2 Concepts de base
Dans ce chapitre, nous allons vous présenter quelques concepts de base indispensable pour vous familiariser au langage de programmation R, et pour pouvoir, par la suite, travailler pertinemment.
2.1 Stocker une valeur dans un objet
Pour réutiliser un objet en R, il faut le stocker. Cela peut se faire à l’aide de l’opérateur assignation = ou <-.
Cette ligne de code déclare un objet nommé x et lui assigne le chiffre 12. L’exécution de ce code, n’entraîne aucun résultat visible (rien n’est affiché à la console) mais l’objet nommé x est bel est bien créé.
Pour afficher le contenu d’un objet, il suffit de taper son nom dans la console suivi de “Enter”
[1] 12Il est intéressant de savoir que lorsque l’on tape le nom d’un objet à la ligne de commande pour voir son contenu, en réalité c’est la fonction print() qui est automatiquement appelée.
[1] 12À présent que x est sauvegardé, on peut le manipuler à l’aide de tous types de fonctions/opérations sans pour autant modifier sa valeur.
[1] 144
[1] 3.46
[1] 12Pour modifier x, il suffit de lui attribuer une nouvelle valeur.
[1] 6Vous pouvez aussi affecter le contenu d’une variable dans une autre variable, càd copier ce que contient la première dans la seconde.
[1] 6Remarquez que chaque variable est indépendante. Si on modifie l’une, l’autre n’est pas affectée.
[1] 6Voici un autre exemple de stockage et de manipulation d’objets en R.
[1] 25
[1] 54
[1] 13.5
[1] 7292.2 Les fonctions prédéfinies
Les fonctions constituent une composante primordiale du langage R. Nous avons déjà vu et utilisé une série de fonctions telles que sqrt(), log(), etc.. Aussi, les opérateurs qu’on a rencontrés jusqu’à présent (+, -, *, …) sont, en fait, que des raccourcis de fonctions.
Cette section passe en revue les règles d’appels d’une fonction, les arguments (ou paramètres) et la façon d’obtenir de l’aide.
Une fonction R se caractérise de la manière suivante: (i) elle a un nom, (ii) elle a une liste d’arguments, avec éventuellement des valeurs par défaut, (iii) elle a un corps, càd les instructions qui la constituent, (iv) elle retourne un ou plusieurs résultat(s) et/ou effectuer une action comme dessiner un graphique, lire un fichier, etc.. Le corps d’une fonction est du ressort du programmeur qu’il a défini. Le reste est indispensable pour quiconque qui veut l’utiliser.
L’appel à une fonction se fait typiquement comme suit
où val.1, val.2, etc., sont les valeurs attribuées aux arguments arg.1, arg.2, etc.. Lorsqu’on passe un argument à une fonction de cette manière, c’est-à-dire sous la forme nom_arg = valeur, on parle d’argument nommé.
Certains arguments peuvent avoir des valeurs par défaut (prédéfinies). Les arguments ayant une valeur par défaut peuvent ne pas être fournis en entrée, auquel cas leur valeur par défaut est utilisée. Les arguments qui ne possèdent pas de valeur par défaut sont obligatoires.
Obtenir de l’aide
Pour connaitre tous les arguments d’une fonction, connaitre les valeurs par défaut, et, plus généralement, obtenir de l’aide sur l’utilisation et le type de résultat qu’elle retourne, on peut entrer à la console l’une des commandes suivantes en remplaçant <nom.fonct> par le nom de la fonction.
Illustrons cela avec la fonction seq, qui sert à construire des suites (séquence) de nombres. Si vous tapez ?seq. Vous allez voir apparaître dans l’onglet Help de RStudio une page (en anglais) qui fournit, entre autres :
- Le titre, suivi d’une description brève de la fonction.
- La section Usage qui donne un aperçu de la syntaxe de la fonction ainsi que la liste des arguments, leur ordre prédéfini et leurs valeurs par défaut. Les arguments, suivi par le symbole
=ont une valeur par défaut. Il n’est donc pas nécessaire de les inclure dans l’appel de la fonction, auquel cas la valeur pas défaut sera prise en compte. Tous les autres arguments doivent recevoir une valeur. - La description détaillée de chaque argument est donnée dans la section Arguments.
- D’autres précisions sur l’utilisation de la fonction sont souvent fournies dans la section Details.
- Une description de ce que la fonction renvoie est donnée dans la section Value.
- Des exemples d’utilisation typique sont fournis dans la section Examples. Ces exemples sont souvent très utiles.
