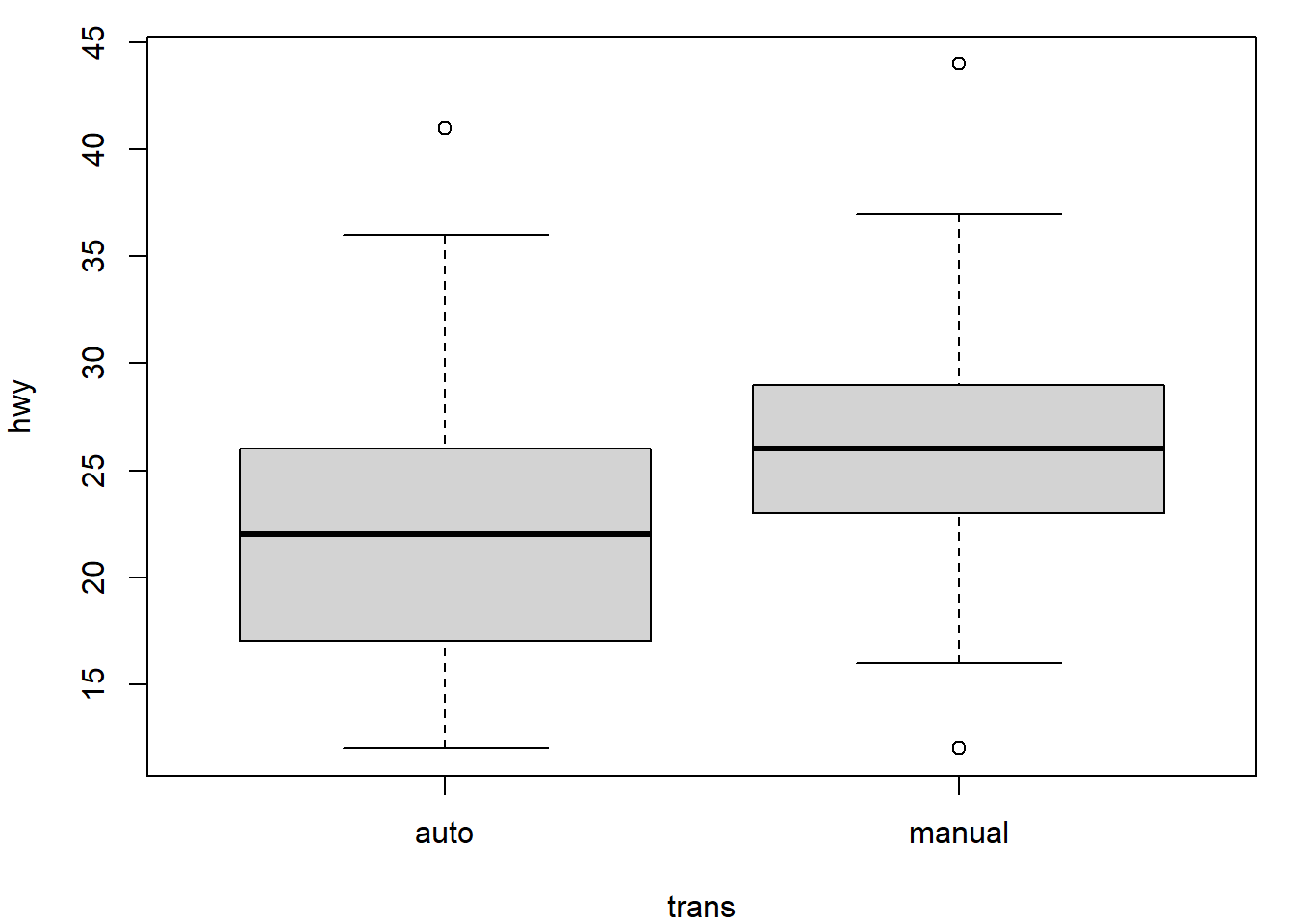
# 2. Boxplot de hwy par trans
boxplot(hwy ~ trans, data = mpg)
# 1. Boxplot + stripchart superposé (add = TRUE --> ajouter le stripchart par-dessus)
boxplot(hwy ~ trans, data = mpg)
stripchart(hwy ~ trans, data = mpg, vertical = TRUE, pch = 16, method = "jitter", add = TRUE)
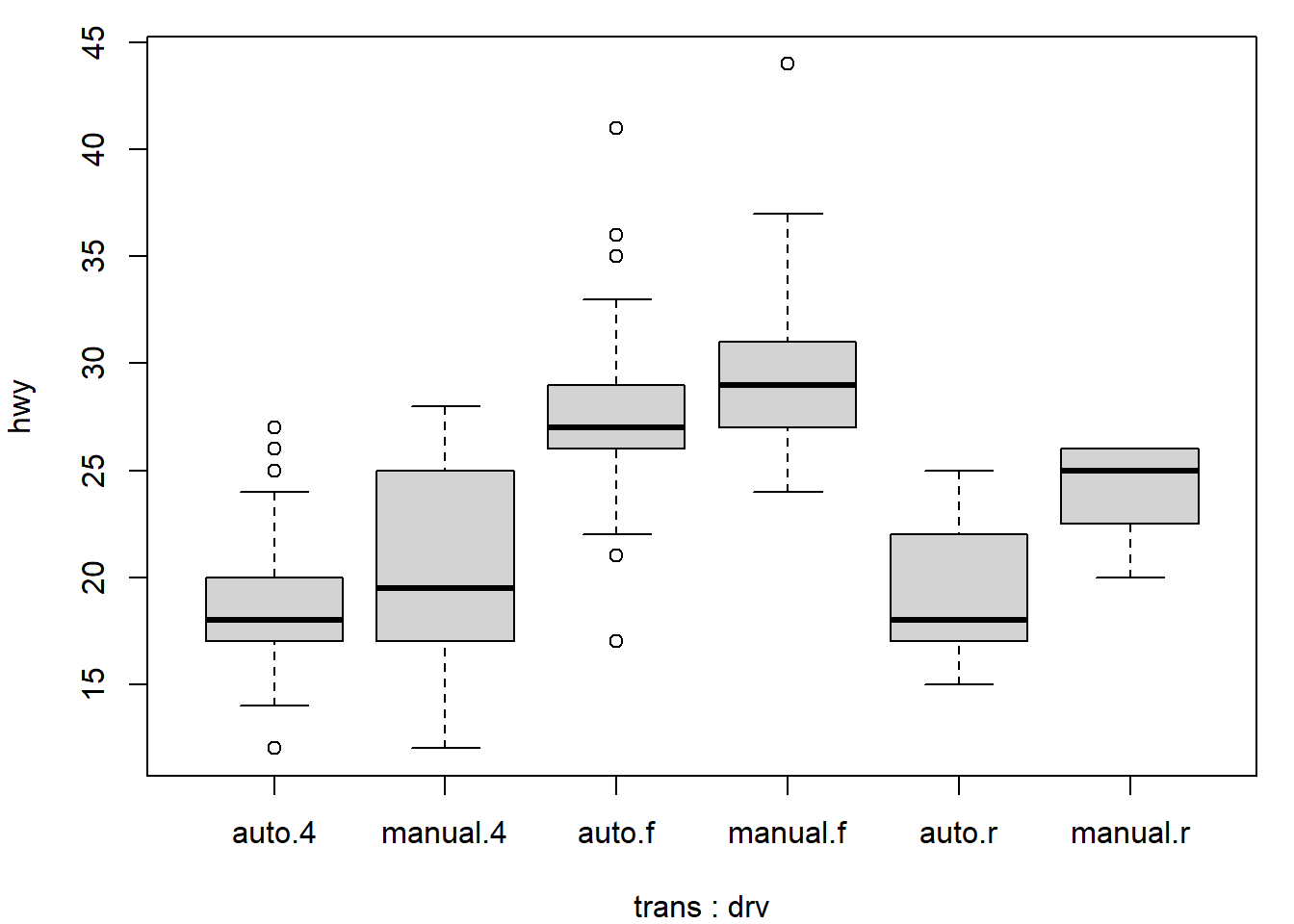
# 2. Boxplot de hwy par trans et drv (type de transmission du véhicule)
boxplot(hwy ~ trans + drv, data = mpg)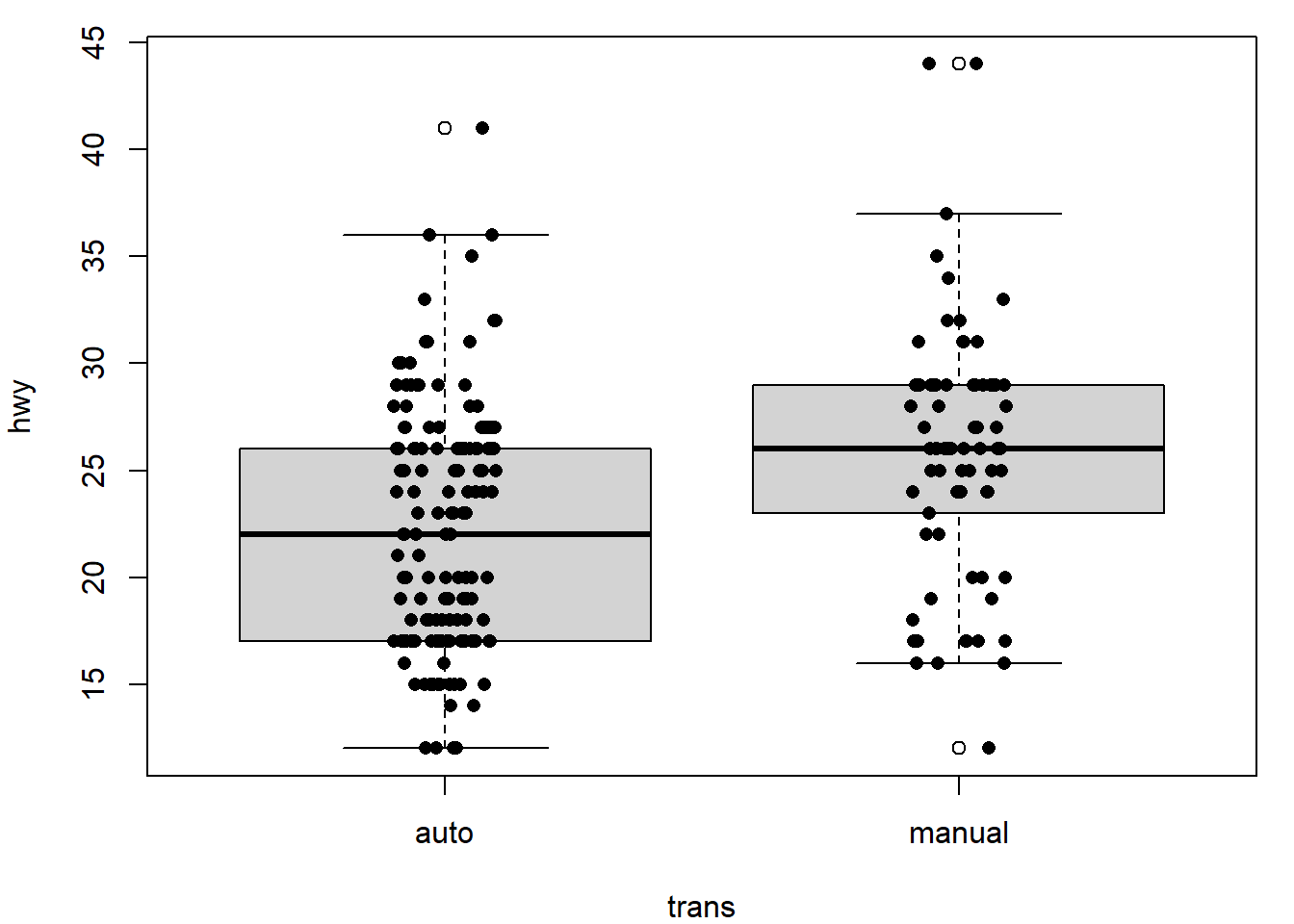
Numeric vs Numeric
# Nuage de points : hwy en fonction de displ (cylindrée)
plot(hwy ~ displ, data = mpg, pch = 16)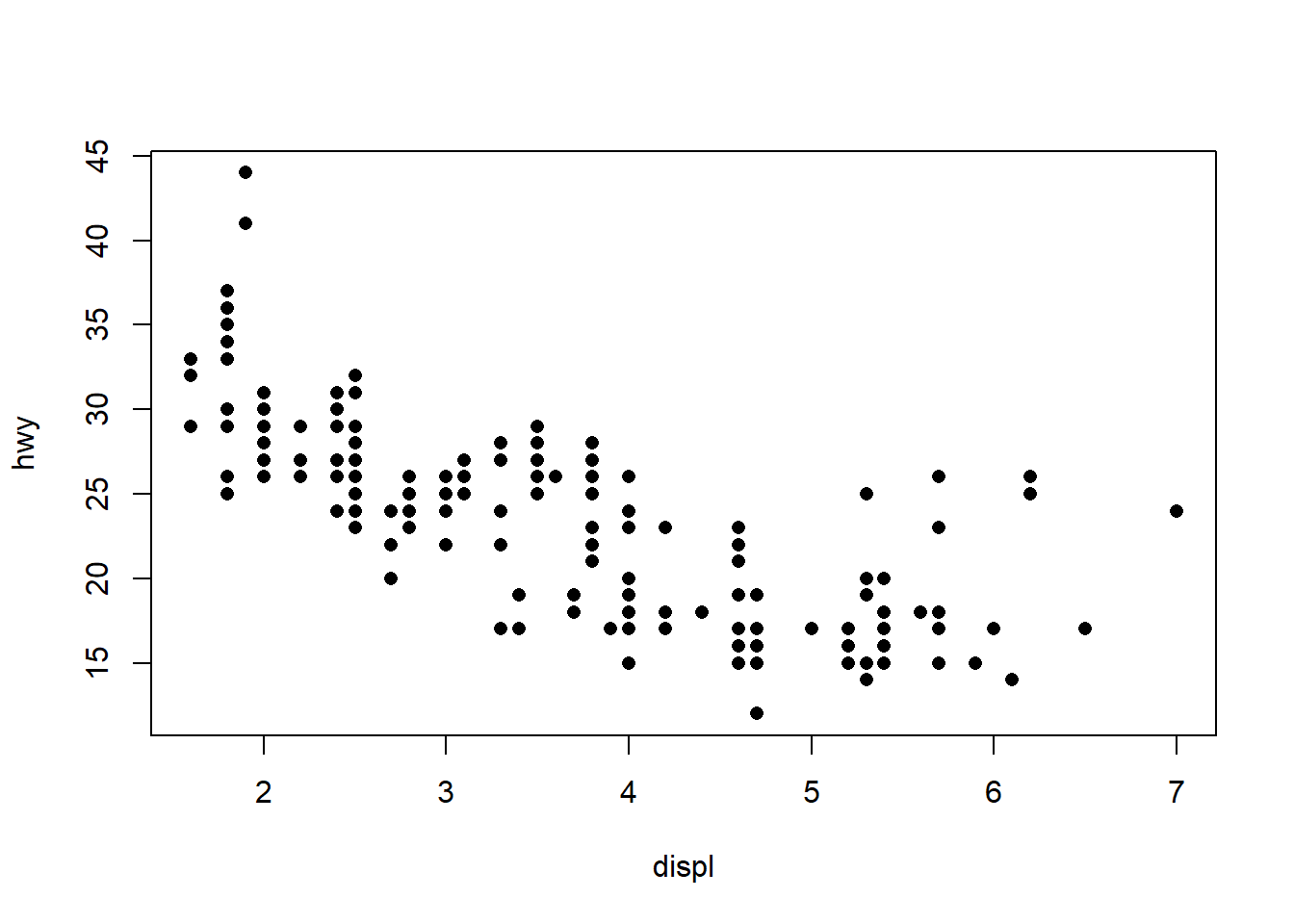
Numeric vs Numeric et Factor
# Nuage de points avec une couleur différente par niveau de trans (col = trans)
plot(hwy ~ displ, col = trans, data = mpg, pch = 16)
# Ajouter la légende avec les couleurs associées aux niveaux du facteur
legend("topright",
title = "Transmission",
legend = levels(mpg$trans),
col = 1:length(levels(mpg$trans)),
pch = 16,
ncol = 2,
bty = "n") # pas de boîte autour de la légende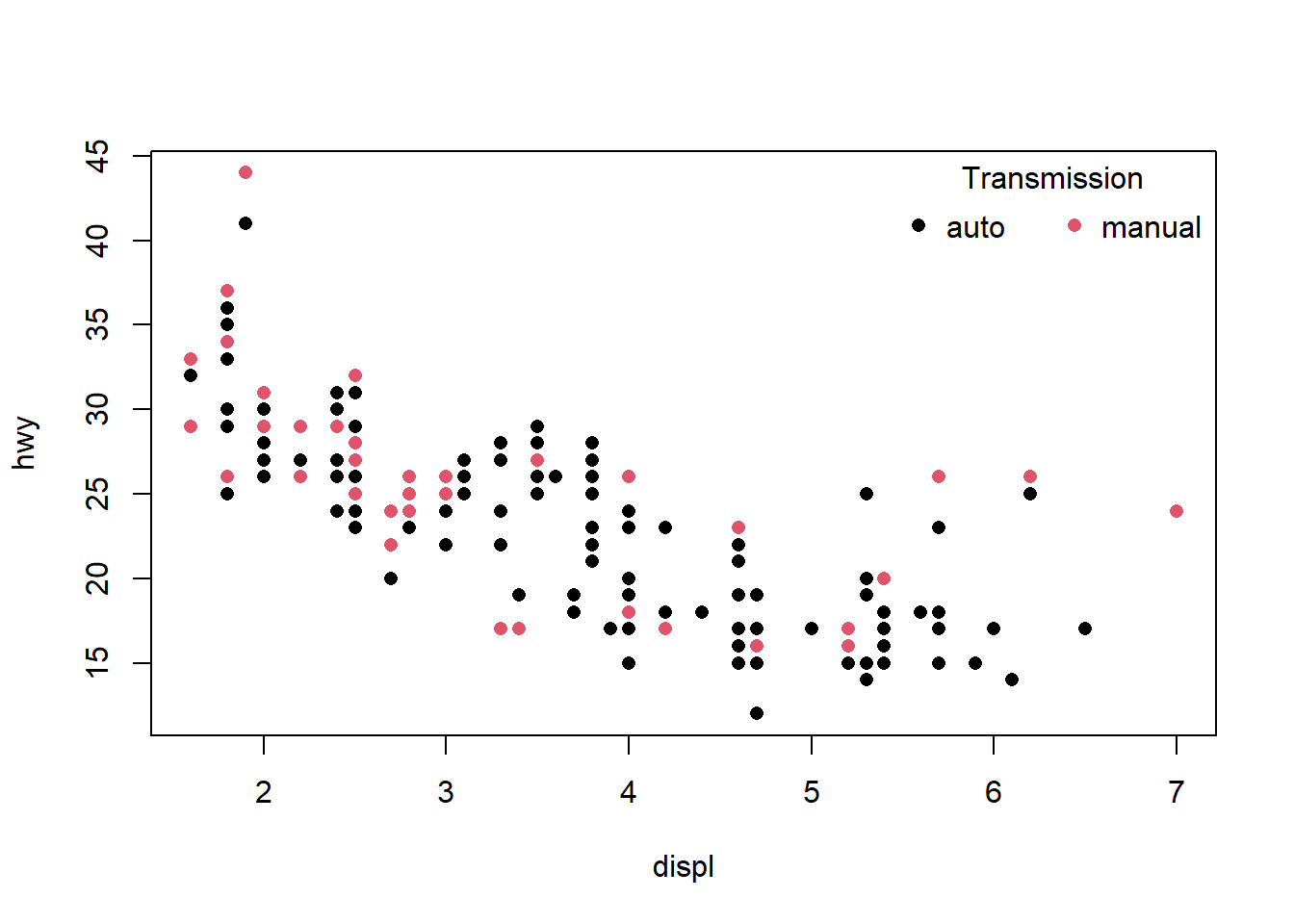
11.4 Variable factorielle
Un seul facteur
Graphique des fréquences avec plot()
La commande suivante trace un diagramme en barres des effectifs (ou fréquences absolues) de la variable drv. Étant donné que drv est une variable factorielle, plot() s’adapte automatiquement : elle calcule les fréquences de chaque niveau, les place sur l’axe vertical (y), et utilise les niveaux du facteur comme catégories sur l’axe horizontal (x).