Sachez que toute fonction en R (désignée à être utilisé par la communauté) doit avoir une fiche d’aide. De nos jours, ces fiches sont souvent accompagnées par une riche documentation en ligne.
Par la suite, on vous conseille vivement de systématiquement jeter un coup d’œil sur le Help de chaque nouvelle fonction que vous rencontrerez.
Les arguments et leur valeur
L’exécution d’une fonction revient à exécuter le code (les instructions) du corps de la fonction en remplaçant les arguments qui y figurent par les valeurs fournies par l’utilisateur. La façon avec laquelle les arguments sont associés aux valeurs fournies est un élément très important du langage R.
Pour comprendre cela plus facilement, examinons de plus près le Help de la fonction seq(). On peut y voir à la paragraphe “## Default S3 method:” de la section Usage (voir aussi la section Arguments):
seq(from = 1, to = 1, by = ((to - from) / (length.out - 1)), length.out = NULL, along.with = NULL, ...)ce qui indique que cette fonction accepte les arguments from, to, by, length.out, along.with, et un autre argument spéciale dénoté par le symbole <...> qu’on va ignorer pour l’instant.
On constate que tous ces arguments ont déjà une valeur par défaut: from = 1, to = 1, etc.. Ainsi on peut faire appel à cette fonction sans donner d’argument (même si, dans ce cas, cela n’a aucune utilité !)
[1] 1Ce qui est équivalent à écrire
[1] 1Voici des exemples d’appel plus élaborés.
[1] 5 6 7 8 9 10 [1] 5.0 5.5 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0Lors de l’appel d’une fonction, les arguments peuvent être nommés ou non, les arguments non-nommés sont mis en correspondance par position. càd selon un ordre prédéfini qui correspond à la position/place occupée par chaque argument dans la liste des arguments telle qu’elle figure dans la définition de la fonction. Pour seq(), par exemple, l’ordre prédéfini des arguments est le suivant: (1) from, (2) to, (3) by, etc.. En pratique, on peut distinguer trois situations :
- Tous les arguments sont nommés : dans ce cas, l’ordre d’appel n’a aucun importance.
[1] 1 3 5 7 9[1] 1 3 5 7 9- Tous les arguments ne sont pas nommés : dans ce cas, les arguments doivent apparaître dans l’ordre prédéfini.
[1] 1 3 5 7 9- Cas mixte : si nous mélangeons des arguments nommés et non nommés, ceux nommés sont mis en correspondance en premier. Les autres arguments (sans nom) sont mis en correspondance dans l’ordre fourni lors de l’appel.
[1] 1 3 5 7 9[1] 1 3 5 7 9Pour éviter toute confusion, il est fort conseillé de nommer tous les arguments d’une fonction sauf peut-être le premier.
Notez que les noms formels des arguments peuvent être abrégés tant que l’abréviation n’est pas ambiguë. Voici un exemple.
[1] 1 3 5 7 9Cela fonctionne car from est le seul argument de seq() qui commence avec la lettre “f”, et donc il est impossible de le confondre avec un autre.
Notez aussi que l’on peut passer directement des objets en arguments, en écrivant leur nom. Ces objets seront remplacées par leur valeurs quand R exécutera la fonction
[1] 1 3 5 7 9 11 13 15 17 19Note
Tous les opérateurs en R tels que +, -, <-, etc. sont en réalité des raccourcies de fonctions. Prenons, par exemple, l’opérateur +. Au lieu de taper 1+5, on peut très bien écrire '+'(1,5). Pour <-, au lieu d’écrire x <- 2, nous pouvons écrire '<-'(x, 2), etc. Aussi, pour obtenir de l’aide à propos de la fonction/opérateur +, on peut écrire help('+') ou ?'+'.