plot(mpg$drv, xlab = "drv", ylab = "Fréquence")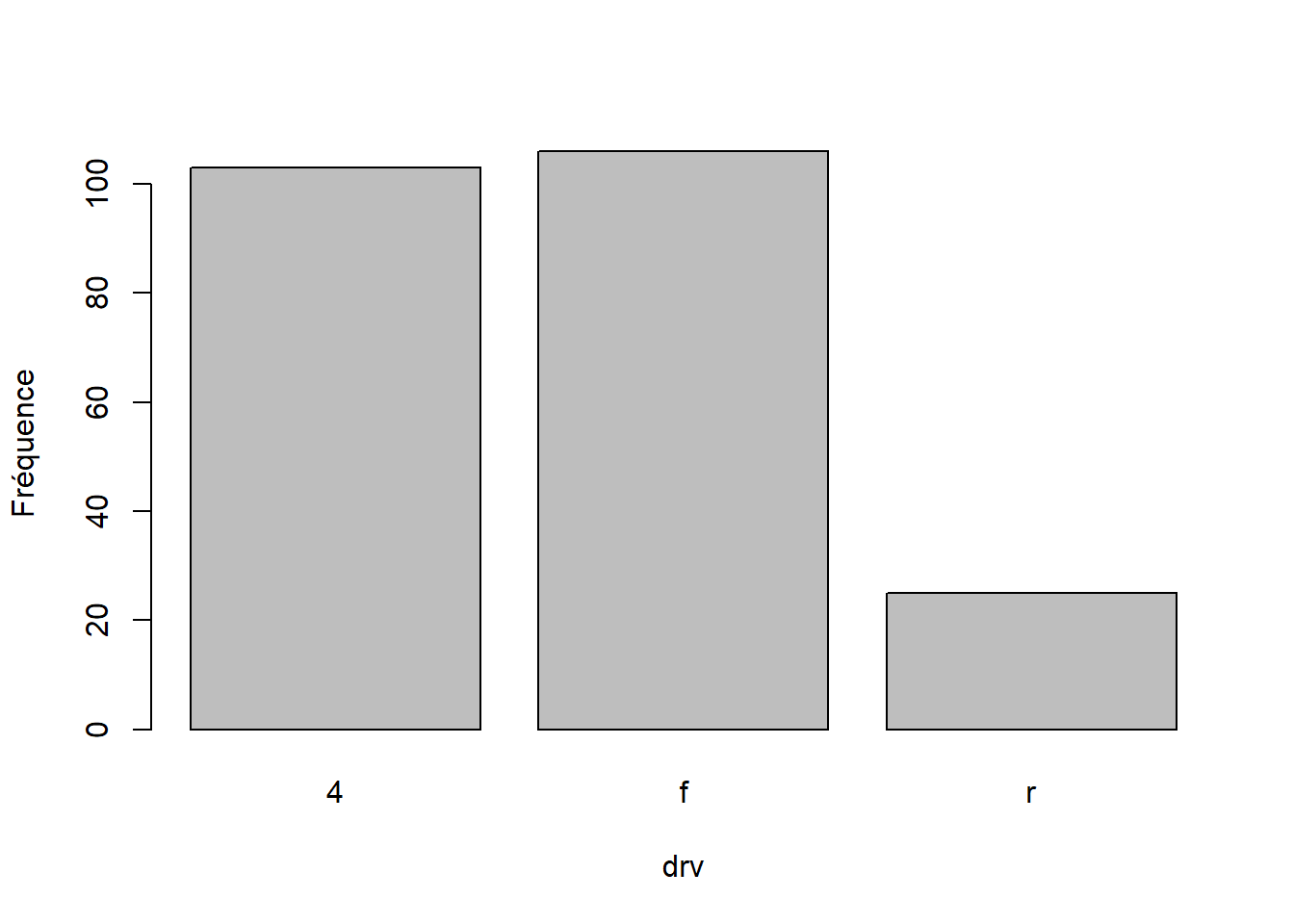
Le même graphique peut être obtenu à l’aide de :
table(mpg$drv) |> barplot(xlab = "drv", ylab = "Fréquence")
# ou
xtabs(~drv, data = mpg) |> barplot(xlab = "drv", ylab = "Fréquence")Pour rappelle, table(mpg$drv) crée une table de contingence. xtabs(~drv, data = mpg) est une alternative équivalente, souvent privilégiée dans des cas plus complexes, notamment lorsqu’on souhaite croiser plusieurs variables (plus que deux).
Graphique des proportions
Nous commencerons par calculer les proportions, puis nous tracerons le graphique.
# Tableau de contingence
tab <- xtabs(~drv, data = mpg) |> # Calcule les fréquences de chaque niveau de 'drv'
proportions() |> # Convertit les fréquences en proportions
print() # Affiche les proportions (facultatif)drv
4 f r
0.4401709 0.4529915 0.1068376 plot(tab, xlab = "drv", ylab = "Proportion")
barplot(tab, xlab = "drv", ylab = "Proportion")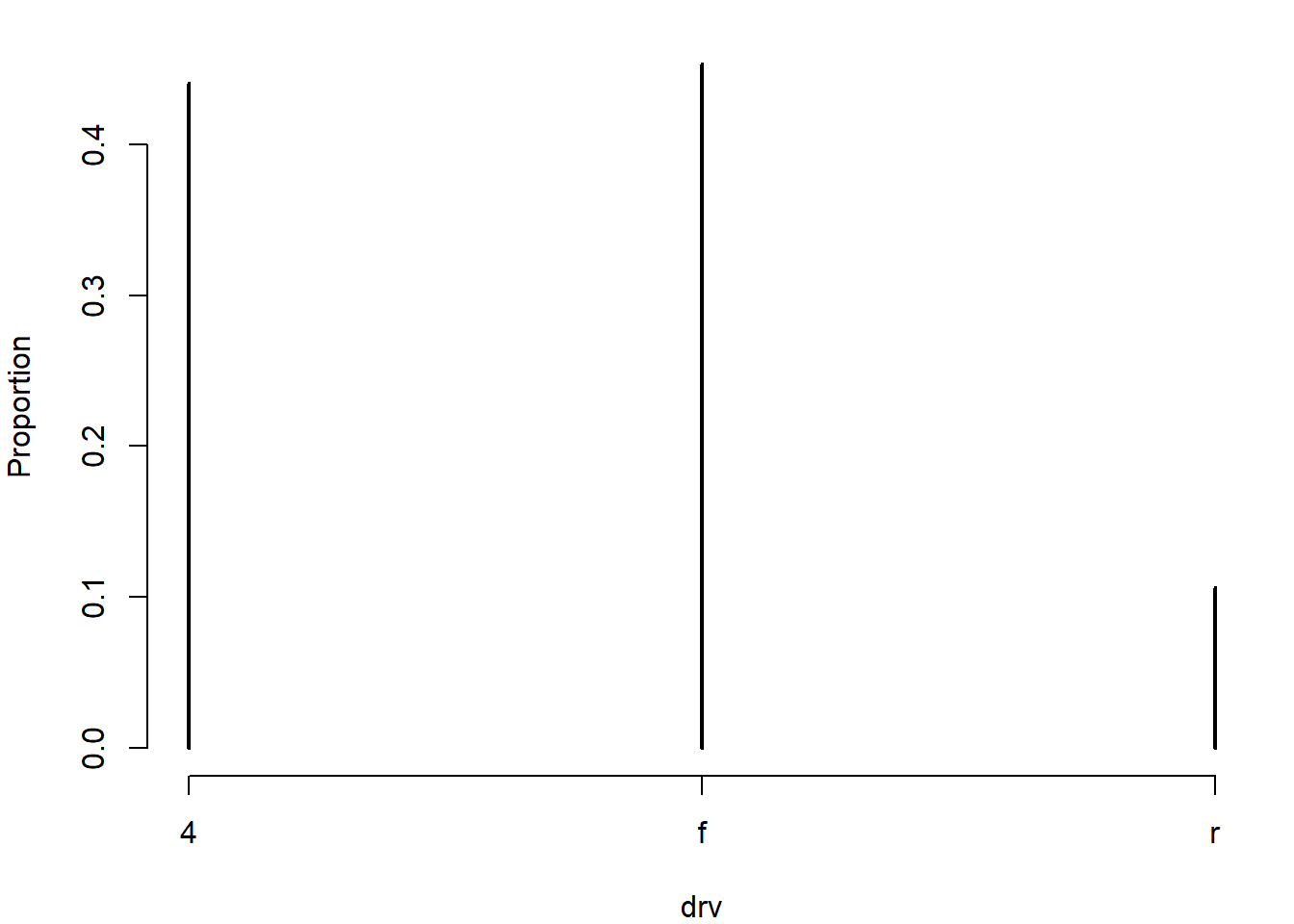
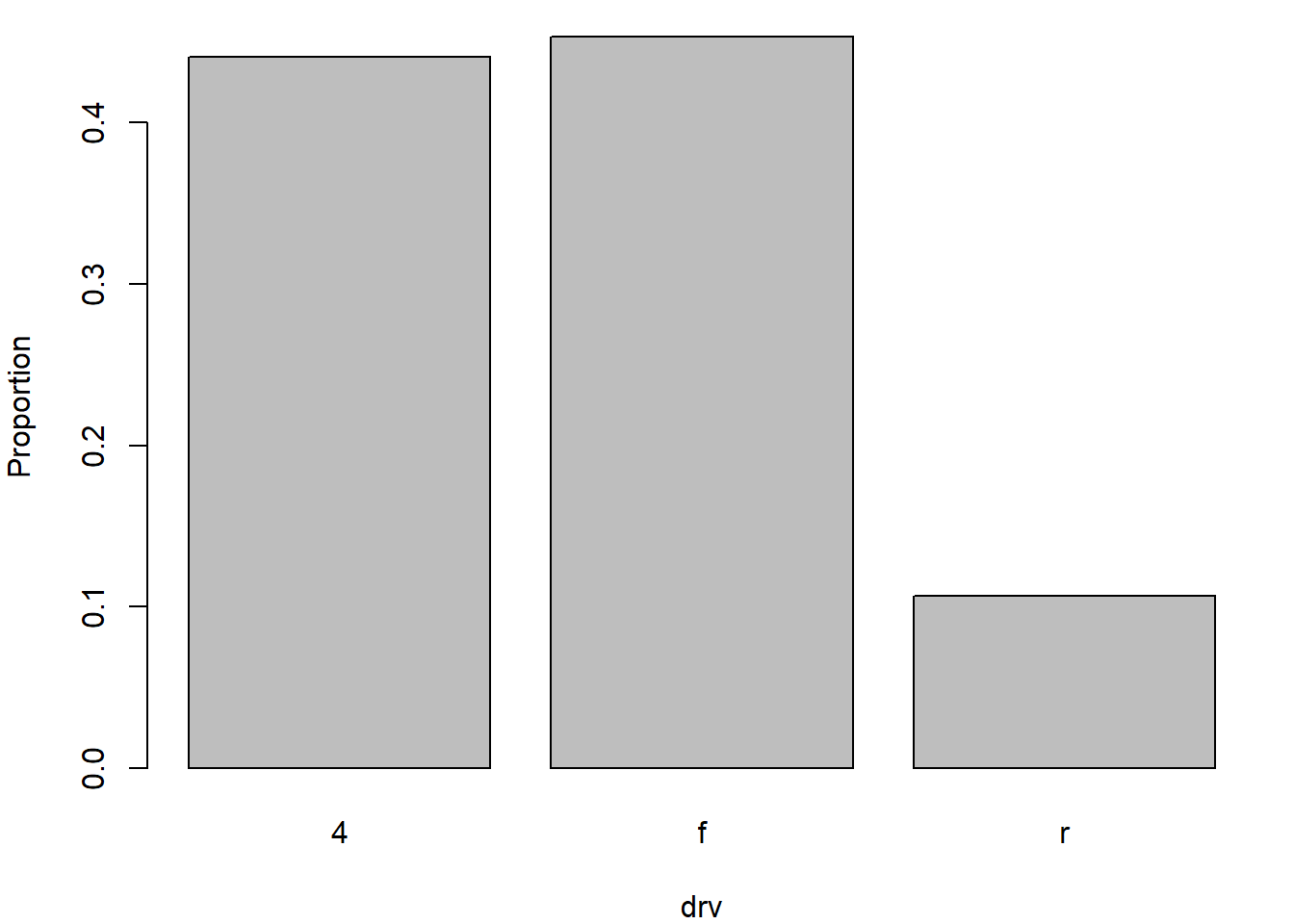
Deux facteurs
Barres empilées :
- 1
-
Crée un tableau de contingence croisé entre
drv(lignes) ettrans(colonnes). Chaque cellule contient le nombre d’observations correspondant à une combinaisondrv×trans. - 2
-
Calcule les proportions par colonne, càd la distribution de
drvà l’intérieur de chaque niveau detrans. - 3
-
Chaque barre correspond à un niveau de
trans, et les segments colorés montrent la part relative de chaquedrvdans ce groupe.
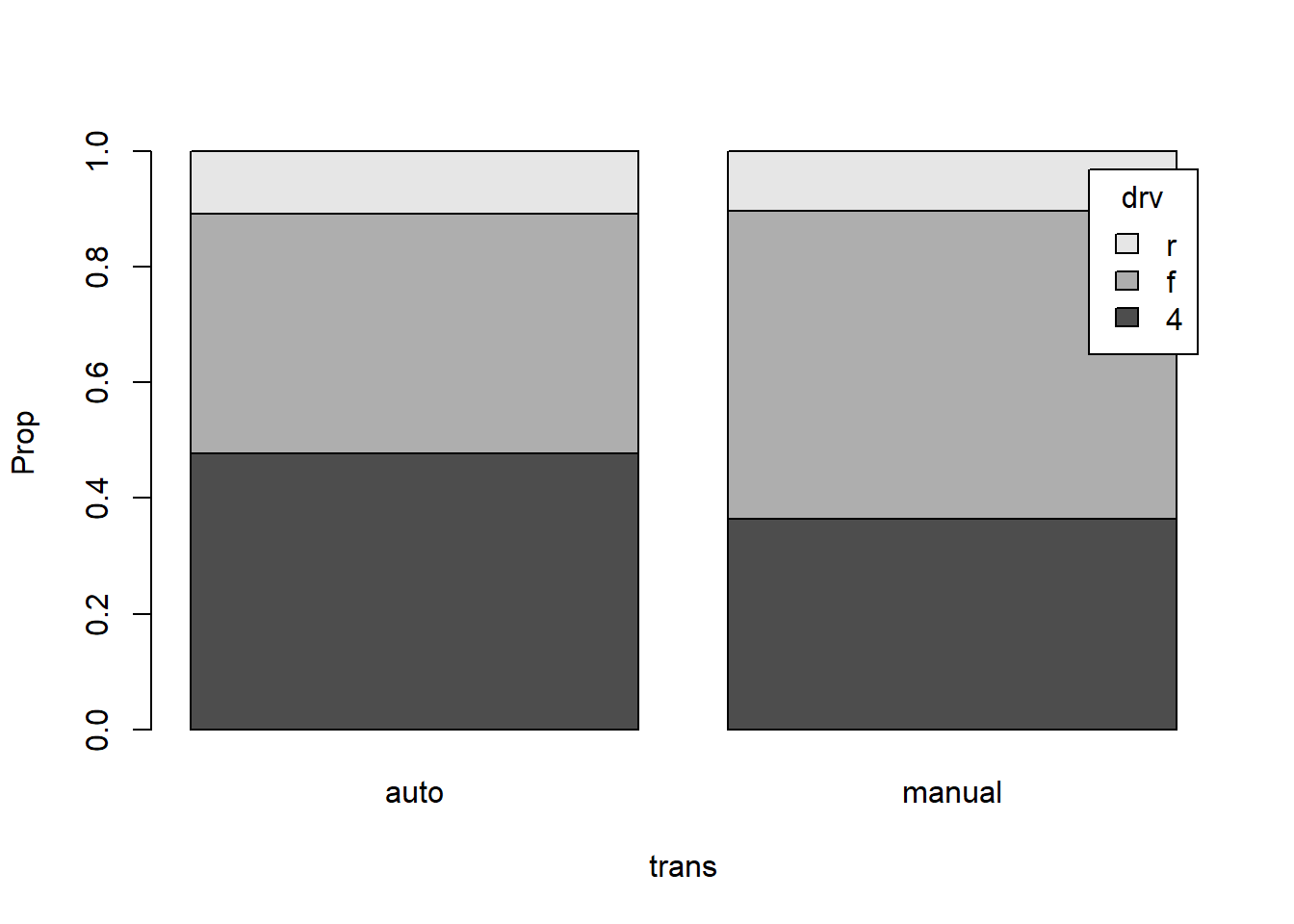
Barres juxtaposées :
xtabs(~ drv + trans, data = mpg) |>