Quelques remqrues
+ argument vs objet
Attention à ne pas confondre l’argument d’une fonction et un objet de l’environnent globale. Un argument n’est rien d’autre qu’une variable (interne) de la fonction alors qu’un objet est une structure globale qui ne dépend d’aucune fonction. Certaines situations peuvent prêter à confusion (et parfois induire en erreur). Voici un exemple
by <- 5 # ceci est un objet avec aucun lien avec la fonction seq()
seq(from = 1, to = 20) # équivalent à seq(from = 1, to = 20, by = 1)
seq(from = 1, to = 20, by = by) # équivalent à seq(from = 1, to = 20, by = 5)
seq(by, to = 20) # équivalent à seq(from = 5, to = 20, by = 1) [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[1] 1 6 11 16
[1] 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20+ fonction générique
La fonction print(), vue précédemment, est un exemple de ce qu’on appelle une fonction générique dans R. Une fonction générique est simplement une fonction qui exécute une certaine tâche en envoyant son entrée à une fonction/méthode particulière qui est choisie sur base des attributs de l’entrée fournie. La liste des méthodes existant pour une fonction générique s’obtient avec la fonction methods()
Comme sortie, pour cette commande, on obtient une liste de noms sous la forme print.<NomMéthode>. Cela pour dire que, par exemple, lorsqu’un objet de type data frame est détecté, la fonction print() fait appel à la fonction print.data.frame(), et pour un facteur, print() fait appel à print.factor(), etc.. print.default() est utilisée pour tout objet qui ne possède pas une méthode qui lui correspond.
+ formula
Il existe des fonctions qui acceptent à la fois une écriture classique, sous forme fun(arg1 = varX, arg2 = varY), et une écriture dite formule (formula, en anglais), sous forme fun(formula = varY ~ varX). L’exemple le plus classique est ce lui de la fonction plot() qui permet de faire des graphiques; voir la section sure les graphes en R.
Une formule est une expression symbolique qui, dans sa version la plus simple, s’écrit sous la forme varY ~ varX, où varX et varY sont les noms des variables à mettre en relation. Dans cette expression varY, à gauche de ~, est la variable d’internet, càd la variable qu’on cherche à étudier/expliquer. De côté droit de ~ se trouve varX qui est la variable explicative ou variable de regroupement. On peut lire varY ~ varX comme: varY en fonction de varX ou varY sachant varX.
Sachez qu’il existe aussi des fonctions qui n’acceptent que des formules comme argument principal/premier. Un bon exemple est celui de la fonction xtabs().
+ L’argument spécial ...
Certaines fonctions R possèdent un argument nommé .... Lorsque ce dernier est placé au tout début de la liste des arguments cela indique, typiquement, que la fonction peut recevoir en entrée un nombre indéterminé de valeurs à traiter. C’est le cas, par exemple, de la fonction c() qui peut combiner autant de valeurs que désiré. Si ... est placé au milieu ou à la fin de la liste des arguments, alors cela sert typiquement à indiquer que la fonction peut passer des arguments à une autre fonction contenue dans le corps de la fonction que l’on appelle, c’est le cas, par exemple, de la fonction pour la fonction aggregate().
2.3 Enchaîner les commandes avec |>
Depuis sa version 4.1.0, sortie en mai 2021, R a introduit l’opérateur |>, appelé “pipe”, qui permet de structurer le code de manière séquentielle et plus lisible.
Le principe de cet opérateur est de passer l’élément situé à sa gauche comme premier argument de la fonction située à sa droite. Ainsi, pour une fonction fun et un objet a quelconques, l’écriture classique fun(a) peut être remplacée par
Ceci peut se lire comme “prend l’objet a et y appliquer la fonction fun”. Voici un exemple:
[1] 3.46Cette façon d’écrire du code R est surtout utile lorsqu’il s’agit d’enchaîner plusieurs opérations. Ainsi, au lieu d’écrire
nous pouvons écrire
Ce qui peut se lire comme suit: prendre 12, puis calculer son logarithme à base 10, puis calculer la racine carrée, puis calculer l’exponentielle.
Pour faciliter davantage la lecture du code, il est recommandé de faire un retour à la ligne après chaque |>. Comme ceci
Pour utiliser correctement cet opérateur, gardez en tête les deux règles suivantes :
- Les parenthèses à côté du nom de chaque fonction sont obligatoires, et
|>fait toujours référence au premier argument de la fonction située à sa droite. Autrement dit, pour une fonctionfun(a, b, c)de trois paramétrésa,betc, par exemple, l’écriture1 |> fun(2, 3)se traduit parfun(a = 1, b = 2, c = 3).
Si vous voulez faire référence à un argument autre que le premier, vous devez alors le nommer et le spécifier à l’aide l’opérateur _, appelé “placeholder”. Par exemple, l’écriture
se traduit par fun(a = 22, b = 0, c = 71). Si vous oubliez de nommer l’argument concerné et écrivez par exemple 71 |> fun(22, 0, _), R renvoie une erreur de type
Il faut également faire attention lorsque |> est utilisé avec d’autres opérateurs, comme par exemple avec des opérateurs arithmétiques. Voici un exemple :
[1] 10.4Cette sortie s’explique par le fait que l’opérateur |> a une priorité plus élevée que les opérateurs arithmétiques +, - *, et /, ce qui signifie que le pipe est évalué avant ces opérations. Ainsi, le code ci-dessus se traduit en réalité par 10 + 2/sum(2, 3). L’usage de parenthèses ou d’accolades permet de contrôler explicitement l’ordre d’exécution.