proportions("trans") |>
barplot(beside = TRUE, # Affiche les barres côte à côte (et non empilées)
xlab = "trans", ylab = "Prop", legend = TRUE, args.legend = list(title = "drv"))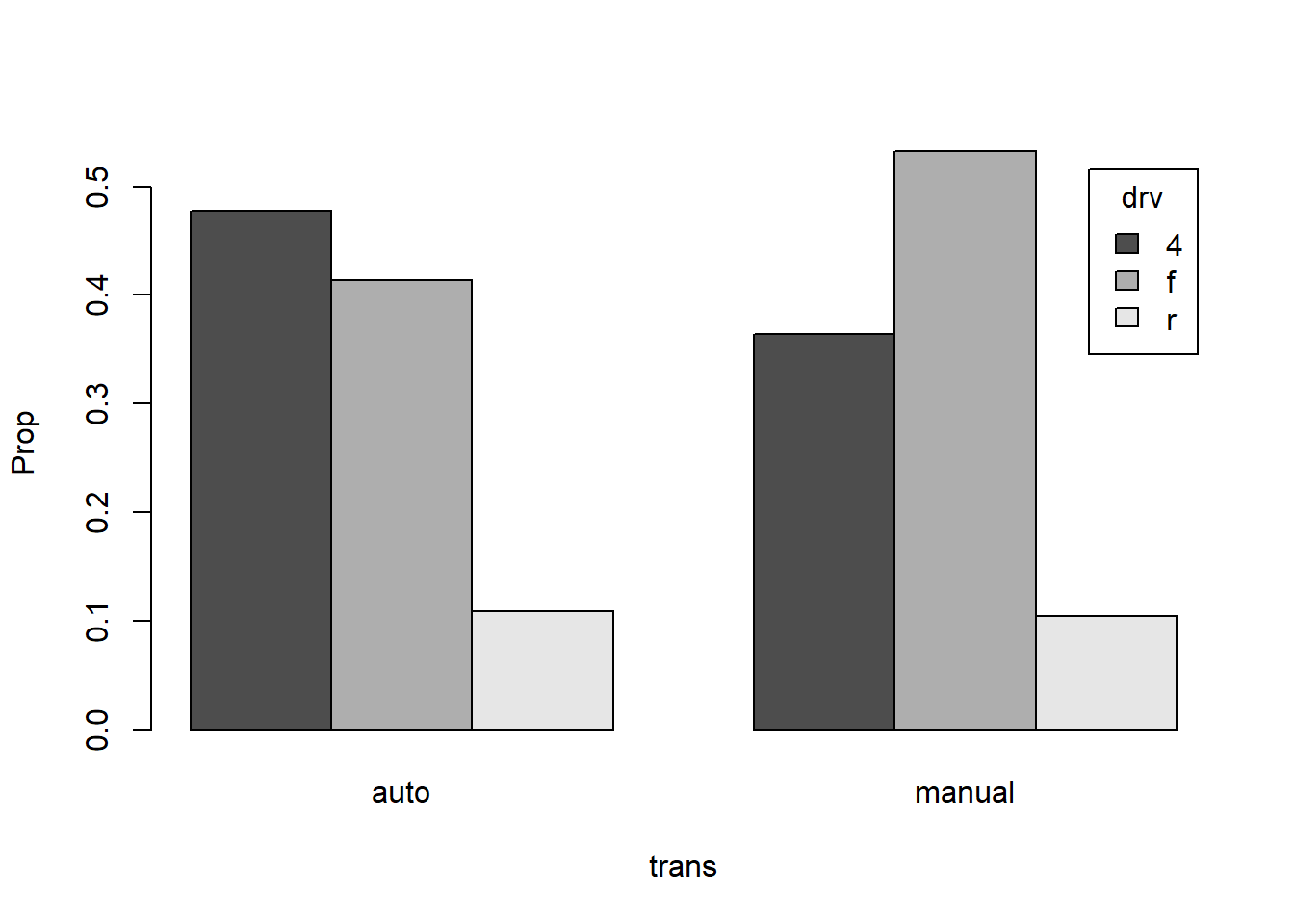
Diagramme de type « spineplot » :
La commande suivante trace un “spineplot”, un graphique similaire à un diagramme en barres empilées. La différence principale est que la largeur de chaque barre est proportionnelle au nombre d’observations pour chaque niveau de la varaible en x (ici trans), offrant ainsi une lecture plus informative de la structure des données.
plot(drv ~ trans, data = mpg)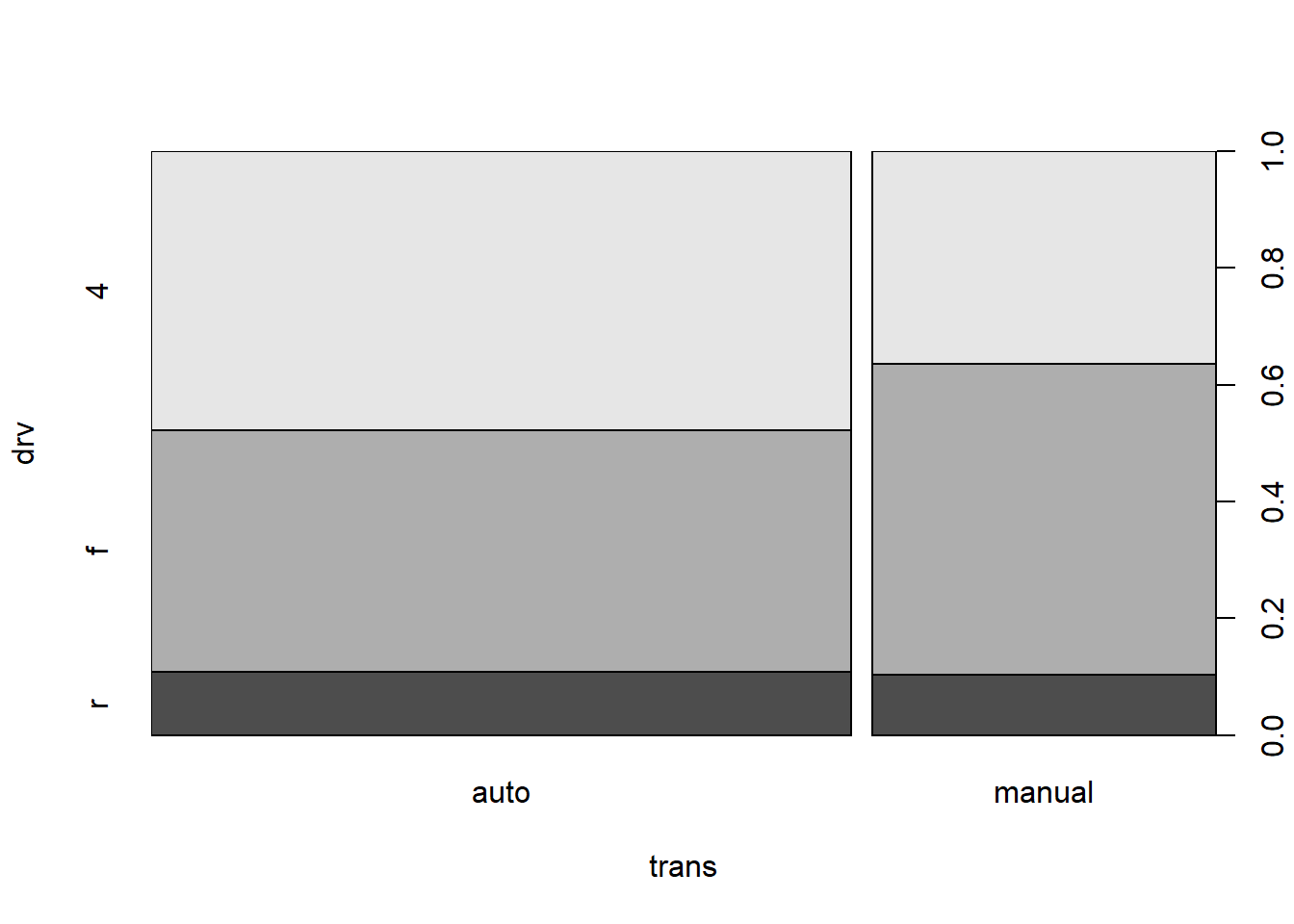
Ici, plot() appelle en interne la fonction spineplot(), qui est celle qui réalise effectivement le graphique; voir ?spineplot.
Facteur vs Numeric
plot(trans ~ hwy, data = mpg)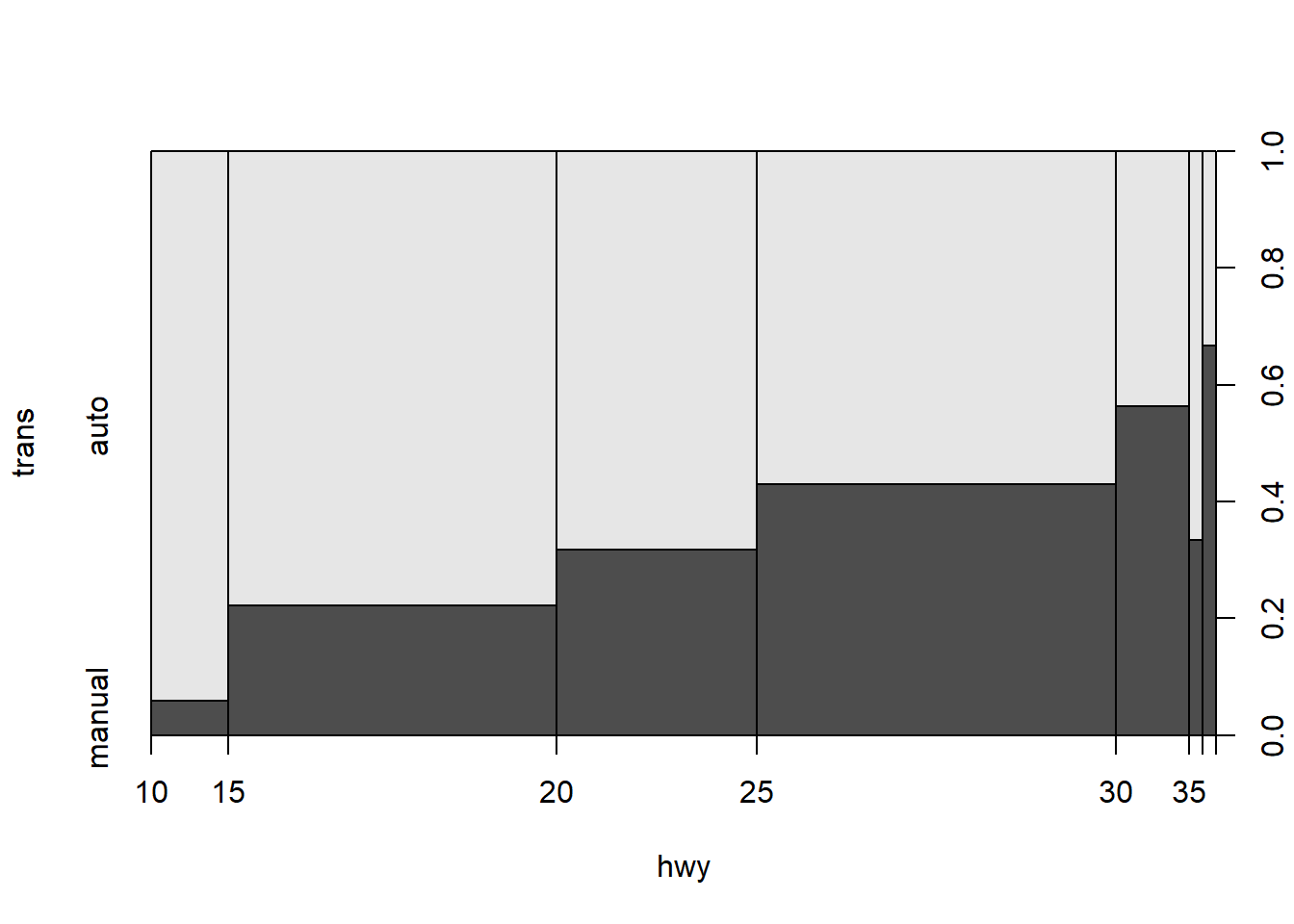
Ici, puisque trans est un facteur, alors que hwy est une variable numérique, plot() transforme automatiquement hwy en facteur, via cut(), en découpant l’intervalle des valeurs numériques en classes. Ensuite, comme les deux variables sont désormais des facteurs, plot() appelle en interne la fonction spineplot() pour réaliser le graphique.
11.5 Distribution d’une variable numérique
Histogramme
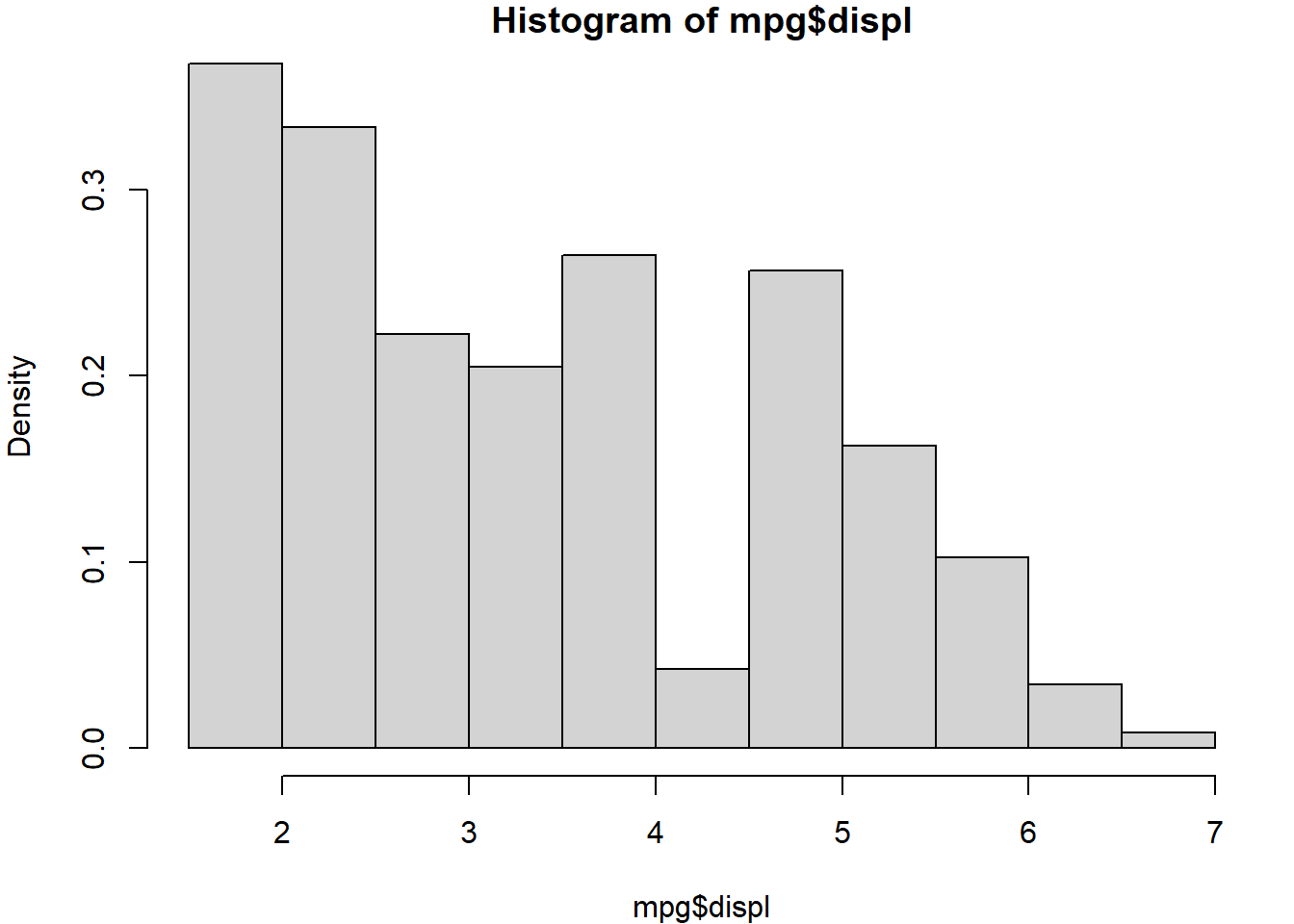
Le code suivant trace deux histogrammes (côte à côte) de la variable displ (cylindrée).
Le premier histogramme (hist(mpg$displ)) affiche les effectifs : la hauteur des barres correspond au nombre d’observations dans chaque intervalle. Le second (hist(mpg$displ, freq = FALSE)) représente les “densités”, càd les fréquences relatives rapportées à la largeur de la classe. Dans ce cas, la surface totale de l’histogramme est normalisée à 1, ce qui permet, entre autres, de le comparer à une densité théorique.