[1] 14En RStudio, pour insérer |> facilement, vous pouvez utiliser le raccourci clavier Ctrl + Maj + M. Pour que ce raccourci fonctionne, assurez-vous d’avoir coché l’option “Use native pipe operator” dans le menu Tools -> Global Options -> Code -> Editing.
Par la suite nous aurons recours à cet opérateur uniquement lorsque cela sera jugé utile pour la lisibilité du code.
Note
Un autre pipe très utilisé est %>%, fourni par le package magrittr, qui fait partie de la célèbre collection de packages tidyverse. Bien qu’ils aient des usages similaires, |> est plus simple, notamment parce qu’il est intégré directement à R.
2.4 Session R et espace utilisateur
Tout objet dans R est retenu dans ce qui est connu sous le nom de Environment. Un environnement n’est rien d’autre qu’un espace de stockage virtuel (comme un dossier d’un ordinateur) dans lequel se trouve une collection d’objets, chaque objet est identifiable avec un nom unique (comme les fichiers d’un dossier).
Chaque fois qu’une nouvelle session R est lancée, un environnement vierge appelé Global Environment (ou espace utilisateur) est crée. Par defaut, c’est cette environnement qui sera utiliser pour tous les objets créés au cours de la session en cours.
La fonction ls() permet de lister tous les objets disponibles dans le Global Environment. Jusqu’à présent, nous avons créé les objets suivants:
[1] "a" "b" "by" "x" "y" "z" Vous pouvez aussi consulter cette lite sur l’onglet Environment (dans le quadrant supérieur droit de RStudio).
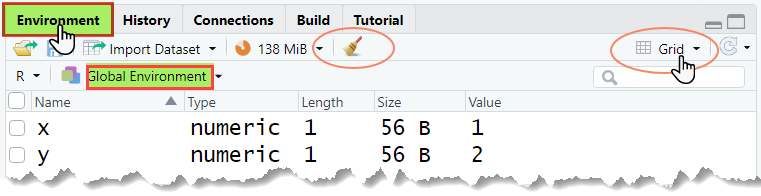
Remarquez le menu déroulant intitulé “Global Environment”, qui indique que vous êtes bien dans l’environnement global. Vous pouvez modifier la façon dont les objets sont affichés dans l’onglet Environment en cliquant sur l’icône en haut à droite: L’icône en forme de liste active le mode List View (vue compacte). L’icône en forme de grille active le mode Grid View. Utilisez ce dernier car il est bien plus pratique.
Pour supprimer un ou plusieurs objets, on utilise la fonction rm().
Vous pouvez aussi utiliser l’onglet Environment et la petite case devant chaque objet pour le sélectionner, et ensuite le(s) supprimer en appuyant sur le l’icône en forme de balai.
Si vous tapez x, après l’avoir supprimé, vous obtenez un message d’erreur, puisque l’objet x n’existe plus.
Error: object 'x' not foundSauf contre indication, lorsque vous quitter RStudio, tout objet créé sera automatiquement détruit.
2.5 Working directory
Souvent R doit lire ou écrire dans ou à partir de fichiers externes pour, par exemple, charger des données à analyser ou sauvegarder un objet, un output, ou un graphique. Pour cela, R se définit un emplacement par défaut. Cet emplacement porte le nom de répertoire de travail (Working directory, en anglais).
Autrement dit, lorsque vous communiquez à R le nom d’un fichier à utiliser pour lire ou écrire, sans préciser l’emplacement (chemin d’accès) de ce dernier, R comprend que le fichier se trouve dans le Working directory. Si ce n’est pas le cas, alors il stoppe l’exécution du code et retourne un message d’erreur.
Pour connaître le Working directory de la session en cours, on utilise la fonction getwd(). Cette fonction n’a aucun argument. Pour l’utiliser, il suffit de taper
Dans RStudio, le nom de votre Working directory est affiché dans le quadrant inférieur gauche, en gris, à la droite de l’onglet Console.