hist(mpg$displ)
hist(mpg$displ, freq = FALSE)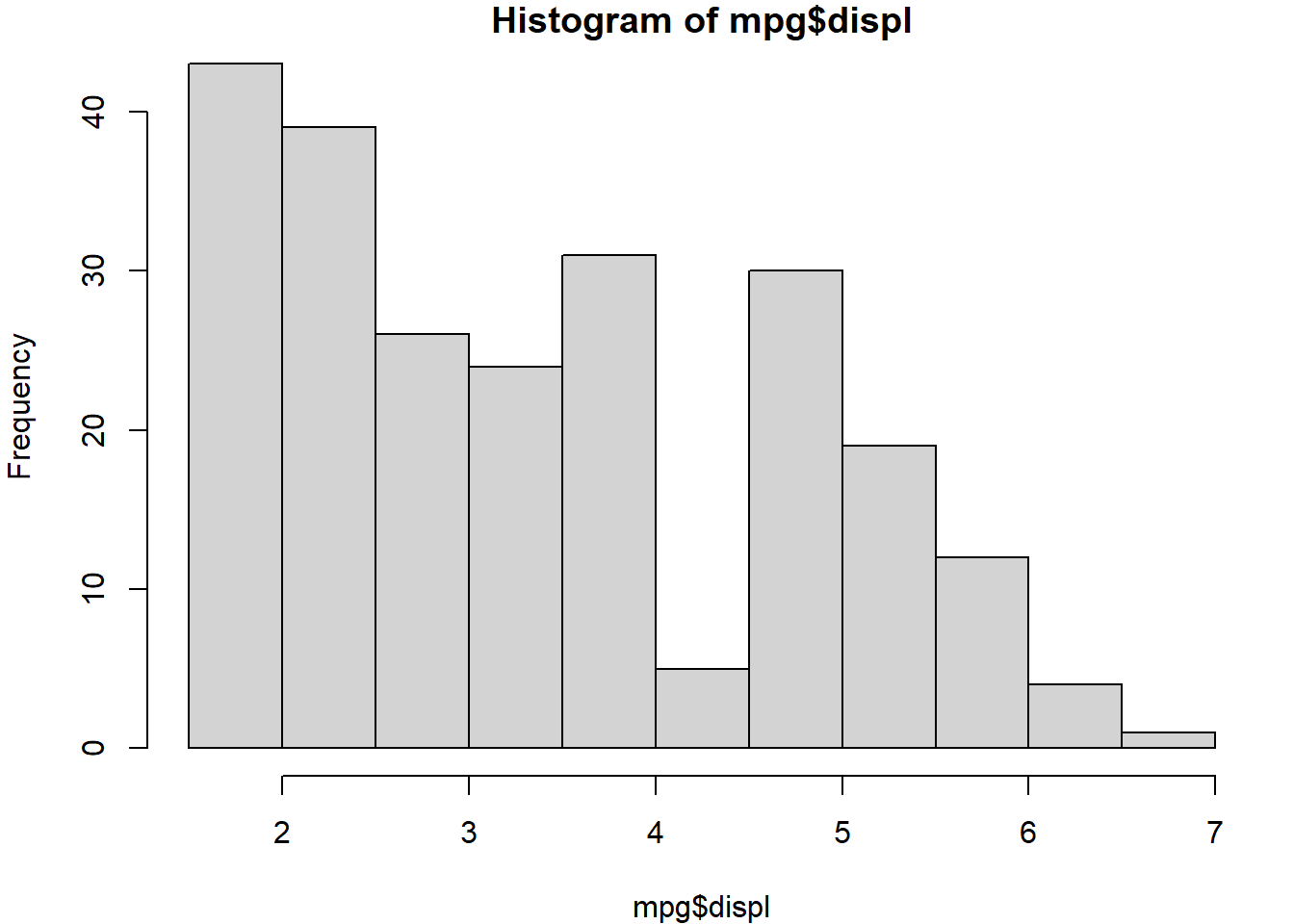
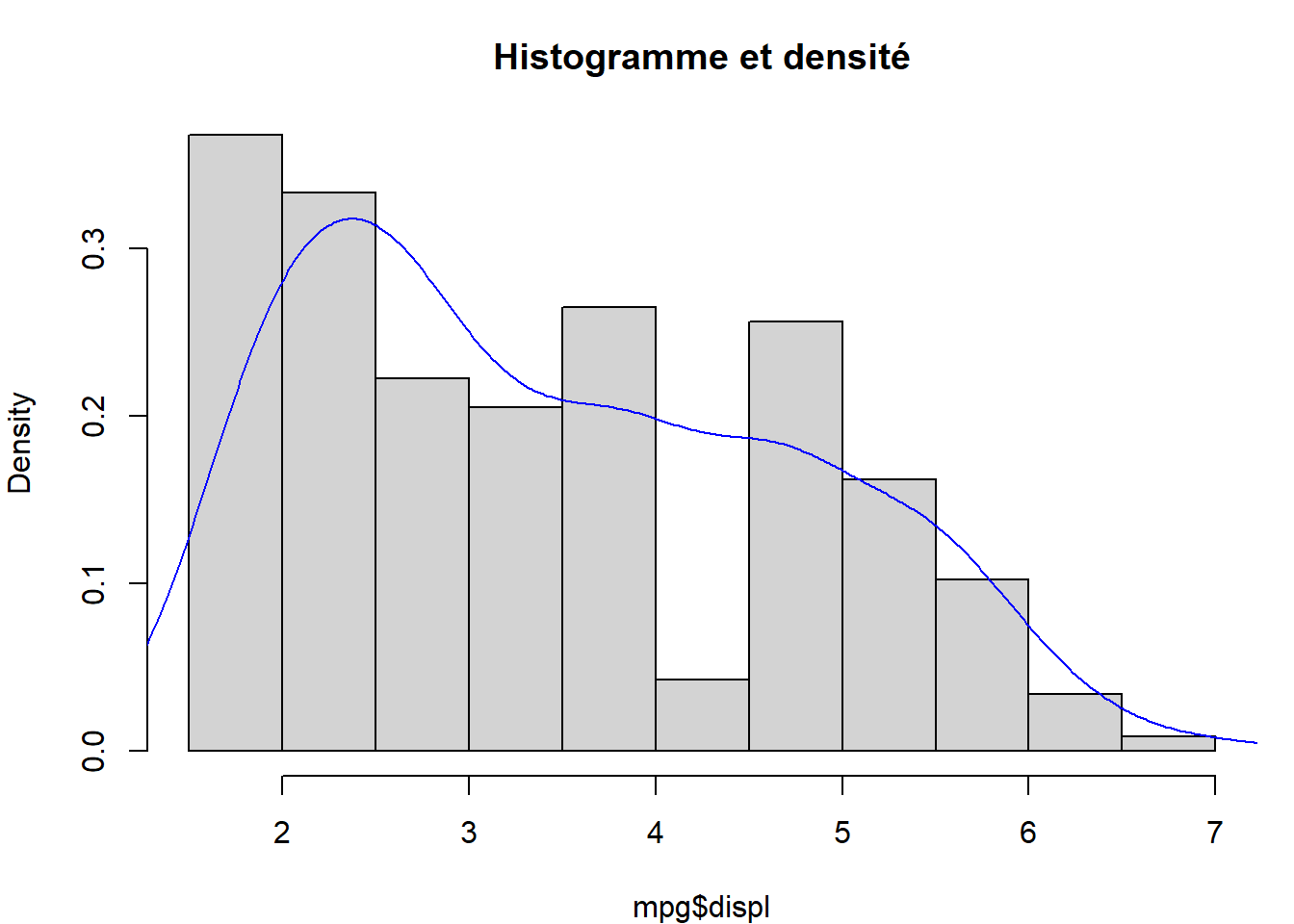
Densité échantillonnale
Les deux graphiques suivants illustrent la densité échantillonnale de la variable displ. Il s’agit en réalité d’un estimateur, dit à noyau, de la densité théorique de cette variable, obtenu à partir des données observées :
- Le premier graphique trace directement la courbe de densité estimée avec
density(mpg$displ). Cette courbe lisse représente une version continue et améliorée de l’histogramme.
- Le second graphique juxtapose un histogramme des densités (
freq = FALSE) et une courbe de densité estimée (lines(...)). La normalisation de l’histogramme (surface = 1) permet une superposition pertinente avec la courbe lisse.
Ce type de visualisation est utile pour évaluer la forme de la distribution : symétrie, asymétrie, présence de plusieurs modes, étalement, etc.
# Premier graphique
density(mpg$displ) |>
plot(main = "Density of mpg$displ")
# Deuxième graphique
hist(mpg$displ, freq = FALSE, main = "")
density(mpg$displ) |> lines(col = "blue")
title(main = "Histogramme et densité")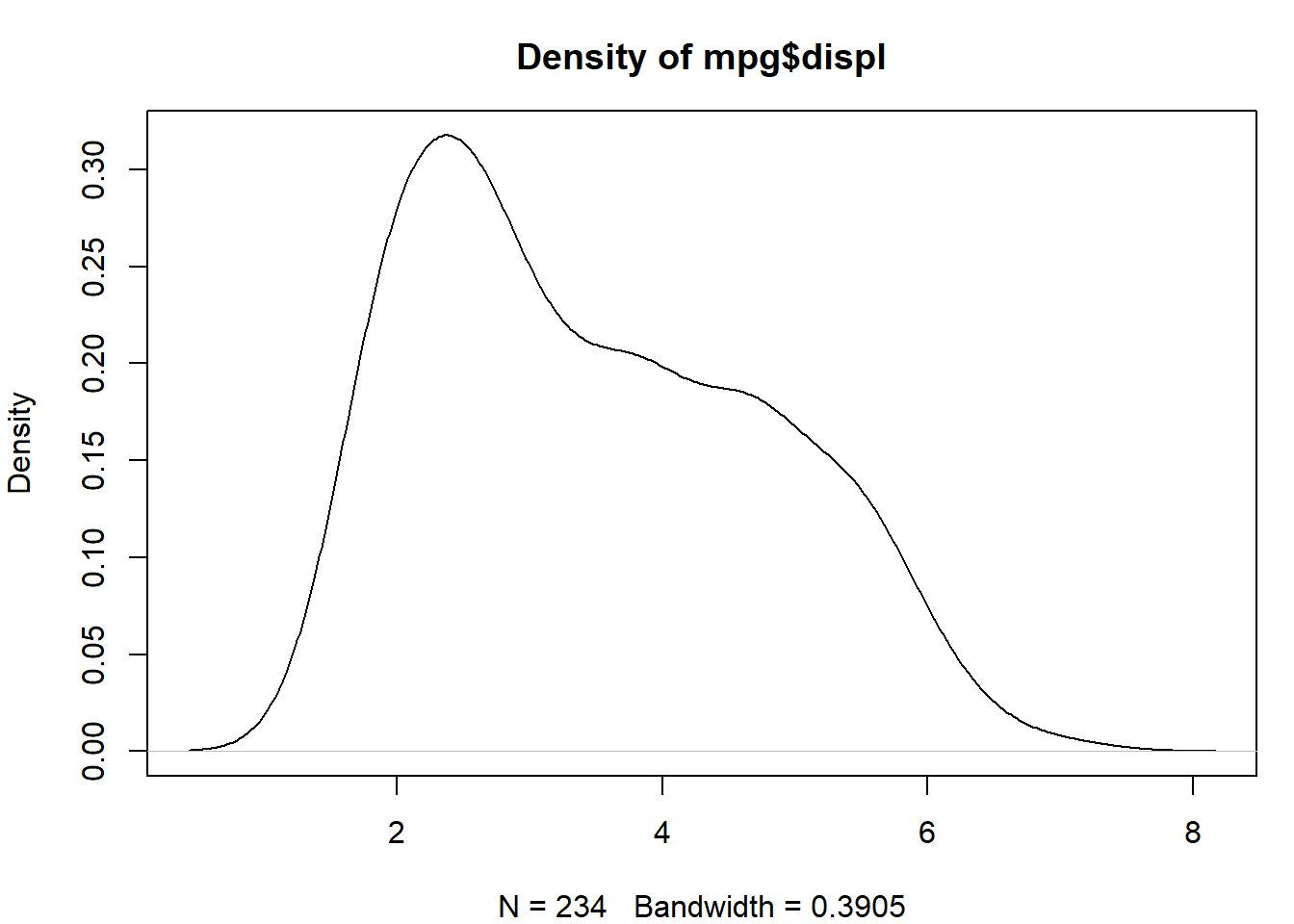