Par défaut, votre working directory correspond à Home directory, càd le répertoire utilisateur sur votre machine. Ce dernier est indiqué par le symbole ~. Son emplacement, que vous pouvez afficher avec la commande Sys.getenv("HOME"), dépend de votre système d’exploitation et de la configuration de votre machine.
Si vous cliquez sur la petite icône en forme de flèche juste à côté du nom du Working directory, le contenu de ce dernier sera affiché dans le coin inférieur droit (volet Files).
Le working directory peut être modifié avec la fonction setwd() ou, plus simple, via le menu Session > Set Working Directory > Choose Directory. Une nouvelle fenêtre s’ouvrira où vous pourrez naviguer jusqu’au dossier que vous disérez choisir comme nouveau Working directory, puis validez en appuyant sur Open (Ouvrir).
Pour voir comme cela marche, on va enregistrer les objets x, y et z dans un fichier.
L’enregistrement d’un objet dans R se fait à l’aide de la fonction save() en précisant la liste des objets à enregistrer suivie de l’argument file qui doit fournir le nom à attribuer au fichier de sauvegarde. Ce denier doit avoir une extension “.Rda” (ou “.RData”).
Le fichier “xyz.Rda” sera enregistré dans votre Working directory (vérifiez que c’est bien le cas).
Note
Si vous souhaitez enregistrer autre part que dans votre Working directory, vous devez indiquer le chemin complet vers l’emplacement souhaité. Sous Windows, pour indiquer à R un chemin, il faut utiliser / ou \\ et non pas \. Comme ceci
Pour charger les donnés d’un fichier “.Rda” (ou “.RData”), il suffit d’utiliser la fonction load() ou, plus simple, via le menu File > Open File.... Naviguez jusqu’au fichier que vous désirez ouvrir, puis validez en appuyant sur Open (Ouvrir). Par la suite, une nouvelle fenêtre s’ouvrira avec le message “Do you want to load the R data file …”, validez de nouveau en appuyant sur Yes (Oui). Tous les objets se trouvant dans le fichier chargé seront accessibles par la suite. Pour voir cela, supprimez x, y, et z avec la commande rm(x,y,z)
, puis charger le fichier “xyz.Rda”, vérifiez que ces objets sont de nouveau disponibles.
Si R vous renvoie un message d’erreur du type “Error in … cannot open the connection …”, vérifiez votre répertoire de travail et le nom du fichier que vous avez spécifié.
vous pouvez sauvegarder tous les objets créés durant une session, càd tout le contenu du Global Environment. La commande à utiliser est la suivante :
Vous pouvez configurer RStudio pour effectuer une sauvegarde automatique du Global Environment, chaque fois que vous le quittez. Pour cela, il faut utiliser le menu Tools > Global Options..., cochez “save worksapce on .RData on exit” de la rubrique “R General”.
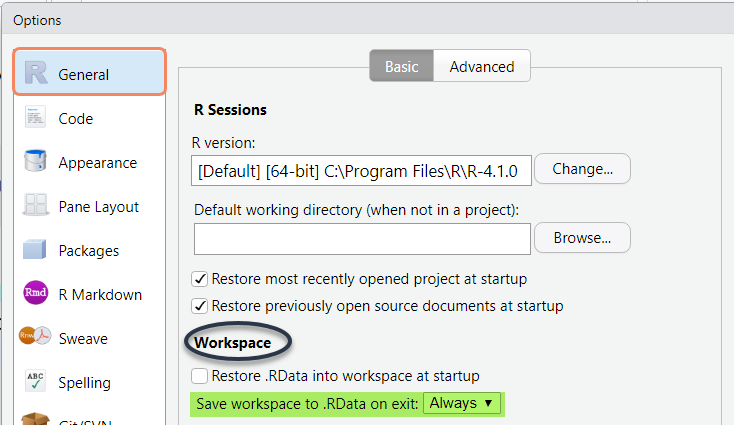
Vous pouvez aussi cocher l’option “Restore .RData into Workspace at startup” pour charger le dernier worksapce sauvegardé, mais sachez que cette pratique n’est pas conseillée.
2.6 Packages
L’installation par défaut du logiciel R contient le cœur du programme ainsi qu’un ensemble de fonctions de base. Mais ce R de base peut facilement être étendu en installant des extensions (packages, en anglais). Cette extensibilité est l’un des points forts de R. Toute personne peut facilement contribuer au développement de ce langage en proposant son propre package qui ajoute des fonctionnalités supplémentaires à R. Ces extensions sont déposées sur des serveurs (sur internet) de telle sorte que tout utilisateur de R puisse les installer et les utiliser gratuitement et librement.
Le principal (et official) dépôt des packages R est CRAN (Comprehensive R Archive Network), mais d’autres dépôts existent telles que Bioconductor et GitHub. Par la suite nous allons uniqument utiliser CRAN.
Voici les packages qui sont automatiquement chargé au début de chaque session R
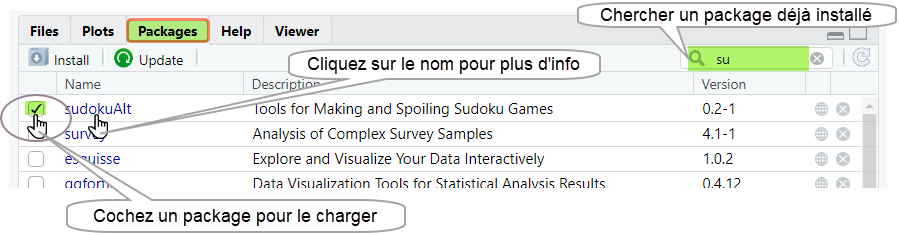
[1] "datasets" "utils" "grDevices" "graphics" "stats" "methods" Si vous identifiez un package qui n’est pas dans cette liste et que vous souhaitez utiliser une de ces fonctionnalités, alors il faudra d’abord l’installer sur votre machine. Pour installer un nouveau package (à partir du CRAN), il suffit d’utiliser la fonction install.packages() ou, plus simple, via l’onglet Packages de RStudio (quadrant bas-droite). Cliquer sur Install et indiquer le nom de l’extension dans le champ Package.

R va alors télécharger l’ensemble des fichiers nécessaires sur le disque dur de votre ordinateur dans l’emplacement indiqué par “Install to Library” (voir image ci-dessus).
À titre d’exemple, nous vous invitons à installer le package sudokuAlt en suivant la démarche indiquée ci-dessus. sudokuAlt permet de jouer au Sudoku sur R. À la fin de la procédure, vous devez avoir un message qui s’affiche dans la Console.
...
package ‘sudokuAlt’ successfully unpacked and MD5 sums checked
The downloaded binary packages are in ...La liste de tous les packages installés sur votre machine apparaissent dans l’onglet Packages de Rstudio. Vous pouvez obtenir plus d’information à propos d’un package déjà installé en clickant sur son nom dans la liste.
Pour pouvoir utiliser un package, il faut le charger (l’appeler). Pour cela, il suffit de taper library(<nom.package>) ou require(<nom.package>), où “nom.package” est le nom du package à charger. Par exemple, pour utiliser sudokuAlt, il faut taper
Vous pouvez aussi charger un package en cochant son nom dans la liste des packages disponibles via l’onglet Packages de Rstudio, comme indiqué dans la capture d’écran ci-dessus.
Maintenant que le package est installé et chargé, nous pouvons commencer à l’utiliser. Par exemple, nous allons jouer au Sudoku. Pour cela tapez
Si vous tapez ?makeGame, vous obtiendriez la fiche d’aide de cette fonction, dans le titre vous devez remarquer son nom suivie par “sudokuAlt” entre accolades pour indiquer l’appartenance de makeGame à sudokuAlt. Maintenant, si vous voulez résoudre le Sudoku que vous avez générez, tapez g |> solve() |> plot().
On peut décharger un package en utilisant la fonction detach(), ou, via l’onglet Packages de RStudio, en décochant son nom de la liste des packages disponible.
Il est important de bien comprendre la différence entre installer un package et le charger :
- La première consiste à chercher le package sur internet et l’installe en local dans un dossier du disque dur. Cette opération est à effectuer une seule fois et nécessite une connexion à internet.
- La seconde lit le dossier du package sur le disque dur et le met à disposition de R. Cette opération est à exécuter à chaque début de session (si vous voulez utiliser le package).
Pour voir quels packages sont chargés dans une session R, vous pouvez taper la commande search(), ou allez sur l’onglet Environnement et cliquez la flèche à côté de “Global Environnement”.

Note
Il est possible d’utiliser une fonction d’un package sans avoir à le charger entièrement. Pour cela, on utilise l’opérateur ::, en écrivant <nom_du_package>::<nom_de_la_fonction>. Par exemple : sudokuAlt::makeGame(). Cette méthode est utile lorsque le package est volumineux et que vous ne souhaitez utiliser que quelques fonctionnalités spécifiques.