11.6 Tracer une fonction
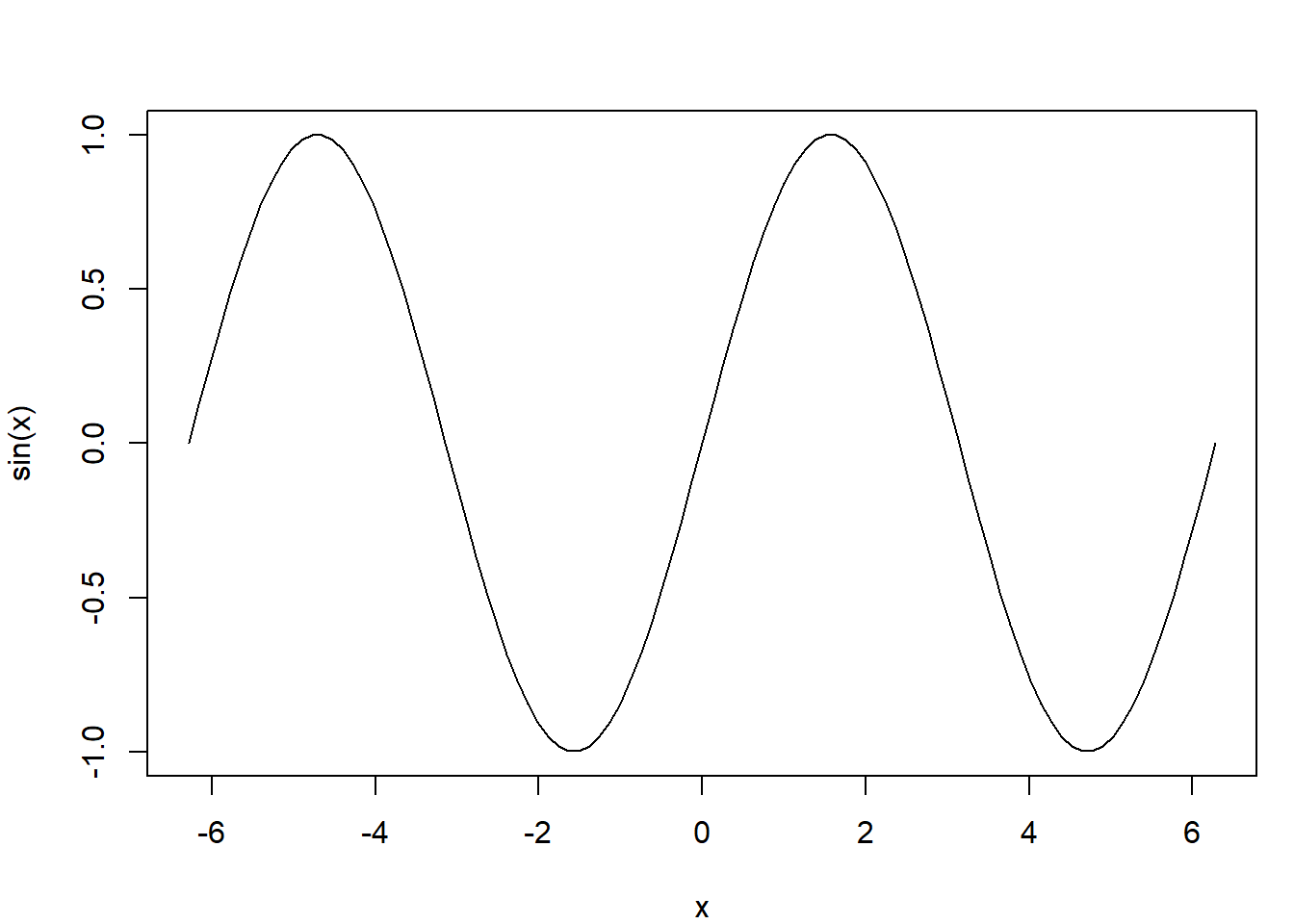
La fonction curve() permet de tracer rapidement une fonction mathématique en R. Les deux graphiques suivants illustrent son usage :
- Le premier (
curve(sin, from = ..., to = ...)) graphique trace la fonction sinus.
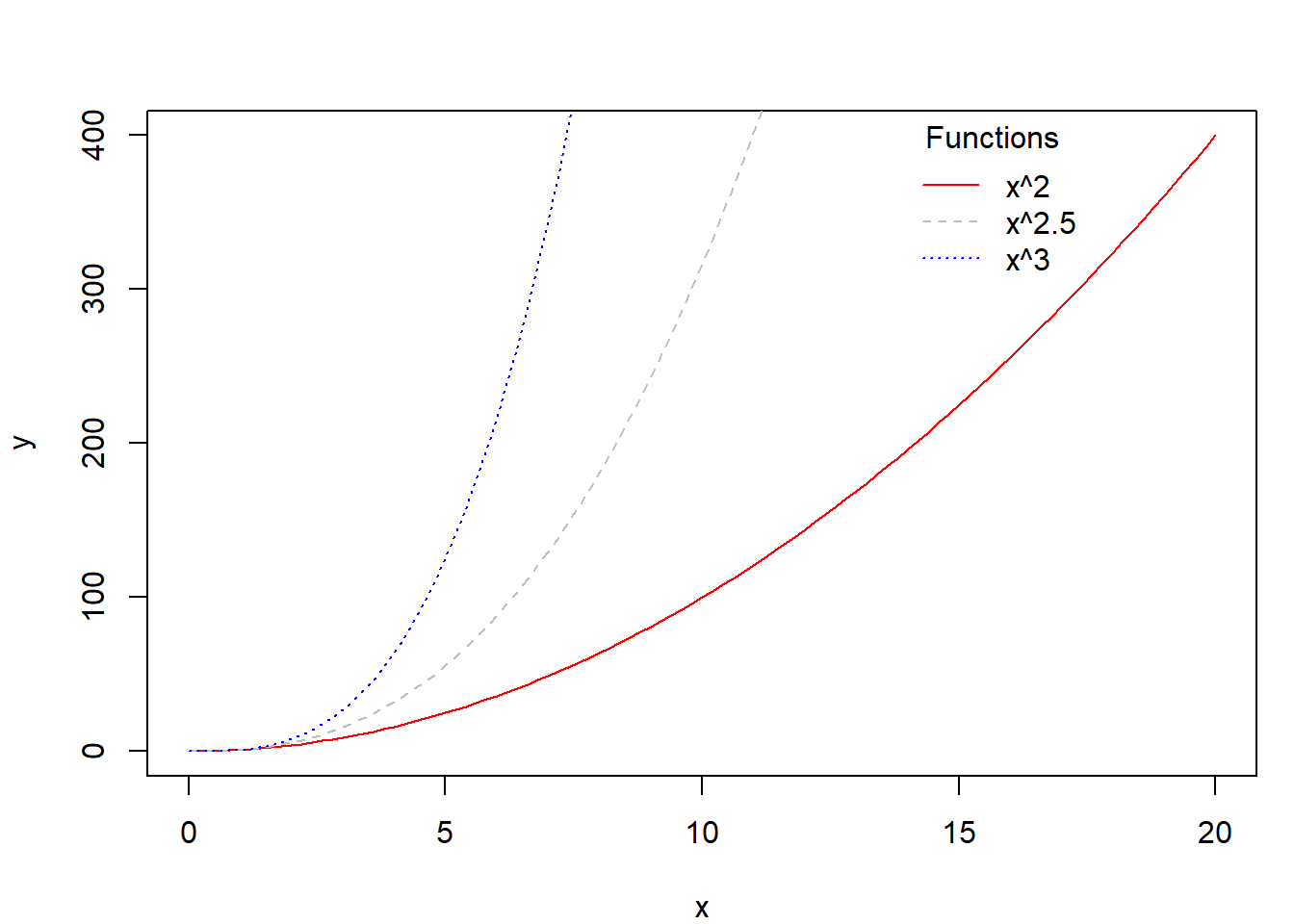
- Le second graphique superpose trois courbes : (i) x^2 en rouge, (ii) x^{2.5} en gris, et (iii) x^3 en bleu. Les deux dernières courbes sont ajoutées successivement grâce à l’argument
add = TRUE. Une légende est insérée en haut à droite aveclegend()pour identifier chaque fonction.
# Premier graphique
curve(sin, from = -2 * pi, to = 2 * pi)
# Deuxième graphique
curve(x^2, from = 0, to = 20, col = "red", lty = 1, ylab = "y")
curve(x^(2.5), from = 0, to = 20, col = "gray", lty = 2, add = TRUE)
curve(x^(3), from = 0, to = 20, col = "blue", lty = 3, add = TRUE)
legend("topright", title = "Functions", # Ajout d’une légende en haut à droite
legend = c("x^2", "x^2.5", "x^3"),
col = c("red", "gray", "blue"),
lty = 1:3,
bty = "n", # Supprime le cadre de la légende
inset = c(0.15, 0)) # Décale la légende horizontalement (15% vers la gauche)